클러스터 안의 노드가 문제가 있는 경우, 어떻게 동작할지 모르며 클러스터의 파일시스템 자원에 접근이 가능하다면 데이터 무결성을 손상시킬 수 있다. 이것을 막기 위해 문제가 있는 경우 해당 노드가 클러스터 리소스에 접근하는 것을 제한하는 외부 방법이 필요하다. 이것이 Fencing 이다.
Fencing의 방법은 여러가지가 있는데, 그중 서버를 꺼버리는 행위는 가장 간단하다. 죽은 노드는 확실하게 아무것도 할 수 없기 때문이다. 또 다른방법으로, 문제있는 노드를 네트워크/스토리지에서 분리하는 "작업의 조합"으로써 Fencing을 할 수도 있다. 네트워크에서 분리하는 이유는 새로운 리소스가 해당 노드로 가지 않게 하려는 것이며, 스토리지에서 분리하는 것은 문제있는 노드가 공유디스크에 쓰기를 하지 못하게 하기 위한 것이다.
Fencing은 클러스터에서 서비스와 리소스를 Recovery하는 매우 중요한 신호이며, 일반적인 절차이다. (서버가 꺼졌다고 난리를 피울 필요가 없다) Red Hat High Availability Add-on은, 응답없는 노드가 클러스터에 의해 Fencing 당하기 전까지는 해당 노드에서 리소스를 시작하지도 않고 서비스를 리커버리 하지도 않는다.
클러스터에서 Fencing이 올바르게 구성되면, 클러스터 내의 모든 노드가 다른 모든 노드를 Fencing 할 수 있어야 한다. 또한, 레드햇의 지원을 받으려면 클러스터의 모든 클러스터 노드가 Fencing을 받을 수 있도록 구성해야 한다.
* Fencing과 관련된 클러스터 시나리오
Fencing이 없는 상태에서 발생할 시나리오
3노드 클러스터 (노드1,노드2,노드3)이 Fencing없이 구성되어 있다. 노드1은 공유디스크에서 ext4 파일시스템 리소스를 마운트하였고, 웹서버 리소스가 해당 파일시스템에서 index.html등의 파일을 불러와 웹서비스를 수행한다. 갑자기 노드1 클러스터 네트워크 상에서 응답을 멈추는 문제가 발생하였다.
1. 노드2는 빠르게 파일시스템 체크를 수행한 후, 해당 공유 스토리지를 마운트한다.
2. 노드2는 웹 서비스를 시작한다.
3. 노드1이 갑자기 정상화되었고 마운트되어있는 파일시스템에서 쓰기를 시작한다. 현재 이 파일시스템은 노드2도 마운트 되어있다.
4. 파일시스템 손상이 발생한다. (ext4는 두군데 이상에서 마운트하고 쓰기가 발생하면 데이터 손상이 일어난다)
Fencing이 있는 상태에서 발생할 시나리오
3노드 클러스터 (노드1,노드2,노드3)이 Fencing없이 구성되어 있다. 노드1은 공유디스크에서 ext4 파일시스템 리소스를 마운트하였고, 웹서버 리소스가 해당 파일시스템에서 index.html등의 파일을 불러와 웹서비스를 수행한다. 갑자기 노드1 클러스터 네트워크 상에서 응답을 멈추는 문제가 발생하였다.
1. 클러스터는 노드1을 스토리지로부터 제거한다. (Fencing)
2. 노드2는 빠르게 파일시스템 체크를 수행한 후, 해당 공유 스토리지를 마운트한다.
3. 노드2는 웹 서비스를 시작한다.
4. 노드1이 정상화 되었으나 파일시스템은 마운트 할 수 없다. 또는, 노드1이 리부팅되었고 깨끗하게 되어 다시 클러스터에 들어가서 대기하게 된다.
* Fencing 방법
Fencing은 두가지 주요 방법이 있다. Power Fencing, Storage Fencing. 두 방법은 Power switch나 virtual fencing daemon 같은 fence device가 필요하다. 그리고 클러스터와 Fencing device간의 통신을 활성화 하기위한 Fencing agent 소프트웨어가 필요하다. 실제로 특정 노드에 Fencing을 해야 하는 경우, 클러스터는 Fence agent에게 이 임무를 위임한다. Fence agent는 Fence device에 통신하여 작업을 수행하도록 한다.
Power Fencing
서버의 전원을 차단하는 방법이다. 이 방법은 STONITH라고도 불리며, Shoot The Other Node In The Head의 줄임말이다. 파워 펜싱에는 두가지 종류가 있다. 또한 파워 펜싱은 서버를 끄거나 켜는 등 여러가지 방법으로 서버를 컨트롤 할 수 있다. 서버가 껐다 켜지면 클린한 상태가 되며, 클러스터 서비스가 enable 되어있다면 리부팅후 다시 자동으로 클러스터에 조인하게 된다.
1. 서버 외부에서 제어되는 네트워크 멀티탭 같이 전원차단 기능이 있는 하드웨어
2. 서버 내부에 전원을 차단하는 IPMI (예: iLO, DRAC, IPMI) 또는 가상 머신 Fencing Device 등
아래는 1번의 예시이다. 1번의 경우 일반적으로 서버는 파워 서플라이가 2개이상이므로, 모든 파워서플라이가 꺼지도록 설정해야 한다. 잘못 설정하는 경우, 실제로는 펜싱이 되지 않았는데 겉으로는 펜싱이 된 것처럼 보여 큰 문제가 발생할 수도 있다.
Storage Fencing
서버를 스토리지에서 연결을 해제하는 펜싱 방법이다. 이것은 SCSI reservation을 쓰거나 FC 스위치의 포트를 닫는 등의 방법으로 구현한다. 파워 펜싱 없이 스토리지 펜싱만 쓰는 경우, 해당 서버가 클러스터에 다시 조인되는지는 관리자가 확인해야만 한다. 사실 일반적으로 파워 펜싱을 사용하며 스토리지 펜싱을 사용하는 것은 드물다. 아래는 멀티패스를 사용하는 FC 스토리지를 사용하여 스토리지 펜싱을 수행하는 예시이다.
* Fence agent의 종류 (자주 사용하는것만)
- Hareware Management Fencing : 서버 관리 툴 (iLO, iDRAC, IPMI 등) 을 통해 사용하는 Fencing
- Virtual Mahine Fencing / Libvirt Fencing : 가상머신(VMWare, KVM 등의 하이퍼바이저) 를 통해 사용하는 Fencing
- Cloud instance fencing : 클라우드 종류에 따라, 예를들어 알리바바, AWS, AZURE등에서 사용할 수 있는 Fencing agent 들이 있다.
* Fence 여러개 조합하기
Fence는 하나만 사용하는것이 아닌 여러개 사용이 가능하다. 위에서 소개한 파워 펜싱, 스토리지 펜싱을 함께 쓸 수도 있다. 여러개의 펜싱 조합은 서로 백업으로써 작동할 수 있다. 펜싱도 실패할 수 있기 때문이다. 예를들어 첫번째로 파워 펜스를 수행하고, 실패한다면 스토리지 펜스를 수행하게 할 수도 있다.
* Fence Agent 에 대해 알아보기
Red Hat High Availability Add-on은 여러가지 펜스 장치를 지원하는 Fence agent들을 제공한다. 실제 사용하는 Fence Device를 지원하는 Fence agent를 설치하여 Fence를 구성하면 된다. fence-agents-all 패키지를 설치하면 레드햇에서 제공하는 대부분의 Fence Agents를 설치할 수 있다. 그러나, 모든 fecing agent를 싹다 모은것은 아니다. 또한 그중 몇가지는 수동으로 설치해야 한다. 더 많은 정보는 다음을 참고한다. https://access.redhat.com/articles/2912891
Fence Device와 Fence agents 각각 종류에 따라 모두 요구되는 파라미터가 다르다. 공통되는 파라미터도 있지만 각각 파라미터가 다르므로 미리 확인이 필요하다. 각각의 Fence agent들은 명령어들처럼 쓸 수도 있다. 추가적으로, 모든 fencing agents은 /usr/sbin/fence_* 에서 확인할 수 있다.
명령어1 : 설치된 fence agent 정보 확인하기 - pcs stonith list
[root@node ~]# pcs stonith list
fence_amt_ws - Fence agent for AMT (WS)
fence_apc - Fence agent for APC over telnet/ssh
fence_apc_snmp - Fence agent for APC, Tripplite PDU over SNMP
fence_bladecenter - Fence agent for IBM BladeCenter
...output omitted...
명령어2 : Fence Agent의 상세 정보 확인하기
pcs stonith describe [Fence agent 이름] (--full 옵션을 추가하여 아주 상세히 볼 수 있다)
위와 같이 해당 에이전트는 어디에 사용하는지도 설명이 나오며, ip는 필수적으로 필요하고, port는 옵션으로 필요하다는 것을 알 수 있다.
명령어3 : Fence Agent의 상세 정보 확인하기 - man 사용, fence 에이전트 자체 사용
- man [Fence agent 이름]
- [Fence agent 이름] -h
명령어4 : Fence Agent를 명령어로써 사용하기
fence_ipmilan은 아래와 같은 명령으로 Fence를 수행할수도 있다.
Fence Device 만들기
클러스터에서, pcs stonith create 명령으로 Fence Device를 생성할 수 있다. 기본 형식은 다음과 같다.
- name : STONITH fence device의 이름. pcs status 등 상태 확인 명령에서 나오는 이름이다.
- fencing_agent : fence device에 의해 사용될 fencing agent의 이름.
- fencing_parameter : fencing agent에 사용할 요구되는 파라미터들.
