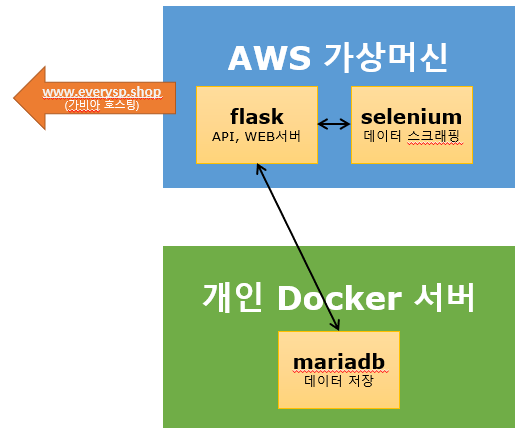
도커 컨테이너를 사용하여 스크래핑과 사이트 두개의 컨테이너를 올리는데, 스크래핑 컨테이너가 중간에 잘못 종료되는경우 DB에 문제가 생긴다. 이건 생각보다 꽤 큰 문제점이다.
이 문제는 DB스위칭을 하기 때문이며, DB 스위칭을 테이블 이름 변경으로 스위칭 하기 때문이다.
현재 아래와 같이 2개의 테이블이 있다.
원래 이 DB는 아래와 같은 코드로 스위칭된다.
# 1. bg_product_data 에서 크롤링 완료 (유저가 접속하는것은 실제로 product_data 이다.) # 2. product_data를 dummy_product_data로 이름변경 (dummy에는 옛날 데이터가 있다.) # 3. bg_product_data를 product_data로 이름변경 (product_data에는 최신 데이터가 있다.) # 4. dummy_product_data를 bg_product_data로 이름변경 (옛날 데이터가 있는 dummy가 bg로 변경된다. 어차피 또 스크래핑 하면, 데이터는 싹 다 날라간다.) # 5. bg_product_data 에서 크롤링 완료... 이하반복
근데 중간에 잘못되어 저 3개의 RENAME 작업이 모두 하나의 트랜잭션으로써 완료되지 않으면 위와같이 bg_product_data, product_data 두개로 남아야 되는데 그게 안되고 dummy_product_data, bg_product_data 이런식으로 남게 되는 것이다. 이러면 크롤링할 데이터를 넣고 DB 이름변경으로 스위칭하는데 문제가 생긴다.
아무튼, 괜히 문제없는 크롤링 코드를 건드리려고 했다가 DB를 보고 문제를 바로 파악해서 다행이다.
시스템 엔지니어로서, 오픈소스의 시대가 도래하고 있고 "결국은 개발을 배워야 한다" 라는 생각을 가지고 있었는데, 기억은 잘 안나지만 페북 광고인가... 인터넷 광고인가 아무튼 스파르타 코딩클럽이라는 광고를 접한 적이 있다. 이때만 해도 개발 공부를 위해패xx캠xx 에서 파이썬 강의 결제를 언제 해야하나 라고 고민하고 있던 때였다. 그런데 아무래도 온라인 강의로 여러번 쓴잔을 마신 적이 있던 터라 (개발 강의를 끝까지 끝낸 적이 없음;;;) 오프라인으로 만나서 수업한다는 스파르타 코딩클럽의 방식이 매우 크게 다가왔다.
개발은 정말 영어와 같은 "언어" 이다. 자주 사용해야 발전한다. 이런 측면에서 온라인 강의는 과연 내가 "자주" 공부할 수 있게 만들 수 있을까?? 라는 의문을 갖고 있었기 때문에 스파르타코딩클럽은 좀 더 나에게 효과적이라고 생각했다. 또한 왕초보도 할 수 있다는 커리큘럼도 맘에 들었고. 그래서 일반 개발 강의와 비교했을 때 나름 거금을 투자할 수 있었다.
7월에 시작해서 벌써 9월, 생각보다 길었지만 또 어떻게 보면 금방 지나간 기간이기도 하다. 사실 1주차 수업을 끝낸 후, "이걸 8주동안 하면... 어우야.... 쉽지 않겠는데.." 라는 생각이 들었다. 초보자가 할 수 있지만, 도전적인 마인드가 필요한 강의였다. 즉 내가 하려는 의지에 따라 난이도를 쉽게도 할 수 있고, 어렵게도 할 수 있다. 이러한 유연함이 꽤 좋았던 것 같다.
