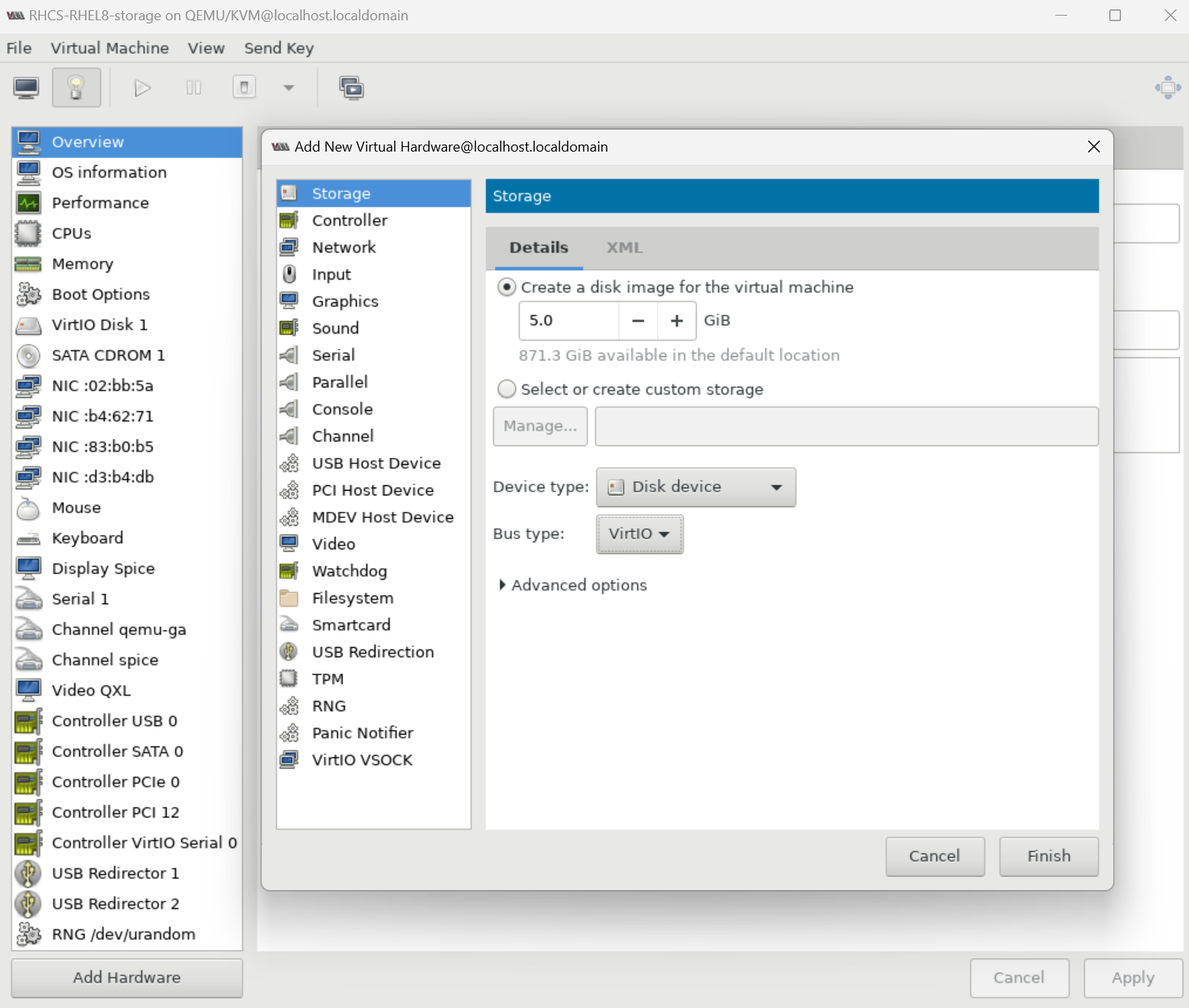
qemu-kvm : 호스트와 게스트 가상 머신간의 통신을 가능하게 하는 package qemu-img : 게스트 가상머신에 disk management를 제공 virt-install : 가상 머신을 생성하기 위한 virt-install command를 제공 virt-manager : 가상 computer 를 관리하기 위한 virt-manager 도구를 제공하며 graphic 도구 libvirt-client : 명령행 또는 가상화 쉘에서 가상시스템과 hypervisor 를 관리하고 제어하는 virsh command-line tool 이 포함됨.