* Fence 관련 여러 명령어들
설정된 Fence device의 현재 상태 보기
pcs stonith status 명령 : 클러스터에서 구성된 fence device, 사용되는 fencing agent, fence device 상태를 보여준다. fence device의 상태는 started와 stopped 두가지가 있다.
- started : 해당 device는 작동중인 상태
- stopped : 해당 fence device는 작동하지 않는 상태
설정된 Fence device의 정보 보기
pcs stonith config 명령 : 모든 STONITH 리소스의 configuration option들을 보여준다. 특정 STONITH 리소스 이름을 줘서 해당 리소스의 configuration option만 볼수도 있다.
설정된 Fence device 속성값 변경하기
pcs stonith update fence_device_이름 : fencing device의 옵션을 변경할 수 있다. 이 명령은 새로운 fencing device 옵션을 추가하거나, 원래 있는 값을 변경할 수 있다. 예를들어, fencing device 인 fence_node2가 node2 대신 node1를 펜스해버렸다. 이경우, 아래 명령으로 바로잡을 수 있다.
설정된 Fence device 삭제하기
어떤 시점에서는 클러스터에서 fencing device를 제거해야 할 수 있다. 이는 해당 클러스터 노드를 삭제하거나, 노드를 펜스하기 위해 다른 펜스 매커니즘을 사용하기 위해 사용할 수 있다. pcs stonith delete Fence_device_name 명령으로 수행한다.
* fence 구성 테스트하기
- 구성된 fencing 설정이 잘 작동하는지 두가지 방법으로 확인할 수 있다.
1. pcs stonith fence 노드명
- 이것은 요청한 노드를 펜스시킨다.
- 사용자는 fence 시키고 싶은 노드에서 하는게 아니라, 다른 노드에서 이 명령을 사용해야 한다 (should)
- 만약 이 명령이 성공하면, 해당 노드는 펜스된다.
2. 한 노드를 네트워크 케이블을 뽑거나 방화벽에서 포트를 닫거나, 전체 네트워크 스택을 비활성화여 노드에서 네트워크를 비활성화한다.
- 그러면 클러스터의 다른 노드는 해당 노드가 장애라는것을 확인하고 펜스를 해야 한다. (should)
- 이는 실패한 노드를 감지하는 클러스터의 기능도 테스트합니다.
* Fence agent 의 파라미터
Fence agent 의 파라미터는 크게 일반 파라미터와 전용 파라미터 두가지 범주가 있다. 일반 파라미터는 대부분의 Fence agent가 모두 동일하게 사용하며, 전용 파라미터는 Fence agent 마다 각각 다른 파라미터이다. 파라미터부터는 이해가 잘 안될텐데, 자주 사용하는 Fence agent의 파라미터의 예시를 보면서 이해하면 도움이 된다.
<일반 파라미터>
아래는 자주 사용하는 일반 파라미터이다.
pmk_host_list
- 이 매개변수는 fencing device에 의해 제어되는 node 들의 리스트를 스페이스로 구분한 리스트를 제공한다.
Knowledgebase: "What format should I use to specify node mappings to stonith devices in pcmk_host_list and pcmk_host_map in a RHEL 6, 7, or 8 High Availability cluster?"
모든 서버마다 BMC가 있거나 가상으로 구현할 수 있다. 각 BMC는 IP, ID, PW를 가지고 있다. 이 정보로 fence 를 생성한다. 또한 각 서버의 관리 툴에서 ipmi over lan 옵션을 활성해야 할 수도 있으므로 참고할 것.
BMC를 사용하지 않는 경우, 여러가지 하드웨어 디바이스들이 있다. 이 장치들은 장치마다 구성 방법이 있으므로 따로 참고해야 하며, 이 예시에서는 BMC를 사용한 fence_ipmilan 에이전트를 예시로 든다.
• Uninterruptible power supplies (UPS)
• Power distribution units (PDU)
• Blade power control devices
• Lights-out devices
Fence 구성 명령
이 예시에서는 fence_ipmilan 이라는 에이전트를 예시로 들며, 각각 노드마다 fence 장치를 생성해야 한다. 따라서 총 3개를 만든다. pcs stonith create명령을 사용한다.이 커맨드는 클러스터 노드를fence할 수 있는fence agent에 의해 요구되는 파라미터의 세트와value값을 요구한다. fence agent인fence_ipmilan의 파라미터는pcmk_host_list, username, password, ip가 요구된다. pcmk_host_list파라미터는 클러스터에 알려진 해당 호스트를 나열한다. ip매개변수는 펜싱 장치의IP주소 또는 호스트 이름을 요구한다.
구성된 Fence 상태 확인
pcs stonith status명령은 클러스터에 연결된fence장치의 상태를 보여준다. 모든fence_ipmilan펜스 장치는started로 보여야만 한다.
만약 하나 이상의fence장치가stopped되어있는 경우,대부분fence agent와fencing server간 커뮤니케이션의 문제이다. "pcs stonith config펜스장치"명령으로fence device의 세팅을 확인한다.또한pcs stonith update명령으로 펜스장치를 업데이트할 수 있다.
실제로 fence를 수행하여 잘 작동하는지 확인
아래 두가지 방법으로 Fence 를 수행해볼 수 있다. 이미 Fence가 구성되었다면 첫번째 방법으로, 구성되지 않았다면 두번째 방법으로 할 수 있다. 아래 두번째 캡쳐는 위 정보와 맞지 않은데, 이런 형식으로 하면 된다는 것을 얘기하는 것이다.
Fence가 성공되었다면 해당 서버는 종료되며, 다시 부팅된다. 부팅되고 다시 클러스터에 조인하게 된다. (enable 설정 했을 시)
동일한 한가지 작업을 여러대의 컴퓨터가 세트가 되어 일하는 것. 러스터에 목적은, 운영하는 서비스가 Single Point Failure 의 영향을 가능한 받지 않게 하려는 것이다. 클러스터 내에 있는 컴퓨터들은 각각 node 라고 하며, 이들은 서로를 모니터링한다. node 또는 서비스에 문제가 있을 시, 정상적인 node에 서비스를 이동시켜 가능한 한 서비스 운영의 downtime을 최소화 시킨다.
이러한 전략은 하나의 서버가 가능한 한 uptime을 오랫동안 유지하도록 하는 것과는 다른 전략이다. 사실 uptime은 실제 엔드유저에게는 크게 중요하지 않으나, 서비스의 가용성은 엔드유저에게 중요하다.
* High Availbility 클러스터 방식
시스템 관리자는 서비스 요구사항과 하드웨어 사용 가능량 (비용)에 따라 최적화된 클러스터 구성을 결정해야 한다. 클러스터 구성을 계획할 때 가장 중요한 질문은 다음과 같다. "해당 서비스를 클러스터에 넣으면 가용성이 증가하는가?" 클러스터 구성은 2가지 방식을 가진다.
1. Active-Active Cluster
- 여러 노드에 하나의 동일한 서비스가 올라간다. 이 경우 한 노드가 죽는다 하더라도 다른 노드가 살아있다.
- 서비스는 다른 살아있는 노드에서 수행하므로 문제가 없고, Fail된 노드가 회복되면 다시 클러스터는 워크로드를 전체 노드에 분배한다.
- 이러한 타임의 클러스터의 주요 목표는 로드밸런싱으 수행하고, 높은 부하를 컨트롤하기 위해 많은 인스턴스를 확장하는 것이다.
- 다만 로드밸런싱을 위해 따로 로드밸런서가 필요하다.
- Active-Active 클러스터는 2개 이상의 클러스터 노드에서 사용할 수 있다.
2. Active-Passive Cluster
- 하나의 서비스가 하나의 노드에만 올라간다. 만약 하나의 노드가 Fail되면, 그때 클러스터는 다른 정상 노드에 해당 서비스를 올린다.
- 이 방식은 문제있는 노드가 클러스터 리소스에 접근해서 데이터 무결성을 깨뜨릴 수 있어, Fencing이라는 정책이 필요하다.
- 참고로 이 과정은 Activce-Passive 클러스터 구성에 포커스를 맞추고 있다.
* 클러스터의 구성요소 및 용어
리소스 / 리소스 그룹
work의 기본 단위를 리소스라고 표현한다. 여기서 work 기본 단위란, 실행하는 어플리케이션, 파일시스템, IP주소 등 모든 것이 리소스가 된다. 리소스 그룹은 관계 있는 리소스들은 하나로 묶는 것이다. 예를들어 웹 서비스를 제공하려면 접속할IP, 웹서비스, 웹페이지가 저장될 파일시스템 등이 필요하다. 이런 관계 있는것들은 하나의 노드에서 실행되어야하므로 리스소 그룹으로 묶어 하나의 노드에서 해당 그룹이 실행되도록 한다.
Failover
클러스터에 올라간 리소스에 문제가 있는경우, 해당 리소스를 다른 노드로 마이그레이션한다. 이러한 방식으로 클러스터가 운영된다.
Fencing
클러스터 내에서 가장 안전하게 지켜야 하는것은 데이터이다. 여러 노드에서 한 파일시스템에 접근을 시도하면 데이터 무결성 문제로 파일시스템이 깨지게 된다. 이것을 막기 위해 Fencing 이라는 방식이 있으며, 크게 서버의 전원을 끄거나 스토리지 연결을 끊는 방식이 있다. 서버 전원을 끄는 방식을 일반적으로 많이 사용한다. 노드에 문제가 생기면, 문제는 너무나 많은 종류가 있고 다 추측할 수 없다. 따라서 리소스에 문제가 있다고 판단되면 단순하게 Fencing을 수행해서 리소스를 다른 노드로 마이그레이션한다.