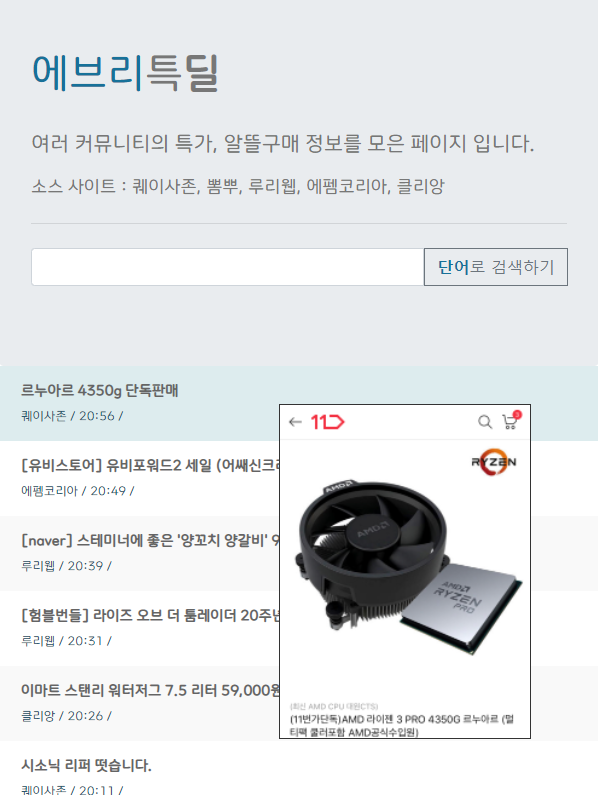
1. 데이터 스크래핑 : python 스크립트를 통해 각 커뮤니티의 특가 게시판에서 데이터를 스크래핑 수행
2. 데이터 저장 : mysql에 해당 데이터들을 저장.
3. 웹페이지 뼈대 출력 : python flask에서 웹서버를 올리고 뼈대를 출력
4. 웹페이지 내용 출력 : python flask에서 ajax통신을 사용하는 API를 구축하고, 해당 API에 맞게 DB에서 데이터를 가져옴.
5. 업데이트 : 서버에서는 1번 스크래핑을 20분 주기로 수행하여 20분마다 새로운 특가정보를 지속적으로 가져옴.
결국 극복하지 못한 점과 향후 진행 예정
* 스크래핑 주기와 서버
주기를 10분정도로 하고 싶었으나, 1년 무료로 제공되는 AWS의 가상머신으로는 부하 때문에 어려운 듯 하다. 한 2일 돌다가 뻗는다. 20분 주기로 계속 하다가, 계속 서버가 먹통이 되길래 결국 AWS가 아닌 GCP로 서버를 바꿨다. GCP는 신규가입시 30만원어치의 크레딧을 주므로 AWS보다 더 좋은 성능이지만 더 적은 기간동안 쓸 수 있다. 일단 쓰다가 이후에는 내 도커 컨테이너로 옮길 예정이다.
* 썸네일 마우스오버 출력
이미지를 그냥 출력하면 사이트의 레이아웃을 깰 수 있어, 각각 항목에 마우스를 올리면 이미지를 작게 띄울 수 있도록 했다. 제목이 아닌 밑에 빈공간에 커서를 대면 썸네일이 나온다. 이는 모바일에서도 썸네일을 볼 수 있게 하기 위함이다. 전체적인 레이아웃을 깔끔하게 하기 위해 넣은 기능인데, 사용자 경험적으로는 약간 애매하다. 불편할때도 있고... 조금 개선할 필요가 보인다.
* 방문자 분석
구글 애널리틱스를 사용하여 누적 방문자와 경향, 검색 유입 등을 분석
* https 보안
현재 해당 사이트는 http로만 서비스하며, 요즘같이 위험한 세상에 http 서비스는 신뢰가 매우 낮으므로, 향후 https로 전환할 예정
* 모바일 모드
뷰포트로 간단하게 모바일로 볼 수는 있게 해두었지만, 조금씩 사용에 불편함이 있어 전체적으로 html을 엎어서 변경할 필요가 있어 보임.
