* 쿼럼이란?
클러스터가 기대한대로 작동하기 위해서, 노드들은 특정 사실에 대해 동의해야만 한다. 예를들어 어떤 서버들이 현재 클러스터 멤버인지, 어디서 서비스가 실행중인지, 어떤 머신이 어떤 리소스를 쓰는지 등. 이런 사실에 동의를 해야만 한다. High Availability Add-on은 다수결 투표 방식을 사용하여 이 방법을 구현한다. 현재 corosync 네트워크 통신에 성공적으로 참여하고 이미 클러스터에 조인되어 있는 다른 노드와 통신이 가능한 노드는 한 표를 던질 수 있다. 절반 이상의 투표가 던져지는 경우 클러스터는 정상적으로 작동한다.
과반수가 달성되기 위해 필요한 최소의 수를 쿼럼이라고 한다. 만약 쿼럼이 달성되면, 클러스터는 quorate 상태(정족수를 달성한 상태)라고 간주된다. 만약 절반이상의 노드들이 서로 커뮤니케이션 할 수 없는 경우, 클러스는 쿼럼을 잃게 된다.
클러스터가 시작될 때, 모든 클러스터 노드는 서로 통신을 하려고 시도하며, 쿼럼을 얻는데 초점을 맞춘다. 과반수가 형성되는 즉시, quorate 클러스터가 된다. quorate 클러스터에 성공적으로 조인되지 못한 다른 모든 노드들은 쿼럼을 가진 노드 중 하나에 의해 펜스당한다. 또한 quorate 클러스터에 조인되어 있는 노드가 더 이상 클러스터와 통신하지 못하게 되는경우, 해당 노드도 펜스당한다.
* 왜 쿼럼 계산이 필요한가?
클러스터에 있는 어떤 노드(들)이/가 특정 다른 노드들과 통신이 안되는 경우의 상황에서 쿼럼이 필요하다. 아래 그림은 5노드 클러스터를보여준다. 노드 1,2,3,4,5 가 있다. 그리고 ext4 파일시스템 공유스토리지를 서비스하고 있다. 해당 서비스는 노드1에서 실행중이다.
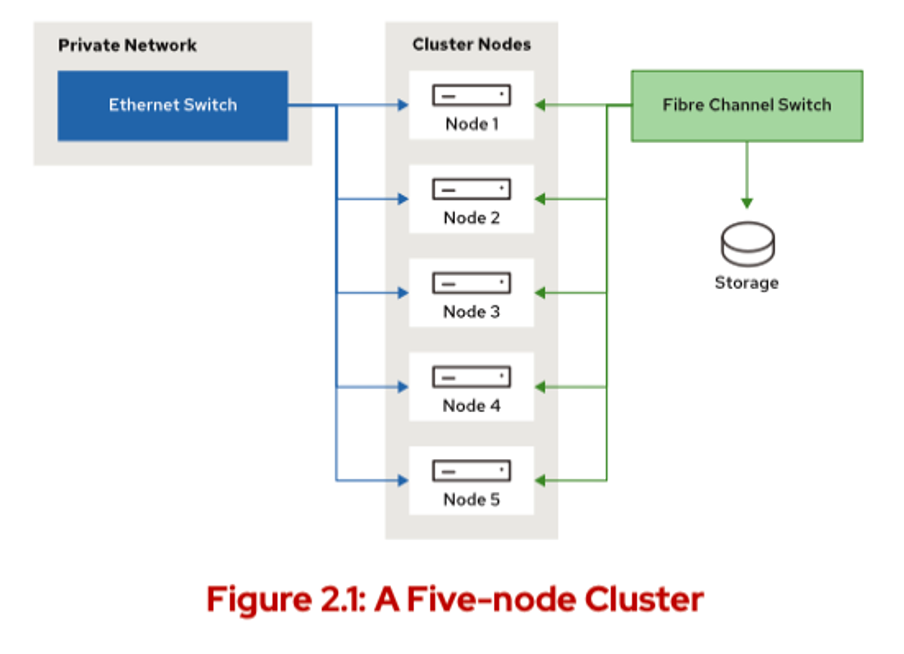
여기서, 노드4랑 노드5가 메인 프라이빗 네트워크에서 단절되고, 노드1,2,3과 통신이 안된다고 치자. 쿼럼이 없다면, 노드4,노드5. 두 노드는 노드1,2,3 세 노드가 모두 죽었다고 판단하고 리소스를 복구할 수 있도록 펜싱을 해야한다. 이런식으로, 쿼럼은 펜싱에 앞서 중요한관문의 역할을 한다.
클러스터에 펜싱 장치가 없으면 노드4,5는 즉시 리소스를 복구하여 동일한 ext4 파일시스템을 한번에 두 곳에 마운트하는데 이는 정상적인 상황이 아니다. 클러스터의 두 반쪽이 서로 독립적으로 작동하는 이러한 상황을 split-brain 이라고 한다. Split-brain 은 2노드 클러스터에서 특별히 문제가 되는데, 어느 한 노드가 죽으면 다른 노드는 클러스터 노드의 과반수로 구성이 되지 않기 때문이다.
이 예시에서, 모든 노드가 하나의 투표를 가진다면, 노드4와 노드5는 총 투표권 5개의 반을 넘지 못하는 2개이므로 위와 같은 상황은 발생할 수 없다. 이 상황에서 노드4,5는 다른 투표수가 하나 더 추가될때까지 작동을 멈추게 된다. 반면에 노드1,2,3은 총 투표의 절반이상인 3표를 가지므로 서비스를 계속 제공할 수 있게 된다.
* 쿼럼 계산하기
쿼럼은 corosync 컴포넌트인 votequorum에 의해 계산되고 관리된다. votequorum 컴포넌트는 클러스터가 quorate인지 계산하기 위해 2개의 값을 사용한다.
- expected votes : 모든 클러스터 노드가 정상작동하고 서로 잘 통신하고 있는 상태에서 기대되는 투표의 개수
- total votes : 현재 존재하는 투표 총 수. 만약 어떤 노드가 올라오지 않았거나, 클러스터와 통신이 안된다면
이 값은 expected votes 보다 작을 수 있다.
쿼럼을 달성하기 위해 필요한 투표의 개수는 expected votes 를 기준으로 한다. 아래 계산식은 쿼럼을 달성하기 위해 얼마나 투표가 필요한지 수를 보여준다. 이 계산에서, floor()는 항상 반내림한다.

