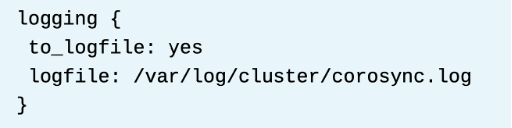
* pcs alert 유틸리티를 사용하여 클러스터 모니터링하기
클러스터 내의 모든 이벤트는 모니터링될 수 있다. 이벤트는 노드 시작, 리소스 실패, 클러스터 구성 변경 등이 될 수 있다. 클러스터 모니터링은 중요한데 왜냐면 이것은 클러스터 상태에 대한 정보를 제공하기 때문이다. 즉, 시스템 관리자는 일부 이벤트에 대하여 알림을 받을 수 있도록 모니터링을 해야한다. 예를들어, 노드가 fail 되면 클러스터가 메시지를 보내게 할 수 있다. 이렇게 하면 클러스터의 모든 문제를 인지하고 적절히 대응할 수 있다.
세세한 모니터링을 위해, High Availability Add-on은 pcs alert 라는 유틸리티를 제공한다. 이 유틸리티는 클러스터가 alert을 보내는 것을 호출하는 외부 프로그램, alert agents 라는 프로그램을 사용한다. alert agents 를 호출하면, 클러스터는 정보를 alert agents에 제공하기 위해 환경 변수를 사용한다. alert agents를 사용하기 위한 환경 변수에 대해 더 보려면 다음을 참고한다. (The Environment Variables Passed to Alert Agents table https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html-single/configuring_and_managing_high_availability_clusters/index#tb-alert-environmentvariables-HAAR)
alert agents 를 위한 스크립트 템플릿은 /usr/share/pacemaker/alerts 디렉토리에 있다. 시스템 관리자는 필요에 따라 이러한 템플릿을 그대로 쓰거나 수정해서 사용할 수 있다. 사용자는 또한 커스텀 alert agents를 만들 수 있다.
클러스터 alert 정의하기
pcs alert create 명령을 사용해서 클러스터 alert을 생성할 수 있다.

- path : alert agent script의 경로 (이 스크립트는 모든 노드에 동일한 위치에 있어야 한다)
- option : alert agent 스크립트에 환경 변수로 전달되는 에이전트별 구성 값이다.
- id : agent의 id 값. 만약 id 값을 정의하지 않았다면, pcs는 "alert-번호" 이런식으로 사용한다.
예를들어, 샘플 클러스터 alert인 myalert가 있고 이게 /usr/share/pacemaker/aperts/sample_alert.sh 파일을 실행한다면, 아래와 같이 명령어를 쓴다.

클러스터 alert 보기
pcs alert show / pcs alert config 두 명령어로 액티브된 클러스터 alert을 볼 수 있다. 두 명령어는 동일한 정보를 보여준다.

* 클러스터 alert 구성 변경하기
그리고 pcs alert update 명령으로 cluster alert의 옵션을 변경할 수 있다

클러스터 alert 제거하기
클러스터 alert의 제거가 필요할 때, pcs alert remove / pcs alert delete 명령을 사용한다. 둘다 동일한 동작을 수행한다.
예를들어, myalert 클러스터 alert을 제거하려면 아래처럼한다.

* 클러스터 alert 수신자 지정 구성하기
위에서 alert을 생성했으면, 해당 alert의 수신자를 지정한다. 지정하는 수신자는 alert agent의 유형에 따라 다르다. 예를 들어 email agent는 하나 이상의 이메일 주소로 alert을 보낼 수 있다. 파일에다가 이벤트를 기록하는 에이전트는, 하나 또는 하나이상의 파일을 수신자로 쓸 수 있다.
클러스터 alert의 수신자를 넣기 위해, pcs alert recipient add 명령을 사용한다.

예를 들어, 만약 위에 나온 sample_alert.sh 스크립트가 이메일을 보낸다고 했을 때, 구성은 이메일 주소를 수신자로 해야한다.
이미 만든 myalert 클러스터 alert에 대하여 이메일 수신자를 추가하려면, 아래처럼 수행한다.

동일한 클러스터 alert에 또 다른 이메일을 추가하려면, 동일한 에이전트에 대하여 다른 수신자를 만든다.