* 카테고리화
아무래도 특가 정보가 너무 많아 카테고리화를 시키면 좋겠는데 (예를들어 음식, 가전제품, 미용, 건강 등..), 이렇게 하려면 결국은 제목을 가지고 카테고리를 만들 수 있도록 해야한다. 간단한 방법은 수작업이고, 자동화 하려면 뭔가.. 딥러닝이나 빅데이터 분석? 같은 게 필요한 것으로 보인다. 근데 이것은 다른 내용들보다도 훨씬 어렵고, 심지어 가능할지도 모르겠다. 하지만 개인적으로 빅데이터와 딥러닝쪽도 향후 공부할 예정이 있으므로, 공부해보고 가능하다면 구현해보고 싶다.
마치며
이러한 개발과 서비스 구축에 대해 배우면서시스템 엔지니어로서 몰랐던새로운 시각을 갖게 되었다. 이러한 배움은 적어도 내가 온라인에서 그냥 녹화된 강의를 듣는 것으로는 얻을 수 없는 것이라고 생각한다. 또한, 개발자 라는 직업을 하지 않은 것에 대해.. 사실 다행이라고 생각하기도 한다.너무 힘들어!!!하지만 느껴보지 못한 새로운 성취감을 느낄 수 있었다. 또한 자신감도 가질 수 있었다.
마지막으로 제일 걱정되는 게 있다. 이렇게 공부해놓고 다 끝났으니 아무것도 안해~ 이래버리면... 분명 또 다 까먹을 것이다. 그게 언어니까. 결국 조금씩이라도 지속적으로 해야 한다는 거다. 연말에 여유 될 때 또 새로운 프로젝트를 시작해보는 것도 좋을 것 같다. 아마 간단하게는 IOT쪽, 좀 심도있게 하려면 딥러닝이나 빅데이터쪽을 시도해볼 수 있으면 좋겠다.
생각해보니 그렇다. 결국, 한번 발을 들여놓았으면 계속 해야 까먹지 않고 계속 써먹을 수 있다는 것..ㅜㅜ 개발이란 참 어려운 길이다.
시스템 엔지니어로서, 오픈소스의 시대가 도래하고 있고 "결국은 개발을 배워야 한다" 라는 생각을 가지고 있었는데, 기억은 잘 안나지만 페북 광고인가... 인터넷 광고인가 아무튼 스파르타 코딩클럽이라는 광고를 접한 적이 있다. 이때만 해도 개발 공부를 위해 패xx캠xx 에서 파이썬 강의 결제를 언제 해야하나 라고 고민하고 있던 때였다. 그런데 아무래도 온라인 강의로 여러번 쓴잔을 마신 적이 있던 터라 (개발 강의를 끝까지 끝낸 적이 없음;;;) 오프라인으로 만나서 수업한다는 스파르타 코딩클럽의 방식이 매우 크게 다가왔다.
개발은 정말 영어와 같은 "언어" 이다. 자주 사용해야 발전한다. 이런 측면에서 온라인 강의는 과연 내가 "자주" 공부할 수 있게 만들 수 있을까?? 라는 의문을 갖고 있었기 때문에 스파르타코딩클럽은 좀 더 나에게 효과적이라고 생각했다. 또한 왕초보도 할 수 있다는 커리큘럼도 맘에 들었고. 그래서 일반 개발 강의와 비교했을 때 나름 거금을 투자할 수 있었다.
7월에 시작해서 벌써 9월, 생각보다 길었지만 또 어떻게 보면 금방 지나간 기간이기도 하다. 사실 1주차 수업을 끝낸 후, "이걸 8주동안 하면... 어우야.... 쉽지 않겠는데.." 라는 생각이 들었다. 초보자가 할 수 있지만, 도전적인 마인드가 필요한 강의였다. 즉 내가 하려는 의지에 따라 난이도를 쉽게도 할 수 있고, 어렵게도 할 수 있다. 이러한 유연함이 꽤 좋았던 것 같다.
1. 데이터 스크래핑 : python 스크립트를 통해 각 커뮤니티의 특가 게시판에서 데이터를 스크래핑 수행
2. 데이터 저장 : mysql에 해당 데이터들을 저장.
3. 웹페이지 뼈대 출력 : python flask에서 웹서버를 올리고 뼈대를 출력
4. 웹페이지 내용 출력 : python flask에서 ajax통신을 사용하는 API를 구축하고, 해당 API에 맞게 DB에서 데이터를 가져옴.