- 참고로, 위 yum 명령을 수행하기 위해 레포지토리 등을 구성해야 하나, 이 부분은 여기서 설명하지 않는다.
location constraint를 사용하여 특정 노드에 점수를 주어서 리소스 시작시 해당 노드에 리소스를 올리는 기능은 많은 엔터프라이즈 환경에서 사용하는 구성이다.
다만 이 방법의 문제는 해당 노드에 문제가 발생 시, 리소스가 다른 노드로 이동하고 이후 문제가 발생한 노드가 정상화 되었을 때 자동으로 해당 노드로 리소스들이 다시 원복되는 점에 있다. 실제 서비스 운영에서는 일시적인 다운타임이 고객사에 아주 무서운 영향을 줄 수 있어, 이러한 리소스 이동은 최대한 줄여야 한다.
이를 위해 stickiness 기능이 있다. 이는 리소스 재배치를 피하기 위한 기능이다. stickiness 는 간단하게 이야기하면, 장애 발생시 리소스를 받는 노드에게 주는 "점수" 이다.
Fence_xvm 은 High Availability Cluster에서 리눅스 위에 kvm으로 가상머신 올리는 경우, 간단하게 구성할 수 있는 Fence 방법이다. 이 구성을 위해서는 kvm 호스트 머신에서 세팅, 그리고 클러스터 노드가 될 가상머신에서의 세팅 두가지 세팅이 필요하다. 이 구성은 RHEL8 기준이며, 다른 버전이나 상세 정보는 아래 Redhat KB 를 참고해야 한다. (로그인 필요)
pcmk_host_map 항목에서 형식이 nodename:port 라고 나오는데 port는 가상머신의 이름이다. 또한, 가상머신의 이름과 호스트명이 동일한 경우 pcmk_host_map은 입력하지 않아도 된다. fence_xvm 은 멀티캐스트라 충돌이 있을 수 있어 펜스 장치는 1개만으로 3개 노드를 커버하도록 한다.
pcs resource enable/disable 리소스명/그룹명 : 리소스 중단. 컨스트레인트 테스트할때 사용
pcs resource update 리소스 정보 변경
pcs resource op add/remove 리소스명 이름(monitor/start/stop등)
* 펜스 관련
pcs stonith list 에이전트명
펜스 리스트 보기
pcs stonith describe 에이전트명
해당 펜스 에이전트의 상세정보 확인
에이전트명 -h
해당 펜스 에이전트의 상세정보 확인
pcs stonith delete
펜스 삭제
* 컨스트레인트 관련
pcs constraint list --full
현재 컨스트레인트의 상세정보
pcs constraint delete 컨스트레인트명
컨스트레인트 제거
pcs constraint order a then b
a가 시작되어야 b 도 시작 가능하다. a가 스톱되어야 한다면 b가 먼저 스톱된다.
pcs constraint location A prefers/avoids 노드명
해당 리소스가 해당 노드를 더 선호하게 된다. 이것은 인피니티를 가지게 됨. / 또는 더 안선호하고 마이너스 인피니티를 가지게 함.
pcs constraint location A prefers node=500
해당 노드에 500점 준다
pcs constraint colocation add B with A
두 노드는 동일 노드에서 실행되어야만 한다. A가 메인이다. a가 시작되어야 b도 시작된다. a가 시작할 위치가 없으면 b도 실행할 수 없다. a가 먼저 실행될곳을 결정하고 그다음 b가 실행될지 여부를 결정한다.
pcs constraint colocation add B with A -INFINITY
둘이 절대 같이 안있게함.
