* 단일 장애 지점(SPoF) 이란?
Single Point of failure (SPoF) 는 복잡한 설치의 특정 부분이 장애가 나면, 전체 환경이 박살나는 그 부분들을 말한다. 메탈 체인이 하나라도 망가진다면 전체 체인이망가진다.일반적인 HA 클러스터는, 여러 SPoF 가 있을 수 있다. 아래는 일부의 예시이다.
하드웨어 SPoF
| 파워 서플라이 | 서버가 파워를 잃으면 꺼진다. 일반적으로 파워2개를 사용하며, 또한 UPS를 사용한다. 이것은 주요 공급자가 다르고, 적어도전기 그룹이 서로 다르다. 큰 데이터센터에서는 긴급전원을 제공하는 백업 발전기가 있는경우도 있다. |
| 로컬 스토리지 | 디스크가 죽으면, 전체 장비가 죽는다. 일반적으로 레이드를 구성한다. |
| 네트워크 인터페이스 | 네트워크 카드가 죽으면 안되므로, 본딩을 사용한다. 서로 다른 카드로 구성해야 한다. |
| 네트워크 스위치 | 스위치를 2개 두고 각 스위치에 연결된 본딩된 nic를 사용한다. |
소프트웨어 SPoF
| 클러스터통신 | RHEL HA 클러스터는 모든 노드간의 지속적인 커뮤니케이션에 의존한다. 만약 이러한 커뮤니케이션이 방해받으면, 클러스터는 노드를 죽일지고민한다. 이를 막기 위해 클러스터간 커뮤니케이션을 경로를 이중화한다. |
| 공유스토리지연결 | 노드가 공유스토리지와의 연결리 끊기면, 더이상 고객에게 혀과적으로 서비스를 제공할 수 없다. 멀티패스가 되어있는 HBA 스토리지라면, 이중화가된다. iSCSI의 경우 멀티패스 지정과 함께 여러(본드된) 네트워크 인터페이스를 사용하여 서로 다른 네트워크에서 동일한 target으로 그인할 수 있다. (패스를 여러개 만들고 각 패스가 본딩되어 있음) 또한 공유 스토리지 백엔드는 RAID 1,5와 같은 중복 스토리지 형태를 사용한다. |
| 소프트웨어Fence 구성 | 노드당 여러 개의 펜싱 디바이스가 동시에 사용하도록 구성된 경우, 노드당 여러 개의 펜싱 디바이스를 보유하는 것은 의미가 없어진다. (동시에 사용하므로) 한 장치에 장애가 발생하면 클러스터는 여전히 펜싱이 실패한 것으로 간주한다. 이러한 펜싱 실패를 방지하기 위해 펜싱 장치를 펜싱 레벨에 할당할 수 있습니다. 첫 번째 수준의 펜싱 장치가 실패하면 클러스터는 두 번째 수준을 시도하게 된다. |
* Network Redundancy 를 통해 클러스터 가용성 높이기
corosync는 corosync의 네트워크 통신 레이어에서 kronosnet (또는 knet) 에 의존한다. knet은 클러스터 커뮤니케이션에 있어서 추상화 레이어에서 이중화와 보안을 제공한다. knet, corosync를 함께 사용하여 최대 8개의 분리된 네트워크에서 노드간 통신을 설립할 수 있다. 하나의 네트워크가 죽으면, 커뮤니케이션은 다른 남아있는네트워크에서 지속된다. knet은 각 서로 다른 서브넷을 가진 네트워크 링크를 요구한다. 만약 동일한 서브넷에서 여러개의 네트워크 인터페이스를 사용하려면 그대신 티밍을 사용해야 한다.
Red Hat은 크로스오버 이더넷 케이블을 사용하여 두 시스템을 다이렉트로 연결하는 것을 지원하지 않는다. 또한 Red Hat은 일반적인 클러스터 사용시 여러개의 네트워크 연결을 지원하지만, DLM을 사용할 때 하나의 네트워크 연결만 지원합니다. 이 제한은 lvmlockd, LVM 공유 볼륨 그룹 및 GFS2 모두 DLM에 의존하기 때문에 이것들 모두 적용됩니다.
클러스터를 관리하기 위해 사용하는 pcs명령과 이것과 연관된 pcsd 데몬은 knet을 사용하지 않는다. 이 노드는 클러스터를 만들 때 지정한 노드 이름과 연결된 네트워크를 통해 pcs host auth 및 pcs cluster setup 명령으로 통신한다. 해당 네트워크가 장애나면, pcs 명령은 더이상 작동하지 않는다. 클러스터가 여전히 잘 작동하고 있고, 그것이 여러개의 knet 링크 때문이라 하더라도, pcs. 명령은 더이상 작동하지 않는다. pcs 명령이 사용되는 네트워크를 보호하려면, teaming을 사용해야 한다.
여러개의 링크와 함께 클러스터 구성하기
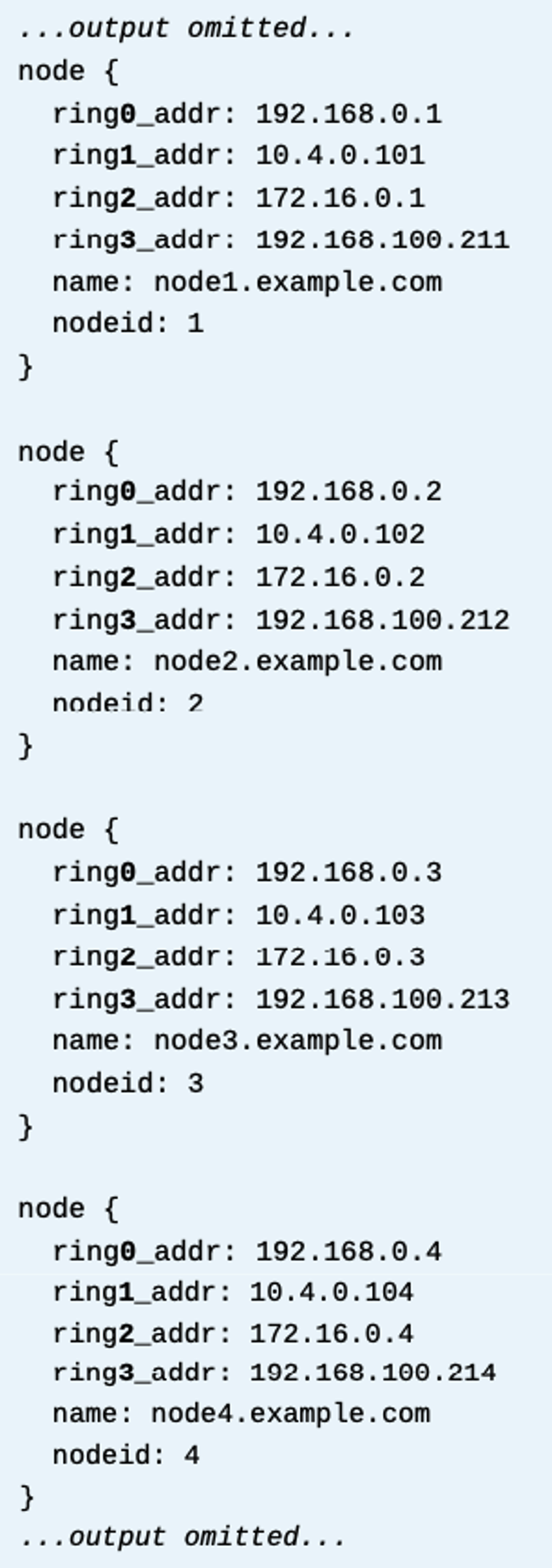
pcs cluster setup명령으로 새로은 클러스터를 만들때, 각 서버의 사용할 링크 서브넷의 ip주소를 제공하면 여러개의 링크를 구성할 수 있다. 아래 예시는, 네개노드 클러스터이고, 3개의 통신링크를 만든다. 192.168.0.0/24 , 10.4.0.0/16 , 172.16.0.0/16 서브넷이다. addr 옵션을 각 노드 이름 뒤에 사용하여 각 서브넷들을 제공한다.