Quorum
클러스터의 무결성을 유지하기 위해 필요한 투표 시스템이다. 클러스터 노드에 문제가 생기면, 의사결정을 할 노드가 누가 될지를 결정하는데, Quorum으로 결정을 한다. 모든 노드는 투표수를 1개씩 가지며, 전체 노드 수에 기반하여 과반수 이상의 투표 수를 가진 노드의 그룹이 Quorum을 얻게 된다. Quorum을 얻지 못한 노드 (과반수가 아닌 노드)는 모두 Fencing된다. 만약 클러스터가 Quorum을 얻지 못한 상태라면, 어떠한 리소스도 시작되지 않으며, 실행된 리소스들은 중지된다. 예를들어 5노드 클러스터에서 3노드가 응답이 없고 2노드만 투표하면 그 클러스터는 Quorum을 잃게 되는 것이다.
* 클러스터 네트워크/하드웨어 아키텍쳐
클러스터 구성을 위해서는 아래와 같이 복잡한 구성이 필요하다. 아래는 5노드 클러스터의 일반적인 구성이다. 파란색은 IP 네트워크이며, 녹색은 SAN 네트워크(iSCSI, FCoE도 가능)이다. 하늘색은 상황에 따라 다른데, 아래 예시에서는 IP 네트워크이다.
- 왼쪽 Public Network 는 일반 사용자들이 접근하는 네트워크로, 외부에서 접근하는 공개적인 네트워크이다.
- 오른쪽 Private Network 는 엄격하게 비공개되어야 하며, 절대 외부에서 접근하지 않도록 해야 한다.
- Private Network 의 Ethernet Switch는 노드간 통신하는 경로로, Heartbeat 가 포함된다.
- Power Control은 전원을 끄는 Fencing에 필요한 것으로, 서버 전원을 끄기 위해 IPMI를 사용하여 서버 전원을 종료한다.
일반적인 서버 벤더는 전용 IPMI 관리툴이 있다. (Dell/iDRAC , HP/iLO 등)
* 클러스터 소프트웨어 구성요소
클러스터 소프트웨어는 Red Hat Enterprise Linux Add-ON : High Availability 에서 제공된다. 클러스터는 아래와 같이 여러 소프트웨어 데몬/컴포넌트들이 연계되어 작동한다.
Corosync
클러스터 노드간 통신을 핸들링하기 위해 페이스메이커에 의해 사용되는 프레임워크이다. corosync는 Pacemaker의 멤버십 및 쿼럼 데이터 소스이기도 하다.
Pacemaker
모든 클러스터에 관련된 활동에 대한 책임을 가지는 컴포넌트이다. 클러스터 멤버쉽을 모니터링하고, 서비스와 리소스를 관리하고, 클러스터 멤버를 fencing 한다. pacemaker RPM 패키지는 아래 3가지 중요 기능이 포함된다.
Cluster Information Base (CIB)
CIB는 클러스터와 클러스터 리소스들의 구성과 상태 정보를 XML 포맷형태로 포함한다. 클러스터 안에 있는 하나의 클러스터 노드는 DC(Designated Coordinator)로 행동하도록 페이스메이커에 의해 선택되며, 또한 모든 다른 노드에 싱크되는 클러스터/리소스 상태와 클러스터 구성을 저장한다. 스케줄러 (pacemaker-schedulerd)는 CIB의 컨텐츠를 사용하여 클러스터의 이상적인 상태와 어떻게 그 상태에 도달할지에 대해 계산한다.
Cluster Resource Management Daemon (CRMd)
클러스터 리소스 관리 데몬은 모든 클러스터 노드에서 실행되는 LRMd(Local Resource Management Daemon)에다가 리소스의 시작/종료/상태 체크 action을 조정/전송 한다. LRMd는 CRMd에게 받은 Action을 resource agents에게 전달한다.
Shoot the Other Node in the Head (STONITH)
stonith는 fence 요청을 처리를 담당하는 시설이며, 또한 해당 요청 액션을 CIB 안에 구성된 fence 장치에게 보낸다.
Pcs
pcs RPM 패키지는 두개의 클러스터 구성 툴을 포함한다. pcs 명령어는 커맨드 라인 인터페이스를 제공한다. 이것으로 pacemaker / corosync 클러스터의 모든 부분을create/configure/control 할 수 있다. pcsd 서비스는 클러스터 구성 동기화를 제공하며, 또한 pacemaker/corosync 클러스터를 create/configure 하도록 하는 웹프론트엔드를 제공한다.
* 클러스터 요구사항 및 조건
클러스터의 요구사항 및 조건은 매우 중요하며, 가능하면 클러스터 설정, 네트워크 아키텍쳐, 펜스 구성 같은 관련 데이터를 레드햇 support로 전송해서 검토받을 수 있다. 주요 고려사항은 다음과 같다.
1. 노드 개수
2. 클러스터의 네트워크 범위 (같은 네트워크 대역이 아닌 거리적으로 먼 거리 등)
3. Fence 장치
4. 노드의 가상화/클라우드 환경
5. 네트워크 구조
6. selinux
* 장애 조치 계획
모든 하드웨어는 결국엔 장애가 발생한다.. 하드웨어 수명 주기는 주 단위에서 연 단위까지의 범위를 가진다. 게다가 거의 모든 소프트웨어는 버그가 있다. 어떤것은 눈에 띄지 않지만, 다른것들은 전체 데이터베이스를 손상시킬 수도 있다.
시스템 관리의 주요 TASK 중 하나는 이런 문제가 발생할 것을 알고, 그에 따라 계획하는 것이다. 클러스터는 많은 Single Point of Failure (SPOF) 를 가진다. 이를 하드웨어단에서, OS 단에서, 인프라단에서, 소프트웨어단에서 이중화를 통해 막을 수 있다.
아래는 완전한 목록은 아니지만 일반적인 문제들이다.
• Power supply - > 파워 이중화
• Local storage -> 레이드 구성
• Network interfaces -> 네트워크 포트 본딩
• Network switches -> 스위치 이중화
• Fencing software -> Fence 이중화
• User data -> 정기적인 외부 백업
* References
pcs(8) man page For more information, refer to Chapter 2.
For more information, refer to the High Availability Add-On Overview chapter in the Configuring and managing high availability clusters guide at
Knowledgebase: "How can Red Hat assist me in assessing the design of my RHEL High Availability or Resilient Storage cluster?" https://access.redhat.com/articles/2359891
RHEL HA ADD-ON은 요구되는 소프트웨어 패키지 모음과 방화벽 설정, 그리고 노드 인증이 필요하다. 추가적으로, RHEL8과 RHEL7 클러스터 노드는 호환되지 않는다. 페이스메이커 클러스터에 있는 모든 노드들은 동일한 메이저 버전의레드햇 리눅스를 써야만 한다. (마이너 버전 얘기는 없음) 커뮤니케이션을 위해 RHEL8은 corosync 3.x를 쓰며, RHEL7은 corosync 2.x를 쓴다.
노드에 필요한 소프트웨어 설치
클러스터 구성 소프트웨어는 pcs 패키지이다. pcs 패키지는 corosync와 pacemaker 패키지를 필요로한다. yum으로 pcs 설치시 corosync와 pacemaker는 dependency로 자동으로 설치된다. fencing agents는 각각 클러스터 노드에 설치되어야 한다.
fence-agents-all 패키지는 모든 사용가능한 fancing agent 패키지를 당겨온다. 관리자는 fence-agents-all을 할지 아니면 fence-agents-XXX 패키지만 설치할지 선택해야 한다. 여기서 XXX는 fence 에이전트 종류에 따른 이름이다. pcs와 fence-agents-all(또는 다른 fence agent) 패키지는 모든 클러스터 노드에 설치되어야 한다.
클래스룸 환경은 서버를 IPMI OVER LAN을 통해 전원끄기/켜기/재시작 할 수 있는 BMC를 포함한다. 클러스터에서 BMC를 사용하기 위해서는 fence-agents-ipmilan 패키지를 모든 클러스터 노드에 설치해야 한다.
클러스터 통신을 위한 방화벽 설정
모든 클러스터 노드의 방화벽에서 클러스터 통신을 위해 방화벽을 해제해야 한다. rhel8의 기본 방화벽은 firewalld이며, 방화벽 데몬은 클러스터 통신을 허용하기 위해 High-Availability 이라는 표준 서비스와 함께 제공됩니다. high-availability 방화벽 서비스를 각 노드에서 허용하기위해서는 아래와 같이 한다.
Pacemaker와 Corosync를 각 노드에서 활성화하기
pcsd 서비스는 클러스터 구성 동기화와 클러스터 구성을 위한 웹 프론트엔드를 제공한다. 이 서비스는 모든 클러스터 노드에 있어야 한다. systemctl을 사용하여 pcsd를 활성화한다. 모든 클러스터 노드에서 한다.
클러스터 커뮤니케이션을 위한 유저 설정
pcsd는 클러스터 커뮤니케이션과 구성을 위해 hacluster라는 유저를 사용한다. 레드햇은 클러스터 내의 모든 노드의 hacluster 유저가 동일한 비번을 쓰기를 권고한다. 아래처럼 비번을 redhat으로 구성할 수 있다.
클러스터 노드 인증
pcsd 서비스 내에서 클러스터 노드를 인증해야 한다. 이 인증을 위해 hacluster 계정과 패스워드를 사용한다. pcs host auth 명령어로 클러스터 내의 모든 노드를 인증하기 위해서, 노드 중 하나의 노드에서만 아래 명령어를 실행하면 된다. 자동화를 목적으로 -u 유저명 , -p 패스워드 옵션을 사용할수도 있다.
High Availability Cluster는 구축 전 기본적인 네트워크 구성이 필요하다. 아래 예시가 가장 기본 네트워크이며, 해당 교육과정 수업시 실습을 위해 기본적으로 구성되는 Lab 시스템이다. 해당 네트워크 구성을 이해해야 기본적인 수업이 가능하다.