사용자는 또한 pcs alert recipient update 명령을 통해 클러스터 alert의 수신자를 수정할 수 있다. 수신자를 제거하려면, pcs alert recipient delete / pcs alert recipient remove 를 사용한다. 둘다 동일한 동작을 수행한다.
* mailto 알림 구성하기
시스템관리자는 일반적으로 알림은 어떤 유형의 클러스터 변경을 알려주기 때문에 유용하다고 생각한다. 예를들어, 리소스가 다른 노드로 마이그레이션될때의 알림은 노드의 장애가 있음을 알 수 있다. 리소스 그룹에 mailto 리소스를 추가하는 것은 이러한 알림을 받기에 간단한 방법이다. mailto 리소스는 리소스 그룹이 start/stop 할때 마다 수신자 주소로 등록된 이메일 주소로 이메일을 보낸다.
아래 예시에서, 사용자는 mailto 리소스를 importantgroup 리소스 그룹에 추가한다. 리소스는 admin@example.com 으로 이메일을 보내며, 제목 접두사에 중요 그룹 알림을 붙이고 그 뒤에 작업, 타임스탬프, 노드 이름을 붙인다.

mailto 리소스를 구성하였으면, 클러스터를 운영으로 넘기기 전에 mailto 리소스를 테스트해야 한다. 예를 들어 pcs resource move 명령을 사용하여 해당 리소스 그룹에서 리소스를 이동하여 리소스 그룹에서 MailTo 알림을 테스트할 수 있다.
* 클러스터 노드에서 mail-sending 구성
mail alert를 사용하는 mailto 리소스 에이전트 및 다른 리소스 에이전트는 dependency로서 모든 클러스터 노드에 mail transport agent (MTA, postfix이나 sendmail 등) 와 mail-sending 클라이언트가 설치하는것을 요구 한다. 이 예시는 구성이 간단하고 쉬운postfix를 사용하고, 또한 other user interface features 없이 커맨드라인으로의 메일 전송만 필요하기때문에 mailx를 사용한다. postfix 서비스는 enable 되어야 한다. 이러한 발신전용 요구사항에서는 추가적인 구성이 필요치 않다.

* 유저의 워크스테이션에서 메일 수신 구성
일반적으로, 사용자의 컴퓨터는 이미 메일 수신에 대한 구성이 되어있다. 만약, 여기 클래스 환경에서 구성되어 있지 않다면, workstation (실습시 사용하는) 에서 메일 컴포넌트가 설치되어야 한다. RHEL에서 SMTP 메일을 받도록 구성하려면, postfix MTA 를 설치하고 구성해야한다. 또한 사용하는 firewalld smtp 서비스 구성을 사용하여 SMTP 방화벽 포트를 오픈한다. postfix는 모든 네트워크 인터페이스에서 들어오는 메일을 수신하게 한다. 또한 postfix 서비스는 enable하여 자동으로 시작되게 한다.

실용적인 메일 읽는 프로그램을 구성하려면 mutt를 설치한다. Mutt를 처음 실행하면 메일 폴더를 만들라는 메시지가 표시된다. 이 폴더를 미리 폴더를 만들려면 루트가 아닌 mail user 로 mkdir을 사용하면 된다. 아래와 같이 명령을 실행한다. 여기까지 완료되면 클러스터에서 발신하는 메일을 받을 준비가 된다.

* References
mailx(1), mutt(1), pcs(8), and postfix(1) man pages
For more information, refer to the Triggering scripts for cluster events chapter in the Configuring and managing high availability clusters guide at
Knowledgebase: "Can we configure pacemaker cluster to send Email notification when a resource goes in stopped state ?" https://access.redhat.com/solutions/4210311
* 실습 : 메일 알림 구성하기 (mailto, alert)
(1) 메일 수신자 설정
우선 메일 받는 워크스테이션쪽에 아래 앤서블을 실행하여 설치 및 구성한다.

1. 이 플레이는 localhost 에서 실행한다.
2. 이 전체 플레이북은 로컬로 실행한다.
3. 첫번째 작업은 postfix랑 mutt를 설치한다.
4. 두번째 작업은 /home/student/Mail 디렉토리를 생성한다.
5. 세번째 작업은, inet_interfaces=all 파라미터를 설정한다.
6. 네번째 작업은, 방화벽을 준비한다.
7. 마지막 작업은, postfix 서비스를 enable하고 시작한다.