존재하는 클러스터에 링크 추가하기
pcs cluster link add 명령으로 존재하는 클러스터에 링크를 추가할 수 있다. 사용자는 꼭 각 노드의 새로운 서브넷의 ip주소를 제공해야 한다. 아래예시는 192.168.100.0/24 대역의 링크 하나를 4개 노드 클러스터에 더하는 것이다.

링크 구성 정보 확인
클러스터는 링크 구성 정보를 /etc/corosync/corosync.conf파일에 저장한다. 아래 예시는 각 클러스터 노드가 링크들을 보여주는 섹션이 있는걸알려준다. 클러스터는 유니크 링 넘버로 각 링크들을 식별한다. 위 예시에서는 0~3까지이다. 0,1,2,3
클러스터에서 링크 삭제하기
링크를 제거하기 위해서는 pcs cluster link remove 링번호. 명령을 사용한다. 아래 예시는 링 넘버 3 (192.168.100.0/24)를 삭제한다.

로그상에서 링크 다운 확인하기
트러블슈팅을 위해, /var/log/cluster/corosync.log파일에서 링넘버등을 확인할 수 있다. 아래 예시는 로그에서 해당 링크가 다운된것을 보여준다. 위corosync.conf 파일대로라면, 해당 링은 링크1인 호스트2가 문제가 있다는것을 확인할 수 있다.