* 기본 네트워크 구조
workstation
핸즈온 메인으로 사용하는 컴퓨터. 실제 시험장에서 내가 직접 사용하는 물리적 PC라고 생각하면 된다. GUI이며, 항상 여기에서 먼저 로그인을 한다. 여기서 모든 다른 VM에 SSH로 연결할 수 있다. standard 유저 계정을 가지며, student / student 계정이다. student는 필요한 경우 root가 될 수 있다. 어떠한 작업도 root로 다이렉트로 로그인하는것을 요구하지 않는다. 하지만 만약 필요하다면 비번은 redhat 이다.
nodea / nodeb / nodec / noded
실제 클러스터 구성과 실습을 수행하는 서버들이다. workstation과 동일한 권한을 가진 계정인 student / student 를 가진다. 모든 VM은 lab.example.com DNS 도메인을 가진다. (172.25.250.0/24) 그리고 그 다음에는 3개의 다른 네트워크가 있다.
private.example.com (192.168.0.0/24) : private 클러스터 커뮤니케이션으로만 사용한다.
private.example.com 은 클러스터 인프라에 있어 아주 중요하다. 왜냐면 이 네트워크가 fail되면 전체 클러스터가 fail 되기 때문이다. 이 때문에, 레드햇은 production에서는 클러스터 회복력을 높이기 위해 네트워크 이중화를 사용하도록 권고한다.네트워크 이중화는 이후 코스에서 설명한다.
bastion
bastion 시스템은 항상 실행중이어야만 한다. bastion 시스템은 사용자의 lab machine과 classroom 네트워크에 연결하는데 있어 router처럼 작동한다. 만약 bastion이 죽으면, 다른 lab machine들은 제대로 작동하지 않거나 부팅중 hang이 발생할 수 있다.
기타 서버들
몇몇 서버들은 support service를 하는 시스템이 classroom에 있다. content.example.com / materials.example.com 이 둘은 핸즈온 활동에서 사용되는 소프트웨어와 material이 있다. (이부분은 실제 공부에서는 중요하지 않다) 또한 iSCSI와 NFS를 제공하는 스토리지 서버인 storage.lab.example.com 도 제공된다. 이 스토리지는 매우 중요하지만 실습을 위해 구축하는 방법은 따로 이 수업에서 제공되지 않는다.
* 서버 역할 및 IP 표
- 아래는 classroom 환경에서 사용되는 여러 머신들을 ip와 역할들을 포함하여 표로 만든 것이다.
* Fencing 환경
fencing은 클러스터에서 중요한 부분이다. 자세한 설명은 이후 코스에서 하겠지만, 간단히 정의하면 문제있는 클러스터 노드가 클러스터 자원에 엑세스하는것을 제한하기 위한 것이다. 우선 중요한 것은 네트워크 측면에서의 Fencing 설명이며, 이 부분만 설명한다. 이 코스에서는 두가지 다른 fencing 방법이 사용된다. Fence은 최소 하나 이상 구축해야 하며 아래 예시 둘 중 하나만 사용해도 되고, 둘다 사용해도 된다. 그 외 여러가지 다른 종류가 많고 다른것을 사용해도 상관없다.
fencing 방법1 - BMC
이 방법은 실제로 프로덕션 레벨에서 사용할 때 가장 많이 사용하는 방법이며, 물리적 서버의 관리 포트를 사용하는 방법이다. 물리적 서버의 종류는 대표적으로 Dell, Lenovo, HP 등이 있고, 각 회사마다 다른 이름의 관리 툴을 사용한다. (iDRAC, xClarity, IMM, iLO 등) 이 툴들은 서로 다르지만 모든 기반은 BMC에 기반을 두고 있다.
가상머신은 Power 관리에 관련된 BMC(Baseboartd Management Controller) 가 없다. 래서 BMC 동작은 power 라는 machine 의해 시뮬레이트된다. 시뮬레이션된 BMC 메커니즘은 클러스터 노드에서 원격으로 모니터링 및 관리 작업을 수행한다. (BMC에서 펜싱을위한 파워 모니터링을 말하는것으로 보임) BMC 장치의 IP주소는 (192.168.0.101/102/103/104) 이며 각각 nodea/b/c/d 를 위해 사용된다. 이것은 power 에 의해 호스트된다.
BMC IP주소와 노드 이름은 classroom 환경이 생성될 때 할당된다. openstackbmc 서비스는 power 에서 power-managed cluster node 하나당 하나의 프로세스로 실행된다. (즉 4개의 프로세스가있음) 이 서비스는 해당 노드를 대신하여 IPMI (Intelligent Platform Management Interface)의 요청에 응답한다. 모든 BMC 장치에 대하여, 로그인 정보는 admin / password 이다.
Fencing 방법2 - Simulated chassis
이 과정에서 사용되는 두 번째 fencing 방법은 관리 섀시(예: ibmbblade, hpblade 또는 블레이드 센터)를 시뮬레이션 한다. 이 방법은 fencing 요청을 위해 chassis IP 한개만 필요하다.
이 fencing 방법은 각 클러스터 노드에 플러그 번호를 할당하는데 fence_rh436 커스텀 스크립트와 pcmk_host_map 파라미터를 사용한다. 노드를 펜스하라는 요청이 chassis IP (192.168.0.100)에 보내질 때, 플러그 번호가 포함된다. fence_rh436 스크립트는 이 요청을 Fencing through simulated BMC 방법 에게 IPMI call 로 변환시켜 보낸다.
이 classroom에서 power 머신은 fence 할 노드인 가상머신을 전원 종료하는 요청을 simulate chassis에서 수행하도록 한다.
* 클러스터 구성 환경 초기화 할 때 유의사항
classroom 환경을 재시작하는것은 모든 classroom node들 또는 특정 노드를 초기 상태로 돌리는 것이다. 리셋을 통해 가상머실을 초기화하고 lab을 다시 시작할 수 있다. 이슈가 생기거나 해결이 어려운 문제가 있을 때 빠르게 해결할 수 있는 방법이다. 이 classroom은 전체 또는 일부 환경을 초기화 할 때 제약조건이 있다.
대부분의 레드햇 트레이닝 코스에서 개별 시스템은 필요한 경우 하나하나 리셋이 가능하다. 그러나, 이 과정에서는 클러스터 노드를 하나만 리셋하면, 그 결과로서 해당 노드가 필요한 정보들을 잃게되고, 클러스터의 일부로서 통신하는것이 실패하게 된다. 그러므로 올바른 절차는 클러스터에서 해당 노드를 제거하고, 그 후에 재시작해야한다. 클러스터에서 노드를 제거하는것은 2가지 스탭으로 진행된다.
2. 노드가 클러스터에서 제거된 것을 반영하기 위해 fence 구성을 조정한다. (dedicated fence 장치를 삭제하거나 shared fence 장치를 수정한다.
노드를 재시작한 후에는 해당 노드는 다시 클러스터에 포함해야 한다. 즉, 모든 요구되는 패키지를 설치하고, 해당 노드를 클러스터 안에 권한을 넣고, 방화벽 포트를 열고, pcsd 서비스를 시작하고, 해당 노드가 클러스터의 일부가 되도록 구성도 해야한다.
* 클러스터의 노드들
일부 클래스룸의 VM들은 작업동안 수정되지 않으며, 시스템 문제가 발생하지 않는 한 전혀 리셋할 필요도 없다. 예를 들어, workstation 머신은 불안정해지거나 통신이 끊긴 경우에만 재설정해야 하며 자체적으로 재설정될 수 있다. 아래 표에는 재설정할 수 없는 머신과 필요한 경우 재설정할 수 있는 머신이 나열되어 있다. 만약 재설정을 해야하는 상황이 있다면, 온라인 환경에서, 선택한 머신을 클릭하고 ACTION -> RESET을 하면 된다.
참고할 사항으로, 만약 power 머신을 리셋한다면, fencing resouces들은 fail되거나 stop된다. 타임아웃이 되기 때문이다. 이 경우, 클러스터에서 이 리소스들을 다시 사용하는것을 enable 하도록 resources의 fail count를 꼭 reset 해줘야 한다. 이를 위해 아래 명령을 치면 된다. pcs resource cleanup my_resource
또한 original course build를 재생성하여 클래스룸 환경을 리셋할수도 있다. 이것은 문제가 완전히 꼬였을 때 사용한다. 문제를 해결하는것보다 코스를 재생성하는것은 빠르며, 일반적으로 몇분이 걸리며 깔끔하다. 온라인 환경에서 delete를 클릭하고, 기다렸다가 create 버튼을 누르면 된다.
ESXi 하이퍼바이저와 vCenter Server를 결합한 서버 가상화 제품에는 어떤 것이 있습니까?
* 설명
- "vSphere는 ESXi와 vCenter가 합쳐진 VMware의 서버 가상화 "제품"의 이름이다."
- VMware Certified Professional - Data Center Virtualization 2022 (VCP-DCV 022 / 2V0-21.20)
An IT department is experiencing random hardware failures that are costing the company money.
The CIO is looking for technical support beyond traditional break/fix with enhanced visibility and proactive insights into the environment at no additional cost.
IT 부서에서 무작위적인 하드웨어 장애가 발생하여 회사에 비용이 발생하고 있습니다. CIO는 추가 비용 없이 환경에 대한 향상된 가시성과 사전 예방적 인사이트를 통해 기존의 중단/수리를 넘어서는 기술 지원을 찾고 있습니다. CIO의 요구 사항을 충족하는 VMware 서비스는 무엇입니까?
* 영단어
- CIO (Chief Information Officer) : 기업 정보기술 시스템 총괄 관리 책임자
* 설명
- vRealize Operations Manager는 데이터를 결합하여 향후 수요를 예측하고 높은 리소스 사용률이 발생하는 시기와 위치를 결정합니다.