5. 업데이트 : 서버에서는 1번 스크래핑을 20분 주기로 수행하여 20분마다 새로운 특가정보를 지속적으로 가져옴.
결국 극복하지 못한 점과 향후 진행 예정
* 스크래핑 주기
주기를 10분정도로 하고 싶었으나, 1년 무료로 제공되는 AWS의 가상머신으로는 부하 때문에 어려운 듯 하다. 한 2일 돌다가 뻗는다. 20분도 어떻게 될 지는 모르겠지만, 20분도 안된다면 개인 docker 서버에 컨테이너 형태로 다시 올려야 할 듯 하다.
* 썸네일 마우스오버 출력
이미지를 그냥 출력하면 사이트의 레이아웃을 깰 수 있어, 각각 항목에 마우스를 올리면 이미지를 작게 띄울 수 있도록 함.
* 방문자 분석
구글 애널리틱스를 사용하여 누적 방문자와 경향, 검색 유입 등을 분석
* https 보안
현재 해당 사이트는 http로만 서비스하며, 요즘같이 위험한 세상에 http 서비스는 신뢰가 매우 낮으므로, 향후 https로 전환할 예정
* 모바일 모드
뷰포트로 간단하게 모바일로 볼 수는 있게 해두었지만, 조금씩 사용에 불편함이 있어 전체적으로 html을 엎어서 변경할 필요가 있어 보임.
* 카테고리화
아무래도 특가 정보가 너무 많아 카테고리화를 시키면 좋겠는데 (예를들어 음식, 가전제품, 미용, 건강 등..), 이렇게 하려면 결국은 제목을 가지고 카테고리를 만들 수 있도록 해야한다. 간단한 방법은 수작업이고, 자동화 하려면 뭔가.. 딥러닝이나 빅데이터 분석? 같은 게 필요한 것으로 보인다. 근데 이것은 다른 내용들보다도 훨씬 어렵고, 심지어 가능할지도 모르겠다. 하지만 개인적으로 빅데이터와 딥러닝쪽도 향후 공부할 예정이 있으므로, 공부해보고 가능하다면 구현해보고 싶다.
마치며
이러한 개발과 서비스 구축에 대해 배우면서 시스템 엔지니어로서 몰랐던 새로운 시각을 갖게 되었다. 이러한 배움은 적어도 내가 온라인에서 그냥 녹화된 강의를 듣는 것으로는 얻을 수 없는 것이라고 생각한다. 또한, 개발자 라는 직업을 하지 않은 것에 대해.. 사실 다행이라고 생각하기도 한다. 너무 힘들어!!! 하지만 느껴보지 못한 새로운 성취감을 느낄 수 있었다. 또한 자신감도 가질 수 있었다.
마지막으로 제일 걱정되는 게 있다. 이렇게 공부해놓고 다 끝났으니 아무것도 안해~ 이래버리면... 분명 또 다 까먹을 것이다. 그게 언어니까. 결국 조금씩이라도 지속적으로 해야 한다는 거다. 연말에 여유 될 때 또 새로운 프로젝트를 시작해보는 것도 좋을 것 같다.
아.. 잘 진행하다가, 아주 난감한 결함을 발견했다. 한번 테스트 해볼려고 AWS에 올린 리눅스 서버에서 스크래핑을 하는데, 거의 10분 가까이 걸리는 것이다. 겁나 느리다. 이 때 아차 싶던게.. 스크래핑 하고 있을 때 데이터 수집하고 삭제하고 난리인데 실제 사이트에서 10분동안 그런게 보인다는 것이다.;;;;;; 아....이런...
어떻게 할까 머리를 쥐어짜다가, 이거 꽤.. 괜찮은데? 라는 아이디어가 생겼다.
어차피 여기 데이터베이스는 300~400건도 안되고, 계속 삭제되니 중요한 데이터도 아니다. 그러니까, 동일한 DB를 두개 만들고, 하나는 스크래핑용, 하나는 실제로 HTML에서 출력하는 용으로 사용하는 것이다.
그리고, 스크래핑이 완료되면 스크래핑이 완료된 DB를 HTML에서 출력하는 용도의 DB로 이름을 바꿔버리는 것이다... ㅋㅋㅋㅋㅋㅋ..ㅋㅋㅋㅋ
정리해보자.