* 실습 : 클러스터 통신에 대한 네트워크 이중화 구성
노드는 a,b,c 3노드이다. 클러스터 구성 전 작업은 모두 되어있다. (방화벽, pcsd 등)
노드a 에서, 아래 확인
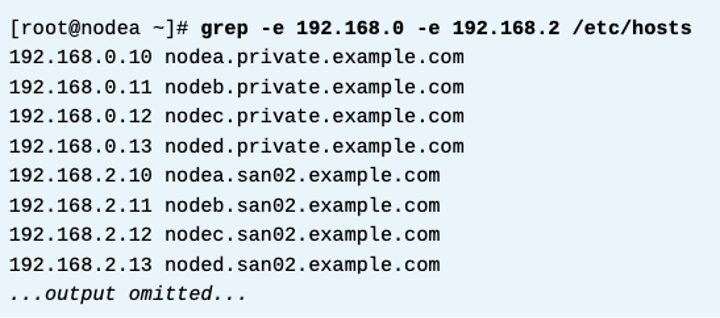
클러스터 만들때 리던던트 통신 채널을 함께 만든다.
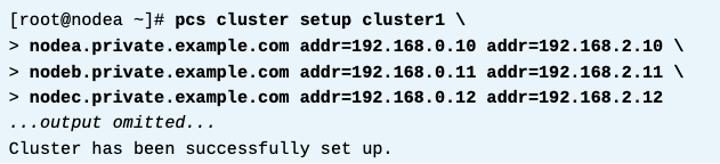
클러스터 시작 및 enable

클러스터가 이런식으로 구성되어 있다. (펜스 부분은 skip)

이제 192.168.2.0/24 대역을 쓰는 네트워크를 확인하자.

해당 네트워크를 끊는다.

다시 상태를 본다. 멀쩡하다

corosync 로그를 본다. 링크1이 죽어서 호스트 2,3이 다운된걸 확인할 수 있다.
(호스트1은 현재 이 노드a 이다. 로그는 항상 주관 적이므로)

corosync 파일을 본다.

* Fencing Level 만들기
여러 레벨의 펜싱 구성
단일 노드에 여러 개의 펜스 장치를 사용할 수 있는 경우 계층화된 토폴로지로 구성할 수 있다. 예를 들어, IPMI over LAN 및 APC by Schneider Electric(이전의American Power Conversion Corporation) 네트워크 전원 스위치 장치를 사용할 수 있는 환경에서 클러스터는 먼저 fence_ipmilan 펜싱 에이전트를 시도할 수 있다. 이후 실패하면 클러스터는 APC 전원 스위치에 액세스하여 노드의 전원을 끄는 fence_apc 펜싱 에이전트를 사용할 수 있다.
이러한 유형의 이중화 펜싱은 펜싱 레벨로 stonith 리소스를 구성하여 구현할 수 있다. 클러스터는 1부터 시작하는 순차 번호로 각 펜싱 레벨을 식별한다. 클러스터가 노드를 펜싱할 때, 먼저 레벨에 추가한 순서대로 레벨 1에 있는 모든 펜싱 장치를 사용하려고 시도한다. 모두 성공하면 클러스터는 노드가 펜싱된 것으로 간주하고 거기서 멈춘다. 그러나 펜싱 장치 중 하나라도 실패하면 클러스터는 해당 레벨의 처리를 중지하고 레벨 2의 펜싱 장치로 계속 진행하는 식으로 계속 진행한다.
Fencing Level 만들기
펜싱 레벨을 추가하기 전에, 모든 stonith 리소스를 구성해두어야 한다. 다 되었다면, pcs stonith level add 레벨 노드명 장치명 을 사용한다. 아래 예시는 2개의펜스레벨을 노드1에 대하여 지정한다.

Fencing Level 관리하기
pcs stonith level 명령으로 레벨 볼 수 있다.

Fencing Level 제거하기
클러스터 노드에 대한 레벨을 제거하기 위해서는 pcs stonith level remove 레벨 노드 명령을 사용한다.

클러스터 노드의 모든 레벨을 제거하기 위해서는, pcs stonith level clear 노드명 을 사용한다.
노드 이름을 제공하지 않으면, 모든 노드의 모든 펜스 레벨이 제거된다.

장비를 더 추가하기
pcs stonith level 명령은 현재 존재하는 펜스 레벨에 노드를 추가하는것은 제공하지 않는다. 노드를 더하기 위해서는, 전체 레벨을 삭제하고 다시 만들어야 한다.
* Redundant 파워 서플라이 펜싱 구성하기
신중한 구성이 필요한 일반적인 설정은 중복 전원 공급 장치가 있는 노드에 전원 펜싱을 적용하는 것이다. 펜싱 프로세스 중에 클러스터는 노드를 효과적으로 펜싱하기 위해 두 전원 공급 장치에서 전원을 제거해야 한다.