- VMWare skyline은 문제를 방지하는데 도움이 되는 예측 분석 및 사전 권장 사항을 제공한다.
- VMware Certified Professional - Data Center Virtualization 2022 (VCP-DCV 022 / 2V0-21.20)
Which solution can be used to automatically deploy a fully configured VMware software-defined datacenter (SDDC)?
완전히 구성된 VMware 소프트웨어 정의 데이터 센터(SDDC)를 자동으로 배포하는 데 사용할 수 있는 솔루션에는 어떤 것이 있습니까?
* 설명
- The VMware Cloud Foundation features provide automated deployment and life cycle management of your SDDC, and enable provisioning of customer virtualized workloads and containers.
관리자가 다른 가상 머신이 포함된 2TB 데이터스토어에 "Finance1"이라는 300GB 가상 머신을 배치합니다. 가상 머신 배치 후 데이터스토어에 200GB의 여유 공간이 생깁니다. 회계 부서에서 Finance1의 야간 스냅샷을 생성한 후 이전 스냅샷을 삭제합니다. 관리자는 스냅샷이 데이터스토어를 채우는 것에 대해 우려하고 있습니다. 다음 중 스냅샷과 관련하여 옳은 것은 어느 것입니까?
- If a virtual machine is running on a snapshot, it is making changes to a child disk. The more write operations made to this disk, the larger it grows, to an upper limit of the size allocated to the disk plus a small amount of overhead. This is true for each delta.
- Child disks are known to grow large enough to fill an entire datastore, but this is because the LUN containing the datastore was insufficiently large to contain the base disk, the number of snapshots created, and the overhead and .vmsn files created.
An administrator identifies a snapshot file named “Win10-000001-sesparse.vmdk” on a datastore.
Which type of information can be determined about this datastore?
관리자가 데이터스토어의 디스크 공간 부족 알람을 조사하라는 에스컬레이션을 받습니다. 관리자는 쓰기 집약적인 프로덕션 데이터베이스 서버에서 실수로 스냅샷이 생성된 것을 발견합니다. 스냅샷은 한 시간도 채 되지 않아 거의 1TB의 크기로 커졌고 매초마다 계속 증가하고 있습니다. 관리자는 스냅샷을 삭제하는 동안 어떤 동작을 예상해야 할까요?
* 영단어
- in less than ~ : ~ 안에 (1시간 안에) - briefly : 간략하게, 일시적으로
- Instant cloning is very convenient for large scale application deployments because it ensures memory efficiency and allows for creating numerous virtual machines on a single host.
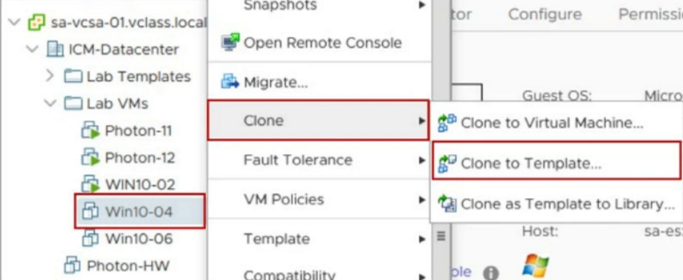
An administrator wants to create a master copy of an existing virtual machine (VM) named “TestApp” and deploy VMs from this master copy whenever a user requests one.
Which method can the administrator use to create a master copy of TestApp?
A. Deploy from an Open Virtual Machine Format (OVF) template
- 아래 그림처럼 새로운 정보가 기록되면 메모리에 COW 방식으로 새로운 Child마다 Unique Memory가 생성된다.
- VMware Certified Professional - Data Center Virtualization 2022 (VCP-DCV 022 / 2V0-21.20)
- There is a slightly higher provisioning time of the instant clone (21 seconds) compared to the linked clone (11 seconds) because of the requirement to mark all the memory pages of the parent as copy-on-write. - 인스턴트 클론의 프로비저닝 시간(21초)이 연결된 클론(11초)에 비해 약간 더 긴데, 이는 상위 클론의 모든 메모리 페이지를 [복사-온-쓰기]로 표시해야 하기 때문입니다. - https://williamlam.com/2018/04/new-instant-clone-architecture-in-vsphere-6-7-part-1.html (10페이지)
* 참고 : COW (Copy On Write) - 복사를 하는데, 복사 대상을 실제로 데이터를 복사하지 않고, 같은 위치를 가리킴. - 복사본이 수정되는 경우, 원본을 가리킬 수 없으므로 그때 새 리소스를 만드는 것. - 즉 리소스가 복제되었지만 수정되지 않는 경우 새 리소스를 만들지 않고 사본/원본이 리소스를 공유하고, 복사본이 수정되었을때만 새 리소스를 만드는 관리 기법이다.
Refer to the exhibit.
Which two statements are true regarding the state of the virtual machine (VM) if an administrator clicks the “Delete All” option?
단일 100GB 가상 머신 디스크 파일이 있는 가상 머신에는 단일 20GB 스냅샷이 있습니다. 가상 머신의 전원이 꺼져 있습니다. 스냅샷을 삭제하고 스냅샷 델타 디스크를 기본 디스크에 커밋하려면 데이터스토어에 얼마나 많은 추가 여유 공간이 필요합니까?
* 설명
- 베이스 디스크의 사이즈는 정해져있고, 스냅샷의 내용은 베이스 디스크에 write 된다. 베이스 디스크의 사이즈가 변경되지 않는다. (씬 프로비전의 경우 정해진 한도 내에서는 커진다. 정해진 크기보다 커지지 않는다는 얘기)
- If the Base Disk is preallocated (thick provision), no extra space is required for the Delete all operation. The Base Disk will not grow as it is preallocated or thick. - If the Base Disk is non-preallocated (thin provision), the base disk will grow only on committing information from the snapshots. Each thin provision disk may grow up to its maximum size as mentioned in the Provisioned Size option in the virtual machine settings for the disk. - https://kb.vmware.com/s/article/1023657
An administrator is asked to take a snapshot of a virtual machine prior to an application upgrade.
The virtual machine has one standard virtual machine disk (VMDK) and one physical mode raw device mapping (RDM) attached.
Which statement is true with regard to taking this snapshot?
A. The administrator will be unable to snapshot the RDM.
B. The administrator will be able to snapshot the standard VMDK in independent persistent mode.
C. The administrator will be able to snapshot the RDM in independent persistent mode.
D. The administrator will be able to snapshot both disks.
관리자는 애플리케이션 업그레이드 전에 가상 머신의 스냅샷을 생성하라는 요청을 받습니다. 가상 머신에는 하나의 표준 가상 머신 디스크(VMDK)와 하나의 물리적 모드 RDM(원시 장치 매핑)이 연결되어 있습니다. 다음 중 이 스냅샷을 만드는 것과 관련하여 옳은 것은 무엇입니까?
* 영단어
- prior to : ~에 앞서
* 설명
- 이 문제에서는 2가지 디스크 형식에 대해 다루고 있다. 1. VMDK 디스크 / 2. Physical RDM 디스크
- VMDK 디스크 관련해서는 다음과 같다. - independent로 설정한 디스크는 VM 의 스냅샷에 참여하지 않는다. 즉 디스크 상태는 스냅샷 상태와 무관하고 스냅샷을 만들거나 통합하거나 스냅샷으로 되돌려도 디스크에 영향을 주지 않는다. - independent - persistent , independent - nonpersistent 두가지는 가상머신에 연결된 디스크의 설정 옵션이다. - independent-persistent : 물리적 컴퓨터의 기본 디스크처럼 동동작한다. 이 모드에서 디스크에 기록된 모든 데이터는 스냅샷을 되돌려도 디스크에 영구적으로 기록된다. - independent-nonpersistent : 읽기 전용 디스크처럼 동작한다. 여기에 수정을 하고 가상머신을 끄거나 리셋하면 변경내용은 없어진다. 매번 가상머신을 켤때마다 동일한 상태의 디스크로 시작할 수 있다. - https://docs.vmware.com/en/VMware-vSphere/7.0/com.vmware.vsphere.vm_admin.doc/GUID-8B6174E6-36A8-42DA-ACF7-0DA4D8C5B084.html
* 주제 : 인증/보안 관련
Refer to the exhibit.
An administrator repeatedly encounters this error message while attempting to connect to vCenter Server.
What should the administrator do to address this error message?
A. Use a different browser.
B. Trust the VMware certificate authority (CA) root certificate.
한 회사에 하나의 기업 데이터 센터(C1)와 하나의 지역 데이터 센터(R1)가 있습니다. 각 위치에는 vCenter Server가 있습니다. 관리자는 모든 템플릿 및 ISO 이미지에 대해 C1 및 R1에서 사용할 수 있는 중앙 라이브러리를 원합니다. 관리자가 이 요구 사항을 충족하도록 콘텐츠 라이브러리 기능을 구성하려면 다음 중 어떤 두 단계를 수행해야 합니까?
* 설명
- 컨텐츠 라이브러리 유형은 3가지이다. Local / Published / Subscribed - local : 로컬 vCenter 안에서만 사용 - published : 외부 vCenter가 엑세스 할 수 있게 됨 - subscribed : 외부 vCenter가 특정 published 한 컨텐츠 라이브러리를 연결하여 사용할 수 있게 됨
- 보기 안에서만 보았을 때, C1 또는 R1 중 하나에 컨텐츠 라이브러리를 publish 하고, publish 하지 않은 다른 하나가 해당 컨텐츠 라이브러리를 subscribe 하면 된다.
- 이 조건이 맞는 보기는 A와 E만 가능하다.
A company has a vSphere environment consisting of the following characteristics:
- A content library named ‘CORP’ is published at corporate headquarters on a vCenter Server named ‘vcenterCorp’.