# 현재 스코어 보기
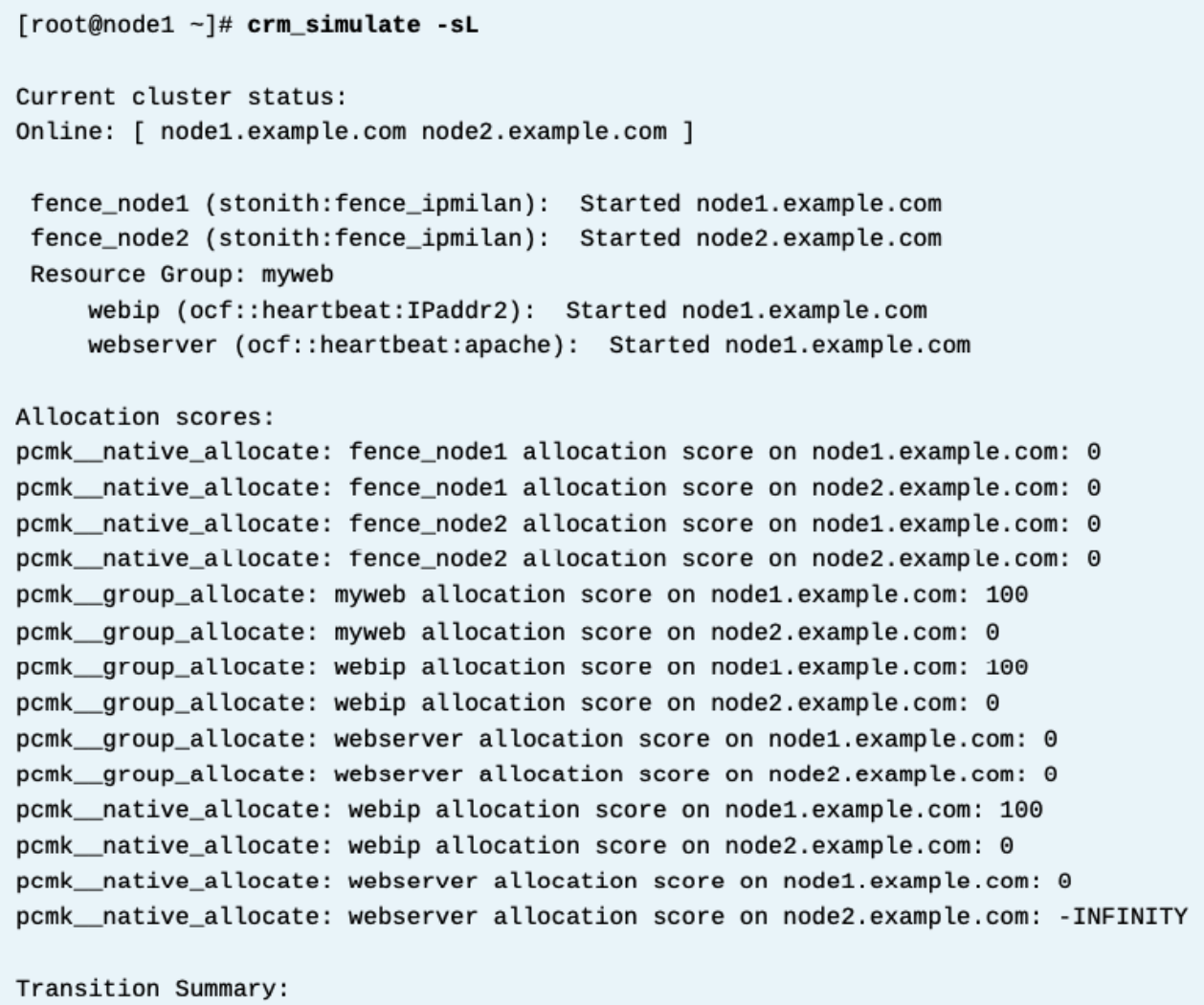
crm_simulate -sL 의 옵션
-s : 스코어를 보여주기 (리소스, 리소스 그룹, stonith 장치)
-L : live cluster 에서 (현재 클러스터?인듯)
crm_simulate 명령은 리소스 type에 따라 특정 리소스에 대해 호출되는 할당 메서드(이전에는 color알려짐)를 사용하여 워크로드를 생성한다.
일반 리소스는 native_allocate만을 호출하는데 반면 클론된 리소스는 클론되는 레귤로 리소스에 대한 native_allocate 와 클론으로서 성격에 대한 clone_allocate 둘다 호출한다.
비슷하게, 그룹 리소스도 native_allocate와 group_allocate 두개를 호출한다.
location constraint 만을 사용해서 노드에 이동시키는 예시만 쓰므로, 리소스 할당 type은 여기서는 관련이 없다.
위 예시에서, location constraint 가 있는데 myweb 리소스 그룹은 노드1을 선호하도록 100점이 되어있다.
클러스터가 노드1에서 webip 리소스를 시작했다. 리소스가 실행되고 있을 때, 리소스 그룹이 자동으로 클러스터 내 모든 노드에 대하여 webserver 의 리소스가 -infinity 가 되도록 세팅했다. 따라서 그 리소스는 node1에서 실행되어야만 했다. (리소스그룹안에 모든 리소스들은 동일한 클러스터 노드에서 실행되어야만 하므로)
또한 crm_simulate 명령은 또한 특정 클러스터 구성과 이벤트 순서에 따라 리소스가 어떻게 재배치되는지를 예측하기 위한 문제해결 도구가 되기도 한다.