- 동일한 형태의 데이터베이스를 총 2개 만든다. 그 이유는, 스크래핑 돌리는 동안, 서버에 붙으면 데이터가 이상하다. 스크래핑 도중이라서 그렇고, 스크래핑이 오래 걸린다.
- 즉 사용중인 데이터베이스는 그대로 두고, 스크래핑시 데이터 저장하는 데이터베이스를 따로 만들어 두고 이름을 서로 바꾸는 방식으로 한다.
- 데이터를 복사하지 않고 이름을 바꾸는 이유는 복사보다 이름 변경이 훨씬! 빠르기 때문이다. 사용자가 중간에 이상한 데이터를 볼 가능성을 최대한 낮추기 위함이다.
- 즉 이름을 서로 바꾸므로 총 2개의 테이블이 있어야 한다. 이름은 다음과 같다. product_data : 메인 테이블 / bg_product_data : 스크래핑용 테이블
전체적인 순서는 다음과 같다.
1. bg_product_data 에서 크롤링 완료 (유저가 접속하는것은 실제로 product_data 이다.) 2. product_data를 dummy_product_data로 이름변경 3. bg_product_data를 product_data로 이름변경 (product_data에는 최신 데이터가 있다.) 4. dummy_product_data를 bg_product_data로 이름변경 (이전 데이터가 있는 dummy가 bg로 변경된다. 어차피 또 스크래핑 하면, 데이터는 싹 다 날라간다.)
내 스크래핑 방식은 페이지단위로 스크래핑을 하기 때문에, 스크래핑 주기에 따라 페이지가 다 넘어가지 않으면 당연하게도 이전 스크래핑 내용과 새로 스크래핑한 내용이 겹치게 된다. 이를 해결하기 위해 DB단에서 데이터를 제거하는게 가장 빠르고 편리했다.
게다가, 이것 때문에 mongodb에서 mariadb로 전환하기도 했다. mongodb에서는 중복제거가 매우 어렵다... 내가 너무 잘 몰라서 그런 것일수도 있는데, 인덱스를 사용하거나, 맵리듀스를 사용하거나... 아무튼 내가 원하는 대로는 결과가 잘 나오지 않았다.
mongodb에서 mariadb로 전환하는데는 조금 시간이 걸렸지만, 다행히 잘 적응하고 전환도 잘 했다. 그리고 쉽게 중복제거를 찾을 수 있었다.
DELETE a FROM 중복검사할테이블 a, 중복검사할테이블 b WHERE a.id > b.id AND a.열이름= b.열이름;
간단하게 말하면 같은 테이블을 a, b로 명명하고 "열"을 기준으로 같으면 제거하는 방식이다.
중간에 a.id > b.id 는 아마 id열로 뭔가 하는것같은데 이건 이해가 잘 안된다..ㅠㅠ 아무튼 id열도 있어야 한다.
파이썬에서 최종적으로 중복제거하는 구문은 다음과 같다.
conn = pymysql.connect(host="XXXXXXXXXXX", port=XXXXX, user="root", password="root", db="XXXXXe", charset="utf8")
curs = conn.cursor()
removeDuptitle = "DELETE a FROM bg_product_data a, bg_product_data b WHERE a.id > b.id AND a.title = b.title;"
curs.execute(removeDuptitle)
removeDupLink = "DELETE a FROM bg_product_data a, bg_product_data b WHERE a.id > b.id AND a.link = b.link;"
curs.execute(removeDupLink)
conn.commit()
conn.close()
그리고, 각 사이트에서 품절되거나, 뭔가 별로인 deal 정보라서 글을 내리는 경우, 짧게 "삭제합니다", "펑" 뭐 이런식으로 넣어놨는데, 이런것까지 스크래핑되지 않게 하기 위해 (정확히 말하면 스크래핑은 했지만 db에서는 삭제하기 위해) 아래와 같이 title부분의 글자수가 상당히 짧으면, 삭제하는 구문을 넣어봤다.
conn = pymysql.connect(host="XXXXXXXXXXX", port=XXXXX, user="root", password="root", db="XXXXXe", charset="utf8")
curs = conn.cursor()
removeShortTitle = "delete from bg_product_data where char_length(title) <= 8;"
curs.execute(removeShortTitle)
conn.commit()
conn.close()
이렇게 하면, title이 8글자 이하면 아예 삭제해버린다. 어차피 게시글이 8글자도 안되는 게시물은 없을 것이다... 아마.! ㅋㅋ