- A regional data center contains a set of hosts managed by a vCenter Server named vcenterR1.
- vcenterR1 subscribes to the CORP content library.
- The administrator wants to create a new virtual machine image to use on vcenterR1.
What are two possible ways the administrator can accomplish this task?
(Choose two.)
A. Configure vcenterR1 to download all library content immediately.
B. Upload the new image to the CORP library on vcenterR1.
C. Publish the CORP content library on vcenterR1.
D. Upload the new image to the CORP library on vcenterCorp.
E. Upload the new image to a local content library on vcenterR1.
회사에는 다음과 같은 특성으로 구성된 vSphere 환경이 있습니다: - 'CORP'라는 이름의 컨텐츠 라이브러리가 기업 본사에 'vcenterCorp'라는 이름의 vCenter Server에 게시되어 있습니다. - 지역 데이터 센터에는 vcenterR1이라는 vCenter Server에서 관리하는 호스트 세트가 포함되어 있습니다. - vcenterR1은 CORP 콘텐츠 라이브러리를 구독합니다. - 관리자가 vcenterR1에서 사용할 새 가상 머신 이미지를 생성하려고 합니다. 관리자가 이 작업을 수행할 수 있는 두 가지 가능한 방법은 무엇입니까?
* 설명
A
- 문제의 질문은 vcenterR1에서 새로운 가상머신 이미지를 생성하는 2가지 방법을 물어보는 것이다. A의 내용은 연관이 없음.
B
- venterR1에는 컨텐츠 라이브러리가 없음.
C
- CORP는 이미 vcenterCorp에 publish 되어있음.
D,E
- You can create a local content library to store and manage content in a single vCenter Server instance. If you want to share the contents of that library, you can enable publishing. When you enable publishing, other users can subscribe to the library and use its content. Alternatively, you can create subscriptions for the library, which gives you control over the distribution of content. For more information about managing a local library that has publishing enabled, see Managing a Publisher Local Library.
- You can create a subscribed content library to subscribe to a published library and use its contents. You cannot upload or import items into a subscribed library. Subscribers only use the content in the published library, but it is the administrator of the published library who manages the templates. For more information about managing a subscribed library, see Managing a Subscribed Library.
관리자가 vCenter Server 로그 파일을 원격 syslog 서버로 전송하고 vRealize Log Insight를 사용하여 로그를 분석할 수 있기를 원합니다. 관리자가 이 요구 사항을 충족하려면 어떤 단계를 수행해야 합니까?
* 설명
- vRealize log insight는 로그 분석 솔루션이다.
- In the vCenter Server Management Interface, select Syslog.
- In the Forwarding Configuration section, click Configure if you have not configured any remote syslog hosts. Click Edit if you already have configured hosts.
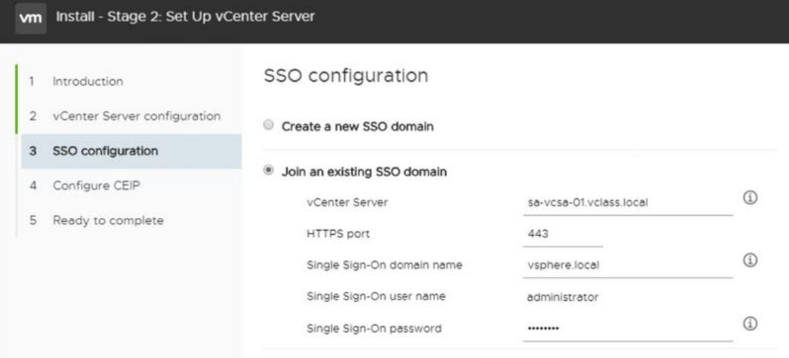
관리자가 vCenter Server Appliance를 배포 중이며 기존 vCenter Single Sign-On 도메인에 가입하려고 합니다. 관리자는 다음 정보를 수집합니다: - 가입할 vCenter Single Sign-On 서버의 FQDN - 가입할 vCenter Single Sign-On 서버의 도메인 이름 - vCenter Single Sign-On 서버 관리자 계정의 암호. 기존 vCenter Single Sign-On 도메인에 가입하려면 다른 어떤 정보가 필요합니까?
* 영단어
- being ~ed : ~상태인
* 설명
An administrator is tasked with upgrading an existing vSphere environment to version 7.0.
The current configuration is using an external Platform Services Controller. Which two statements are true regarding this upgrade?
(Choose two.)
A. The external Platform Services Controller needs to be converged into an embedded vCenter Server Appliance.
B. The external Platform Services Controller needs to be decommissioned following the deployment of the new vCenter Server Appliance.
C. The external Platform Services Controller backup can be restored to a new embedded vCenter Server Appliance.
D. The external Platform Services Controller needs to be upgraded after the vCenter Server Appliance.
E. The external Platform Services Controller needs to be powered down while a new vCenter Server Appliance is deployed.
IT 부서에서 스토리지 어레이를 폐기하고 관리자에게 ESXi 호스트에서 데이터스토어를 제거하는 작업을 요청합니다. 데이터스토어를 마운트 해제하기 위한 전제 조건은 무엇입니까?
* 영단어
- decommission : 퇴역시키다, 해체하다, 더이상 쓰지 않다
- prerequisite : 전제조건
* 설명
- Datastore를 unmount 하려면, 아래 3가지 사전조건이 있다. 1. 해당 datastore에 연결된 VM 이 없어야 함. 2. Storage DRS가 이 datastore를 관리하지 않아야 함. 3. 이 datastore에 대하여 Storage I/O Control은 disable 되어 있어야 함.
관리자는 기존 vSphere 환경을 버전 7.0으로 업그레이드하는 작업을 수행해야 합니다. 이 환경은 마운트된 NFS v3 데이터스토어로 구성되어 있습니다. 새 설계에는 NFS v4.1 데이터스토어를 구성해야 합니다. 이 업그레이드와 관련하여 다음 중 옳은 것은 무엇입니까?
* 영단어
- consist of : ~로 구성되다.
* 설명
- ESXi는 NFS 3 / 4.1 을 지원한다. (링크 내용 문맥 상, 이전 버전, 예를들어 6.5 이전버전도 NFS 4.1을 지원하는 것으로 보임) - NFS3 데이터스토어를 NFS4.1 로 업그레이드하려는 경우 아래 3가지 옵션을 사용할 수 있다. 1. NFS4.1 데이터스토어를 따로 생성하고, 스토리지 vMotion을 통해 이전 NFS3 데이터스토어에서 NFS4.1 데이터스토어로 가상 시스템을 마이그레이션 2. NFS 스토리지 서버에서 제공하는 변환 방법 사용. 자세한 사항은 저장소 공급업체에 문의 3. NFS3 데이터스토어를 마운트 해제하고, NFS4.1로 다시 마운트한다.
최근에 배포된 테스트 가상 머신 세트가 회사 개발팀 프로젝트 데이터스토어의 성능에 영향을 미치고 있습니다. 공유 캐시 서버가 스토리지 정체를 겪고 있는 것으로 보입니다. 모든 회사 데이터스토어에서 스토리지 I/O 제어가 이미 활성화되어 있습니다. 캐시 서버의 성능을 개선하기 위해 관리자가 수행해야 할 두 가지 단계는 무엇인가요?
* 영단어
- claim : 요청하다, 주장하다, 청구하나, 얻다, 앗아가다, 주장, 권리, 청구
- congestion : 혼잡, 막힘, 밀집
* 설명
A
- vcenter server는 데이터베이스안에 있는 스토리지 데이터를 주기적으로 업데이트한다. 이 스토리지 데이터가 storage provider에서 제공하는 것이다.
- A: The backing device for the existing datastore has enough free space.
- D: Depending on your storage configuration, you can use one of the following methods to increase the datastore capacity. You do not need to power off virtual machines when using either method of increasing the datastore capacity.
- You attach baselines and baseline groups to individual hosts or objects that contain hosts, such as clusters, data centers, and vCenter Server instances.
관리자는 VMware vSphere 환경을 버전 7.0으로 업그레이드하는 작업을 계획해야 합니다. 플랫폼은 논리적으로 10개의 클러스터로 분할된 80개의 ESXi 호스트로 구성됩니다. 이 작업은 회사 내 다른 운영 팀에서 완료합니다. 하드웨어는 일관되며 단일 임베디드 vCenter Server 6.7 어플라이언스가 환경을 관리합니다. 다음 중 적합한 업그레이드 접근 방식에 대해 옳은 것은 무엇입니까?
* 영단어
- consistent: 일관성
* 설명
- vSphere Environment 라고 했음. 이것은 ESXi 뿐만 아니라 vCenter도 의미한다고 본다.
- C는 must가 있는것도 이상하고, 굳이 auto deploy를 쓰지 않아도 되며, auto deploy를 쓰려면 우선 하나는 그냥 업데이트를 하고 그것을 기준으로 auto deploy를 해야한다. 적절하지는 않아 보임.
- A는 특별히 문제 없는 vCenter 업그레이드 방식임. 또한 다른 팀에서 이 작업을 한다고 했기 때문에, 템플릿으로 주는게 더 적절해 보임. 하드웨어가 consistent한 것도 같은 맥락.
- vSphere Distributed Switch에 연결된 물리적 어댑터에서 호스트 관리, 가상 시스템, NFS 스토리지, vSphere vMotion, vSphere Fault Tolerance, vSAN 및 vSphere Replication에 대한 대역폭을 할당합니다.
- 이를 사용하기 위해 Verify that Network I/O Control on the switch is version 3 인지 확인이 필요
호스트에 연결을 제공하고 vSphere vMotion의 표준 시스템 트래픽을 처리하도록 설계된 네트워크 어댑터 유형은 무엇입니까?