3노드 클러스터의 경우 예시
아래 예시에서, 3노드 클러스터를 가정한다. 3노드 클러스터의 expected votes 는 3이다. 3노드 클러스터에서, 쿼럼을 달성하려면 최소2노드어야야 한다.

4노드 클러스터의 경우 예시
4노드 클러스터의 expected votes 는 4이다. 4노드 클러스터에서, 쿼럼을 달성하려면 최소 3노드여야 한다.

* 쿼럼 상태 확인하기
High Availability Add-on은 클러스터의 쿼럼 상태를 포괄적으로 보여주는 명령어를 제공한다. 이 명령은 pcs quorum status 이다. 이 명령은 쿼럼 관계된 정보들의 개요를 보여준다. total votes, expected votes 등등의 정보를 보여준다. 그리고 현재 쿼럼을 달성했는지 한눈에 보여준다.

1. 클러스터에 있는 노드의 수
2. pcs quorum status 명령을 친 노드의 node ID
3. 클러스터가 쿼럼을 달성했다면, yes 라고 나옴.
4. 만약 클러스터 내에 모든 구성된 클러스터 멤버가 활성화되어있다면, 현재 존재하는 투표의 수를 보여준다.
5. The Highest expected entry shows the largest value of expected votes that corosync could see at the last transition and is always expected to be the same as Expected votes.
6. 클러스터 내에서 현재 존재하는 투표 수
7. 클러스터가 쿼럼을 달성하기 위해 최소 필요한 수
8. 플래그 항목에는 클러스터에 현재 설정되어 있는 쿼럼 관련 속성이 표시된다. 클러스터가 정족수 상태인 경우 Quorate 속성이 표시된다. LastManStanding 또는 WaitForAll과 같은 추가 특수 기능이 설정되어 있으면 이 필드에 표시된다.
* 실습 : 쿼럼 작업 살펴보기
아래 명령으로 현재 상태를 본다.

아래와 같이 방화벽을 막아버려서, 노드c 가 클러스터와 통신을 못하게 하자.


이건 쉘 파일로 만들어놓은 막아놓는 룰이다.
이렇게 하면, 다른 노드들이 해당 노드c에 연결할 수 없기 때문에, 클러스터는 노드c를 펜스한다.
이제 상태를보자

기대되는 투표는 4개이나 실제 투표는 3개이다. 노드도 3개로 확인된다. 또한 아래 멤버쉽 정보에서도 해당 노드가 나오지 않는다.
기다리면 nodec가 살아나서 조인될것이며, 다시 정상화된다.
다른 테스트를 해보자. 노드b,c를 아예 꺼버린다.