중복 전원 공급 장치로 노드를 올바르게 펜싱하려면 전원 공급 장치당 하나씩 스토니스 리소스를 생성한 다음 동일한 펜스 레벨에 추가한다. 한 레벨에 여러 장치를 추가하려면 pcs stonith level add 명령에 쉼표로 구분된 STONITH 리소스 목록을 입력한다. 다음 예는 node1 머신을 펜싱하기 위해 두 개의 STONITH 리소스를 생성한다. . 해당 머신에는 두 개의 APC 전원 스위치에 연결된 두 개의 전원 공급 장치가 있다. STONITH 리소스는 fence_apc 에이전트를 사용하여 이 두 전원 스위치를 주소 지정한다. 마지막으로, 마지막 명령은 두 리소스로 펜스 레벨 1을 생성한다.

동일한 레벨에서 stonith 리소스를 추가하면 클러스터는 먼저 모든 서버에 대해 "off" 동작을 수행한 다음 모든 서버에대해 "on" 동작을 실행한다. 이 동작은 특정 시점에 모든 노드의 전원이 꺼지도록 보장하여 노드를 효과적으로 펜싱한다. Red Hat Enterprise Linux 7.1 및 이전 버전에서는 클러스터가 이러한 방식으로 작동하지 않으며 더 복잡한 구성이 필요하다. 상세 추가 정보는 다음 링크를 참고할 것. Knowledgebase: "How can I configure fencing for redundant power supplies in a RHEL 6 or 7 High Availability cluster with pacemaker?" [https://access.redhat.com/solutions/1173123] for more information.
* 실습 : 여러 펜스 디바이스 레벨 만들기
현재 펜스구성 확인

이미 클러스터에는 fence_ipmilan 으로 펜스를 구성해둠.
클래스룸에는 두번째 펜스장치를 할 디바이스를 제공함. fence_rh436을 쓸것임.


pcmk_host_map 파라미터에는 노드와 , 그에 연관된 플러그 넘버를 적는다. 타임아웃은 180초이며 power_timeout 파라미터를 사용한다.
추가된 상태를 보자.



이렇게 하면 클러스터가 노드a를 펜스해야 할떄, 첫번째로 fence_nodea를 쓰고, 이게 페일되면 그다음 fence_classroom을 쓴다.
다른 노드에서 반복하자.

결과를 보자.

2번펜싱레벨을 쓰는지 보자.
IP 설정을 broke.example.com으로 변경하여 의도적으로 fence_nodec 펜스 장치의 구성에 문제를 일으킨다.
완료되면 nodec 머신에 펜싱을 시도한 다음 클러스터가 머신을 성공적으로 펜싱했는지 확인합니다.

상태먼저 보자
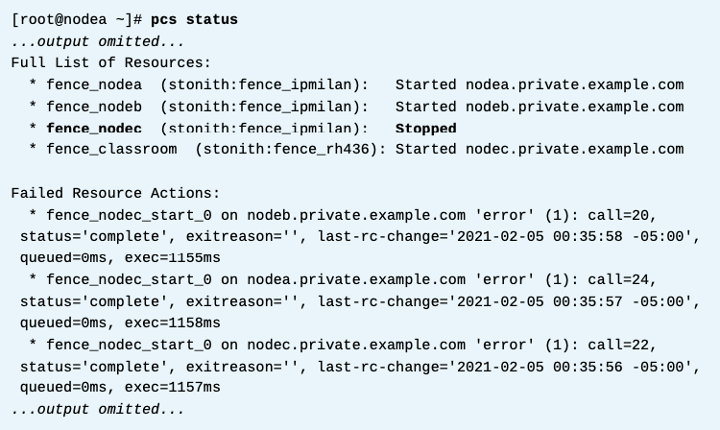
펜싱을 날려보자

클러스터가 성공이라고 한다. 첫번째 레벨은 안됐지만 두번째 레벨을 진행해서 성공한것이다.
* References
corosync.conf(5) man page
Knowledgebase: "Support Policies for RHEL High Availability Clusters - Cluster Interconnect Network Interfaces"
https://access.redhat.com/articles/3068841
For more information, refer to Creating a high availability cluster with multiple links section in the Configuring and managing high availability clusters guide at
For more information, refer to the Configuring fencing levels section in the Configuring and managing high availability clusters guide at
'High Availability > RH436 & EX436' 카테고리의 다른 글
| [RH436/EX436] 13. 클러스터 로그 분석 (0) | 2024.02.09 |
|---|---|
| [RH436/EX436] 12. Quorum (0) | 2024.02.08 |
| [RH436/EX436] 10. GFS2 Filesystem (1) | 2024.02.07 |
| [RH436/EX436] 9. High Availability 클러스터의 2가지 LVM 구성 방식 (0) | 2024.02.07 |
| [RH436/EX436] 8. LVM Basic (1) | 2024.02.07 |