* 설명
- The VMkernel networking layer provides connectivity to hosts and handles the standard system traffic of vSphere vMotion, IP storage, Fault Tolerance, vSAN, and others
관리 트래픽, vSphere vMotion, IP 스토리지 및 vSphere 내결함성을 지원할 수 있는 TCP/IP 스택은 무엇입니까?
* 설명
- VMKernel 레벨의 TCP/IP 스택은 2가지가 있음.
1. 기본 TCP/IP stack : esxi 호스트 간의 관리 트래픽, vmotion, IP스토리지, vSphere FT 같은 시스템 트래픽 지원
2. vSphere vMotion TCP/IP steack : 가상머신 hot migration을 위한 트래픽 지원
- VMware Certified Professional - Data Center Virtualization 2022 (VCP-DCV 022 / 2V0-21.20)
- Provides networking support for the management traffic between vCenter Server and ESXi hosts, and for system traffic such as vMotion, IP storage, Fault Tolerance, and so on.
관리자가 다음 오류 로그 메시지와 함께 전원이 켜진 가상 머신이 마이그레이션에 실패한 이유를 조사하고 있습니다: 관리자가 이 오류를 해결하려면 어떤 단계를 완료해야 합니까?
* 설명
- In the absence of Enhanced vMotion Compatibility (EVC), virtual machines cannot be migrated to hosts whose CPUs do not provide the same or greater capability and features.
관리자가 두 부서 간에 제한된 CPU 및 메모리 리소스를 분할하기 위해 사용할 수 있는 방법은 무엇인가요?
* 영단어
- department : 부서
* 설명
- A resource pool is a logical abstraction for flexible management of resources. Resource pools can be grouped into hierarchies and used to hierarchically partition available CPU and memory resources. - For each resource pool, you specify reservation, limit, shares, and whether the reservation should be expandable.
관리자가 CPU 및 메모리 리소스를 관리하고 위임하는 데 도움이 되도록 구성해야 하는 VMware 기능은 무엇입니까?
* 영단어
- delegate : 위임
* 설명
- Resource pools allow you to delegate control over resources of a host (or a cluster), but the benefits are evident when you use resource pools to compartmentalize all resources in a cluster. Create multiple resource pools as direct children of the host or cluster and configure them. You can then delegate control over the resource pools to other individuals or organizations.
- You can run the esxtop utility using the ESXi Shell to communicate with the management interface of the ESXi host. You must have root user privileges.
가상머신을 다른 호스트로 옮기는 것 (호스트, 즉 컴퓨팅 리소스가 바뀜) - hot migration : 가상머신이 켜져 있는 상태에서 마이그레이션 하는 것 - cold migration : 가상머신이 꺼지거나 정지된 상태에서 마이그레이션 하는것
Storage vMotion
VM의 파일을 다른 데이터스토어로 옮기는 것 (디스크 부하 분산, 스토리지 어레이 전환 등을 목적으로)
High Availability
ESXI 호스트나 가상머신, 가상머신 내의 어플리케이션 중단 시 클러스터 내의 다른 호스트에서 VM을 다시 시작함. (저장소, 네트워크 문제인 경우에도 HA 사용 가능) Proactive HA는 아래와 같은 설정들을 쓰는 것임. manual/automated, quarantine/maintenance mode 등
Admission Control
특정 호스트가 죽어서 다른 호스트로 VM이 넘어갈 때, 그 다른 호스트가 수용할 수 있는 VM의 양을 정하는 것
Replication
하이퍼바이저 기반 (ESXi 기반) VM 복제/복구. 사이트와 사이트사이에 VM을 복제함. 각 복제는 저장되며 복구 시점을 가지며 특정 시점으로 복원 가능.
Fault Tolerance
원본 VM을 지속적으로 복제하고 있는 보조 VM이 있고, 원본 VM에 문제 발생시 보조 VM으로 Takeover하여 무중단을 실현하는 기능. HA와 동일해 보이나 HA는 리부팅이 필요하고, FT는 리부팅이 필요없음. 무중단.
vSphere DRS
클러스터의 컴퓨팅 자원을 논리적 리소스 풀로 통합하고 VM의 배치, 로드 밸런싱 등을 수행한다.
Which feature is a prerequisite for Proactive High Availability (HA)?
A. vCenter High Availability
B. vSAN Cluster
C. Predictive Distributive Resource Scheduler (DRS)
- Cluster Settings에서 vSphere DRS 활성화가 가능하다. 여기에 vRealize Operation을 구매하면 해당 설정에서 Predictive DRS 를 활성화 할 수 있다.
- 이 기능은 가까운 미래를 예측하는 것임. 예를들어 가상머신이 3시간 있다가 부하 많이 걸릴 것 같으니 옮기는 게 어떤지? 이런식으로 알려주는 것임.
- VMware Certified Professional - Data Center Virtualization 2022 (VCP-DCV 022 / 2V0-21.20)
In a vSphere High Availability (vSphere HA) cluster, which action does vSphere HA take when the VM Monitoring service does NOT receive heartbeats from a virtual machine (VM) in the cluster?
A. The VM is restarted on a different host in the cluster.
B. The VM is suspended on the same host in the cluster.
C. The VM is migrated to a different host in the cluster.
D. The VM is restarted on the same host in the cluster.
- 여기서 데이터 센터는 가상시스템을 운영하기 위해 올바르게 작동하는 환경을 구성하는데 필요한 모든 인벤토리 개체의 모음을 의미한다. VM, 클러스터, 리소스풀, 네트워킹, 데이터스토어 등을 모아놓는 말그대로 "데이터 센터" 이다.
A
- Fault Tolerance provides continuous availability by ensuring that the states of the Primary and Secondary VMs are identical at any point in the instruction execution of the virtual machine.
- 동일한 사이트 또는 다른 지리적 영역에 있는 클러스터 및 vCenter Server 인스턴스 간에 워크로드 밸런싱.
- 개발 환경에서 프로덕션 환경으로 등 용도가 다른 환경 간에 VM을 이동하는 경우.
- 스토리지 공간, 성능 등에 대한 다양한 SLA(서비스 수준 계약)를 충족하기 위해 VM을 이동함
- VMware Certified Professional - Data Center Virtualization 2022 (VCP-DCV 022 / 2V0-21.20)
D
- Local 이 있기 때문에 D는 아님
An administrator wants to ensure that when virtual machines (VMs) are powered on, Distributed Resource Scheduler (DRS) places them on the best-suited host.
When the cluster becomes imbalanced, the administrator wants DRS to display recommendations for manual VM migration.
Which DRS automation level should the administrator select?
관리자는 가상 머신(VM)의 전원이 켜지면 분산 리소스 스케줄러(DRS)가 가상 머신을 가장 적합한 호스트에 배치하기를 원합니다. 클러스터의 불균형이 발생하면 관리자는 DRS가 수동 VM 마이그레이션에 대한 권장 사항을 표시하기를 원합니다. 관리자는 어떤 DRS 자동화 수준을 선택해야 합니까?
* 영단어
- imbalanced : 불균형의
* 설명
- Partially automated : Initial placement is performed automatically. Migration recommendations are displayed, but do not run.
A vSphere environment is configured with 1 Gigabit Ethernet for vSphere vMotion.
The application team is complaining that when they try to migrate a powered-on virtual machine, the progress is slow and unsuccessful the majority of the time.
Which two recommendations should the administrator make to improve vSphere vMotion performance?
(Choose two.)
A. Use at least two port groups.
B. Use vSphere Storage I/O Control (SIOC).
C. Use 10 Gigabit Ethernet or above.
D. Use Link Aggregation Control Protocol (LACP) on the port group.
vSphere vMotion을 위한 1기가비트 이더넷으로 vSphere 환경이 구성되어 있습니다. 애플리케이션 팀에서 전원이 켜진 가상 머신을 마이그레이션하려고 할 때 진행 속도가 느리고 대부분의 경우 실패한다고 불평하고 있습니다. 관리자가 vSphere vMotion 성능을 개선하기 위해 수행해야 하는 두 가지 권장 사항은 무엇입니까?
* 영단어
- the majority of the time : 대부분의 경우
* 설명
A,D
- LACP보다 2개의 NIC를 사용 (Two port group)하는것이 더 성능이 좋다.
회사 환경에는 두 개의 vSphere 클러스터가 있습니다. 한 클러스터는 개발 워크로드를 호스팅하고 다른 클러스터는 프로덕션 워크로드를 호스팅합니다. 두 vSphere 클러스터는 모두 동일한 vCenter Server에서 관리됩니다. 애플리케이션 팀은 다운타임 없이 새 가상 머신을 개발 클러스터에서 프로덕션 클러스터로 이동하고자 합니다. 이 두 클러스터 간에 무중단 이동을 허용하는 기능은 무엇입니까?
* 설명
A
- Cross vCenter Migration : 서로 다른 vcenter 밑에 있는 vm을 마이그레이션하는 것.
B
- vSphere High Availability는 가상머신 내의 호스트, 데이터스토어, 가상머신, 애플리케이션 등을 모니터링하다가 장애 감지되면 대체 호스트에서 가장머신을 다시 시작하거나 가상머신을 재설정하여 가상 머신 다운타임을 최소화하는 것.
C
- VMware vSphere vMotion은 한 서버에서 다른 서버로 워크로드를 다운타임 없이 실시간으로 마이그레이션할 수 있습니다.
- vSphere replication은 하이퍼바이저 기반 가상 시스템 복제 및 복구 기능 제공
An administrator wants to configure vCenter Server High Availability so that each node is located in a different data center. Which requirement must be met?