(2) mailto 구성
이제 각 노드에 구성하는 플레이북을 만들자.
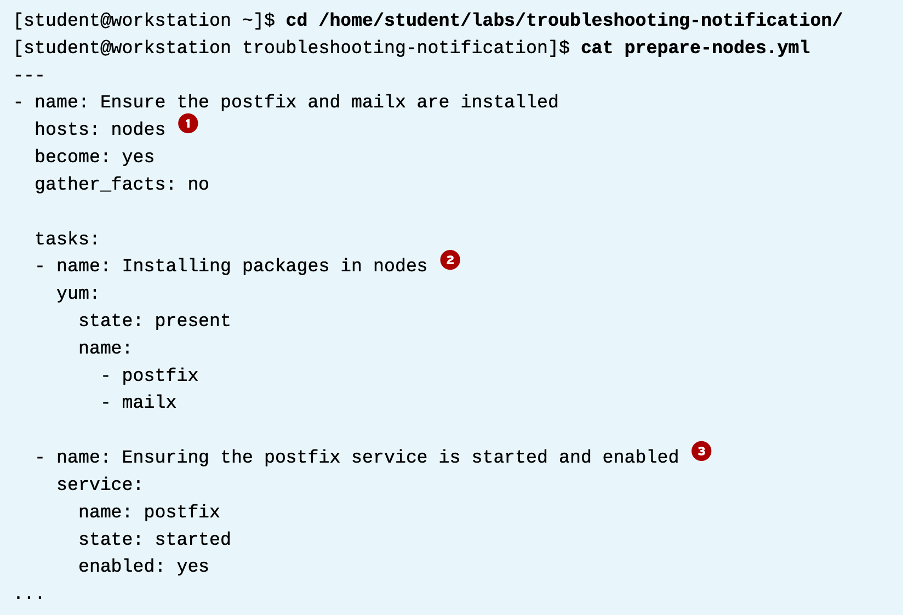
1. 플레이 타겟은 nodes 이다. 모든 노드들이다. 3클러스터 노드. 이 모든 작업은 3노드에 실행된다.
2. 첫번째 작업은 postfix랑 mailx를 설치한다.
3. 마지막 작업은 postfix서비스를 enable한다.

이제 mailto 리소스를 구성해본다.


리소스명은 webmail 이고, firstweb 그룹에 들어간다. 이게 트리거되면, 제목은 CLUSTER-NOTIFICATION 이 들어가고, student@workstation.lab.example.com 으로 메일을 보낸다.
내 workstation 머신에서, mutt를 student 유저로 실행해서 생성된 메시지를 본다. 제목이 CLUSTER-NOTIFICATION 인지 확인한다. 클러스터가 해당 리소스 그룹을 relocate, stop, start 할때 메일이 오는지 확인한다.