참고 : 클러스터는 위 두 노드는 펜스하지 않는다. 왜냐면, gracefully 하게 셧다운 했기 때문이다. 클러스터는 unexpectedly unresponsive node만 펜스한다.
노드a에서 아까 watch pcs quorum을 하고 있었는데, 보면 아래처럼 나온다.

이 명령어는 더이상 작동하지 않는다. 왜냐면, 클러스터가 쿼럼을 잃었기 때문이다.
그러나, 사용자는 여전히 corosync-quorumtool 명령은 사용이 가능하다. 아래처럼 명령어를 쳐보자.

여기 보면 quorum이 activity blocked 라고 나와있다. 클러스터는 활동을 막은 상태이다. 왜냐면 4 노드 클러스터는 3개의 투표가 필요한데 지금 2개만 있기 때문이다. 리소스 손상을 방지하기 위해, 클러스터가 클러스터 리소스에 대한 시작/중지/리소스를 건드리는 작업등에서 quit 하게 된다.
노드b를 켜고 다시 상태를 보자. 다시 pcs quorum status 를 쳐서 상태를 보자. 기다리면 노드b가 조인되므로, 다시 쿼럼을 얻었다 근데 아직 여전히 하나는 노드가 없다.

* 쿼럼 계산 옵션들
위에서 설명한 기본적인 쿼럼 계산 옵션을 변경할 수 있다. votequorum 컴포넌트는 쿼럼 계산을 수정하는 방법을 가진 쿼럼 옵션을 줘서 클러스터를 만들 수 있게 허용한다. pcs cluster setup 명령을 줄 때, 아래 쿼럼 옵션을 줘서 클러스터 내에서 쿼럼의 행동을 변경할 수 있다. 이러한 쿼럼 옵션들은 새 클러스터 생성시 조합할 수 있고 또한 생성된 클러스터에서 변경할 수도 있다. 아래는 새 클러스터 생성시 예시이다.

* wait_for_all=1
쿼럼 계산을 시작하기 전에 모든 클러스터 구성원이 온라인 상태가 될 때까지 기다린다. 이 설정은 클러스터가 시작될 때 fence race을 효과적으로 방지한다. 이 설정을 사용하지 않으면 클러스터에 참여하지 않았거나 깨끗하게 종료되지 않은 모든 노드는 쿼럼이 달성되는 즉시 자동으로 펜싱됩니다.
* auto_tie_breaker=1
기본 50% + 1표가 아닌 클러스터 노드의 50%만 참여해도 쿼럼을 달성할 수 있다. 50% 대 50%의 split brain 상황의 경우, 가장 낮은(lowest) node ID가 참여하는 쪽이 쿼럼을 얻는다. 추가적으로, auto_tie_breaker 옵션과 last_man_standing 을 사용하면, 클러스터를 one node로 다운그레이드 시킬 수 있다.
* last_man_standing=1
default 로, 10초마다 expected votes가 다시 계산된다. 이를 통해 시스템 관리자는 클러스터에 활발하게 참여하는 노드가 두 개만 남을 때까지 클러스터 노드를 하나씩 클러스터에서 연결 해제할 수 있다. 클러스터 노드의 연결을 너무 빨리 끊으면 두 개 이상의 노드가 작동 중임에도 불구하고 쿼럼이 손실될 수 있다. 또한 last_man_standing=1은 여러 파티션들(클러스터의 하위집합(subsets))이 동시에 쿼럼을 요청하는것을 막기 위해 또한 wait_for_all도 같이 사용해야 한다.
* last_man_standing_window=10000
시스템 관리자는 이 값을 사용하여, 클러스터 내에서 한 노드가 참여하는것을 중단할 때 expected votes가 재계산될때까지의 시간(밀리세컨드) 을 변경하도록 할 수 있다. - 디폴트값은 10000 밀리세컨드 (10초) 이다.
* 존재하는 클러스터에서 쿼럼옵션 변경하기
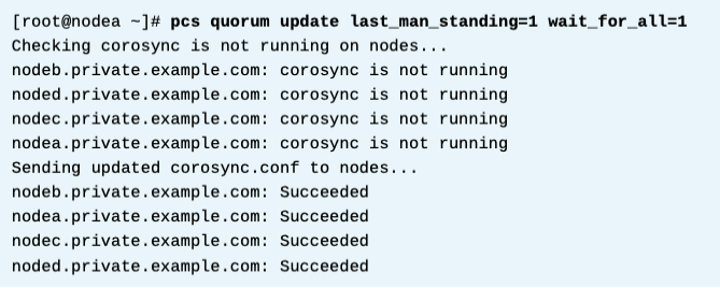
클러스터 쿼럼 계산은 기존 클러스터에서도 영향을 받을 수 있다. 쿼럼 옵션 변경시 클러스터를 다시 시작하여 corosync가 새 구성을 적용하게 하기 위해 운영 중인 클러스터는 다운타임이 필요하다. pcs cluster stop --all로 클러스터를 중지하고, pcs quorum update명령으로 쿼럼 옵션을 수정할 수 있다. 다음 예제에서는 last_man_standing, wait_for_all 및 auto_tie_breaker 옵션을 사용하도록 설정한다.