A. Each node must be configured with at least three network adapters.
B. Network latency between the nodes must be less than 10 milliseconds.
C. All nodes must be located on a vSAN datastore in each data center.
D. A vCenter Server license must be assigned to each node.
관리자가 두 개의 도메인 컨트롤러 가상 머신(VM)이 포함된 2노드 vSphere 클러스터를 실행합니다. 관리자는 정상적인 유지 관리 작업을 방해하지 않고 VM이 별도의 호스트에서 실행되도록 하려고 합니다. 관리자는 분산 리소스 스케줄러(DRS)를 어떻게 구성해야 합니까?
* 영단어
- interfering : 간섭하는
* 설명
- 문제를 다시 풀어읽어보면, 2개의 ESXi 호스트가 있는 클러스터가 있고, 각각 도메인 컨트롤러 VM이 있다. 해당 도메인 컨트롤러 VM은 두 노드에 나뉘어져 있어야 한다. 그런데 나눠져있는것은 맞는데, 일반 유지 작업을 방해하지 않도록 해야 한다. - 즉 DRS에서 Affinity Rule을 적용할때, must 같은것을 써버리면 ESXi 호스트를 하나 메인터넌스 모드로 빼는 경우 Affinity rule을 적용할 수 없어 메인터넌스 모드에 진입이 불가능해진다. - 따라서 should run을 써서 특정 VM이 특정 HOST에 있되 메인터넌스 작업을 방해하지 않도록 해야 한다.
An administrator needs to configure Proactive High Availability (HA) in a vSphere environment so that virtual machines (VMs) do not run on any partially degraded hosts.
The administrator would also like to see the recommendations before VMs are migrated.
Which automation and remediation level should the administrator select?
A. Automation Level – Manual Remediation Level – Quarantine mode
B. Automation Level – Automated Remediation Level – Maintenance mode
C. Automation Level – Manual Remediation Level – Maintenance mode
D. Automation Level – Automated Remediation Level – Mixed mode
관리자는 가상 머신(VM)이 부분적으로 성능이 저하된 호스트에서 실행되지 않도록 vSphere 환경에서 사전 예방적 고가용성(HA)을 구성해야 합니다. 또한 관리자는 VM을 마이그레이션하기 전에 권장 사항을 확인하고자 합니다. 관리자는 어떤 자동화 및 문제 해결 수준을 선택해야 합니까?
- Migration of VMs across vCenter Server instances is helpful in the following cases : Balancing workloads across clusters and vCenter Server instances that are in the same site or in another geographical area.
- VMware Certified Professional - Data Center Virtualization 2022 (VCP-DCV 022 / 2V0-21.20)
- 스트레치드 클러스터를 쓰면 A, E 가 답이라고 하지만, 그런 논리라면 모두 답이 된다.
- A,B,D는 클러스터 내에서 동작 가능하다.
Which feature can an administrator configure to have a copy of critical virtual machines in another cluster?
관리자가 가상 머신(VM)을 보호하기 위해 보안 확장을 사용하는 프로세서별 기술을 활용하고자 합니다. 이를 통해 사용자 수준 코드에서 외부 액세스로부터 보호되는 엔클레이브라고 하는 메모리의 개인 영역을 정의할 수 있습니다. VM이 이 기술을 사용하도록 하려면 관리자가 구성해야 하는 사항은 무엇인가요?
* 영단어
- enclave : 고립된 지역
- leverage : 영향력, 효력
* 설명
- AES-NI :AES를 사용하는 암호화와 복호화의 수행 성능을 향상시키기 위한 명령어 집합.
- TPS : VMkernel에서 두 개 이상의 가상 시스템에 동일한 메모리 페이지를 한 번만 저장하여 물리적 메모리 리소스를 보다 효율적으로 사용하기 위해 사용하는 메커니즘.
- Intel SGX is a processor-specific technology for application developers who seek to protect select code and data from disclosure or modification. Intel SGX allows user-level code to define private regions of memory, called enclaves.
- During shutdown, the virtual machines shut down in the reverse order.
- When you power off the ESXi host, it starts powering off the virtual machines that run on it. The order in which virtual machines are powered off is the reverse of their startup order.
관리자가 문제 해결 프로세스 전과 프로세스 중에 ESXi 호스트 동작을 구성하고 있습니다. 일부 하드웨어 플랫폼에서만 지원되는 문제 해결 설정은 무엇입니까?
* 영단어
- remediation : 복원, 교정
* 설명
- Quick Boot란, vSphere Quick Boot는 주요 서버 벤더와 함께 제공되는 혁신 기술로, 물리적 호스트를 재부팅하지 않고 VMware ESXi™ 하이퍼바이저를 다시 시작하여 시간이 많이 소요되는 하드웨어 초기화를 건너뜁니다. 물리적 하드웨어가 장치를 초기화하고 필요한 자체 테스트를 수행하는 데 몇 분 이상 걸리는 경우 Quick Boot을 사용할 때 예상할 수 있는 대략적인 시간 절약입니다.
- 여기서 remediation은 해당 호스트를 패치, 업그레이드를 말한다.
- ou must ensure that the ESXi host is compatible with the feature.
- 정리하면, remediation 옵션은 VM Migration, HA Admission Control, Maintenance mode failures, Quick Boot 등의 기능이 있는데, 이 중 특정 하드웨어 플랫폼에서 support 하는 기능이 무엇인지 물어보는 것임.
- vSphere는 캡슐화를 사용해 VM의 정보를 파일로 생성하며, 이 파일들을 스토리지의 별도 디렉토리에 저장한다.
- 스토리지는 VMFS, NFS, vSAN, vSphere Virtual Volumes 등의 Datastore 들이다. (스토리지 부분에서 자세히 설명)
- VM을 몇개의 파일 또는 개체로 캡슐화하면, VM을 보다 쉽게 관리할 수 있으며 마이그레이션도 쉽게 할 수 있다.
- 예를들어 VM1을 다른 스토리지로 마이그레이션 하려면 다른 Datastore에 복사하면 되는것이다.
- 아래와 같이 ICM-Datastore에 WIN10-0X 들은 모두 VM의 디렉토리이다. 이 안에 파일들이 있다.
* 가상 머신 파일 정보
VM_name.vmx (ex : vm01.vmx)
- VM의 구성요소 정보 (CPU 개수, 메모리 용량, 랜카드 수, 디스크 등
VM_name.vswp (ex : vm01.vswp)
- 메모리 Swap 데이터 파일 - 가상머신을 켜면 이 swap 파일이 생성된다. 가상머신을 끄면 해당 파일은 없어진다. - SWAP 메모리 정보이며, SWAP 사이즈를 정하면 그 사이즈만큼의 파일이 생성된다. - VM을 켜면 아래와 같이 노란색 표시한 부분 파일이 생성된다.
vmx-VM_name.vswp (ex : vmx-vm01.vswp)
- 메모리 Swap 구성파일. - 자주 사용되는 파일은 아니다.
VM_name.nvram
- VM의 바이오스 설정이 저장된 파일.
vmware.log vmware-1.log vmware-2.log ...
- VM의 현재 로그 파일(.log) 과 로그 아카이브시 사용되는 파일 집합(-#.log) - vmware.log는 현재 로그 파일이며, vmware-1.log, vmware-2.log... 들은 아카이브된 파일이다. - vmware.log 외에 한번에 최대 6개의 아카이브 로그 파일이 유지 관리된다. - 로그가 쌓일 때, vmware.log는 vmware-1.log로 변경되고, vmware-1.log은 vmware-2.log 로 변경되는 식이다.
VM_name.vmdk
- 디스크 descriptor 파일. 메뉴얼에는 Virtual disk characteristics 으로 표기됨. - 하나 이상의 가상 디스크 파일. 첫 번째 가상 디스크에는 VM_name.vmdk 및 VM_name-flat.vmdk 파일이 있다. - VM에 디스크 파일이 1개보다 더 많은 경우, 파일 네이밍은 VM_name_#.vmdk 및 VM_name_#-flat.vmdk 가 된다. (#은 1부터 시작) - 가상머신에 저장된 모든 데이터들이 여기 저장된다. 어떤 파일이든 증가하면 사이즈가 올라간다. - 10kb 파일을 저장하면 실제로 그만큼 용량이 늘어난다.
VM_name-flat.vmdk
- 디스크의 데이터 파일 - 리눅스에서 보면 링크가 걸린 파일이 있는데 이것과 같은 맥락으로 사실은 실제로 용량에 저장되는게 vmdk파일이 아니고 flat.vmdk 파일이다. - vmdk파일은 flat.vmdk와 하드링크로 연결되어 있다. (하드링크 : 아이노드가 같고 이름이 다른 파일) - 결국은 vmdk와 flat.vmdk 서로 동일한 것이며, 관리자가 볼때는 vmdk로 보이고, 내부적으로 동작할때는 flat.vmdk로 동작한다.
VM_name.vmtx
- VM 템플릿 구성 파일 - VM을 템플릿으로 변환하면, 이 구성파일이 vmx파일을 대체하게 됨. - VM 템플릿은 VM의 원본 사본이다. (A VM template is an original copy of the VM.)
VM_name-*.vmss
- 서스펜드 상태 파일
VM_name.스냅샷번호.vmsn (ex : S1vm.snapshot1.vmsn)
- 스냅샷 생성 시점의 가상 메모리 상태 - 이 파일은 메모리 선택에 관계없이 스냅샷 생성할때마다 만들어짐. - 메모리가 없는 .vmsn파일은 메모리가 있는 파일보다 훨씬 작다.
VM_name. vmsd
- 가상 시스템 스냅샷 정보의 데이터베이스이며 스냅샷 관리자 관련 정보의 기본 소스 데이터
- 이름에 vmx가 붙으면 구성에 관련된 것이다. vmx파일은 메모장으로 열리며, 직접 수정도 가능하다.