(3) alert 구성
alert agent를 설치하고, 이 에이전트를 사용하여 클러스터 이벤트를 이메일 메시지로 를 이메일 메시지로 보내도록 alert 를 구성할 수 있다. 구성값은 다음과 같다.
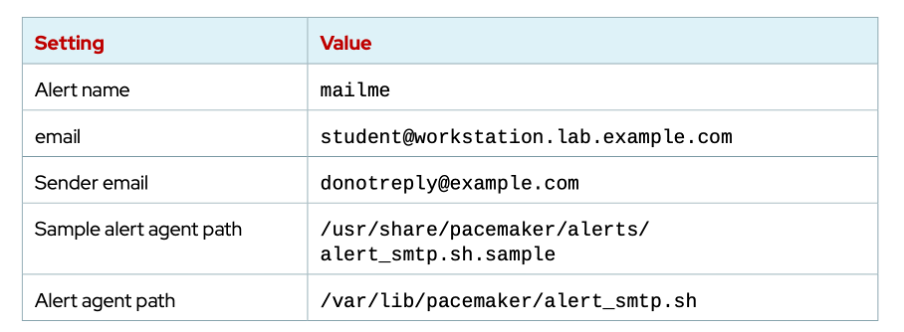
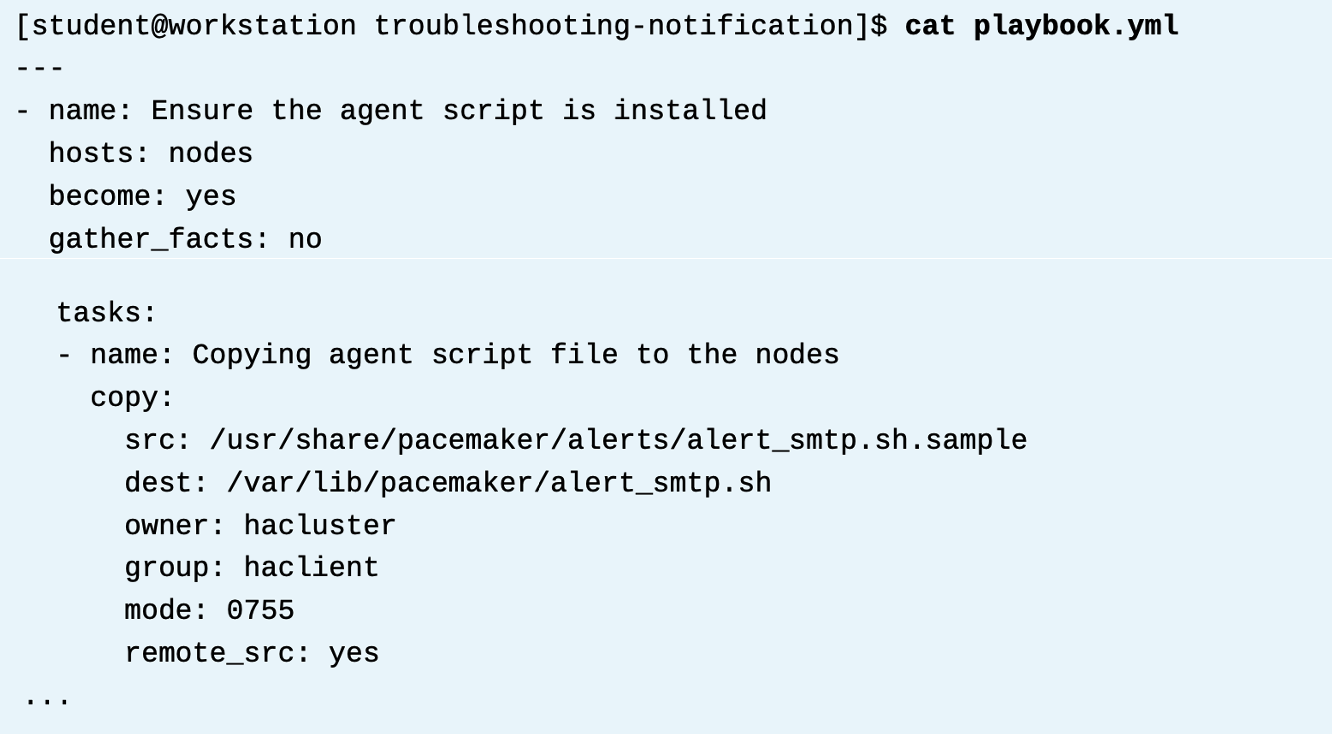
이것도 플레이북으로 만든다. (예시에서는 이미 파일이 존재함)


이제 alert agent를 구성한다. 위 테이블에 있는 세팅값을 사용한다.

이메일 수신자를 지정한다.

생성된 alert을 본다.

firstweb 리소스 그룹을 수동으로 이동해서 알림이 오는지 보자. 또한 nodec에서 네트워크 통신에 문제를 일으켜 펜스되면 또 메시지가 어떻게 오는지 보자.

nodea 에서, pcs status 로 상태를 보자. nodec 가 다시 클러스터 조인되는것도 보자. 기다리면 노드c는 재시작되어 조인된다.

이제 workstation에서 메시지들을 보자. 타임스탬프로 시작하고 cluster1: resource operation 텍스트가 포함된 제목이 있는 이메일 메시지를 살펴본다. 이러한 이메일은 클러스터 및 클러스터 리소스에 대한 변경 사항을 알려준다.
'High Availability > RH436 & EX436' 카테고리의 다른 글
| [RH436/EX436] 13. 클러스터 로그 분석 (0) | 2024.02.09 |
|---|---|
| [RH436/EX436] 12. Quorum (0) | 2024.02.08 |
| [RH436/EX436] 11. SPoF, 클러스터 링크 추가, Fence Level 구성하기 (1) | 2024.02.08 |
| [RH436/EX436] 10. GFS2 Filesystem (1) | 2024.02.07 |
| [RH436/EX436] 9. High Availability 클러스터의 2가지 LVM 구성 방식 (0) | 2024.02.07 |