새로운 옵션이 활성화되고 시작된 클러스터는 아래처럼 flags 부분이 변경된 것을 확인할 수 있다. 또한 pcs quorum config 명령으로도 확인 가능하다.

또한 클러스터의 쿼럼 관련 옵션이 있는 구성 파일은 /etc/corosync/ corosync.conf 이다. 모든 쿼럼 관련 옵션은 쿼럼 지시어에 설정된다. 이 구성파일은 모든 클러스터 내 노드끼리 동일해야 한다.

구성 변경 관련하여 Redhat은 pcs quorum update 를 권고한다. 이 명령은 이 corosync.conf 파일을 명령어를 친 서버에서 먼저 업데이트 하고, 클러스터가 멈춰있다 하더라도 자동으로 다른 모든 노드와 동기화를 시킨다. corosync.conf 파일을 수동으로 수정할 수도 있다 (레드햇은 권장하지 않음) 이 경우 pcs cluster sync 명령으로 모든 노드에다가 해당 파일을 복제해야만 한다. 그 후 클러스터를 시작한다.
* References
votequorum(5) , corosync-quorumtool(8) man page
For more information, refer to the Cluster quorum chapter in the Configuring and managing high availability clusters at
For more information, refer to the Cluster quorum chapter in the Configuring and managing high availability clusters guide at
* 실습 : 클러스터에 새로운 쿼럼 옵션 넣기 , last man standing 옵션 확인
아래처럼 현재 아무 옵션도 없음.

클러스터 전체를 내린다.

옵션을 추가한다.
다시 클러스터 시작

구성 확인

이제 nodec 를 끄고 클러스터가 degrade 되는걸 확인한다.

이거 켜놓고 노드c 를 끈다.

다시 pcs quorum status 명령 실행되고 있는 곳으로 간다.
nodec 가 죽고 10초 후에, 클러스터는 expected votes를 4에서 3으로 바꾼다.
따라서 클러스터는 쿼럼값도 2로 다시 계산한다.
노드가 정상적으로 클러스터를 떠나면, 클러스터는 위와 같은 식으로 동작하게 되는 것이다.
또한 사용자는 클러스터가 쿼럼을 다시 계산하는데 있어 대기 시간을 제어하기 위해 last_man_standing_window 옵션을 사용할 수 있다. 기본값은10초 (10000밀리초) 이다.

노드d도 끈다.

이제 pcs quorum status 를 보면, 노드d stop 작업을 한 후 10초 후에 클러스터는 expected vote를 3에서 2로 줄인것을 알 수 있다.

만약 last_man_standing 옵션을 활성화하지 않았따면, 클러스터는 두번째 노드가 죽었을 떄 쿼럼을 달성하지 못했을 것이다.
기본적으로 4노드 클러스터는 쿼럼을 얻기 위해 3개의 노드가 작동해야 된다는 것을 기억해야 한다.
일반적으로, 클러스터가 쿼럼 상태를 유지하려면 최소 2개의 노드가 작동해야 하므로, quorum 값은 1로 줄어들지 않는다.
디폴트로 클러스터는 하나의 노드로 작동하는것을 허용하지 않기 때문에, quorum 값은 1이 될수가 없다.
남은 노드가 하나만 있는 상태에서 계속 작동하는 2노드 클러스터를 만들 수 있는 구성은 따로 있다.
'High Availability > RH436 & EX436' 카테고리의 다른 글
| [RH436/EX436] 14. 클러스터 알림 구성 (4) | 2024.02.09 |
|---|---|
| [RH436/EX436] 13. 클러스터 로그 분석 (0) | 2024.02.09 |
| [RH436/EX436] 11. SPoF, 클러스터 링크 추가, Fence Level 구성하기 (1) | 2024.02.08 |
| [RH436/EX436] 10. GFS2 Filesystem (1) | 2024.02.07 |
| [RH436/EX436] 9. High Availability 클러스터의 2가지 LVM 구성 방식 (0) | 2024.02.07 |