* High Availability 클러스터란?
동일한 한가지 작업을 여러대의 컴퓨터가 세트가 되어 일하는 것. 러스터에 목적은, 운영하는 서비스가 Single Point Failure 의 영향을 가능한 받지 않게 하려는 것이다. 클러스터 내에 있는 컴퓨터들은 각각 node 라고 하며, 이들은 서로를 모니터링한다. node 또는 서비스에 문제가 있을 시, 정상적인 node에 서비스를 이동시켜 가능한 한 서비스 운영의 downtime을 최소화 시킨다.
이러한 전략은 하나의 서버가 가능한 한 uptime을 오랫동안 유지하도록 하는 것과는 다른 전략이다. 사실 uptime은 실제 엔드유저에게는 크게 중요하지 않으나, 서비스의 가용성은 엔드유저에게 중요하다.
* High Availbility 클러스터 방식
시스템 관리자는 서비스 요구사항과 하드웨어 사용 가능량 (비용)에 따라 최적화된 클러스터 구성을 결정해야 한다. 클러스터 구성을 계획할 때 가장 중요한 질문은 다음과 같다. "해당 서비스를 클러스터에 넣으면 가용성이 증가하는가?" 클러스터 구성은 2가지 방식을 가진다.
1. Active-Active Cluster

- 여러 노드에 하나의 동일한 서비스가 올라간다. 이 경우 한 노드가 죽는다 하더라도 다른 노드가 살아있다.
- 서비스는 다른 살아있는 노드에서 수행하므로 문제가 없고, Fail된 노드가 회복되면 다시 클러스터는 워크로드를 전체 노드에 분배한다.
- 이러한 타임의 클러스터의 주요 목표는 로드밸런싱으 수행하고, 높은 부하를 컨트롤하기 위해 많은 인스턴스를 확장하는 것이다.
- 다만 로드밸런싱을 위해 따로 로드밸런서가 필요하다.
- Active-Active 클러스터는 2개 이상의 클러스터 노드에서 사용할 수 있다.
2. Active-Passive Cluster

- 하나의 서비스가 하나의 노드에만 올라간다. 만약 하나의 노드가 Fail되면, 그때 클러스터는 다른 정상 노드에 해당 서비스를 올린다.
- 이 방식은 문제있는 노드가 클러스터 리소스에 접근해서 데이터 무결성을 깨뜨릴 수 있어, Fencing이라는 정책이 필요하다.
- 참고로 이 과정은 Activce-Passive 클러스터 구성에 포커스를 맞추고 있다.
* 클러스터의 구성요소 및 용어
리소스 / 리소스 그룹
work의 기본 단위를 리소스라고 표현한다. 여기서 work 기본 단위란, 실행하는 어플리케이션, 파일시스템, IP주소 등 모든 것이 리소스가 된다. 리소스 그룹은 관계 있는 리소스들은 하나로 묶는 것이다. 예를들어 웹 서비스를 제공하려면 접속할IP, 웹서비스, 웹페이지가 저장될 파일시스템 등이 필요하다. 이런 관계 있는것들은 하나의 노드에서 실행되어야하므로 리스소 그룹으로 묶어 하나의 노드에서 해당 그룹이 실행되도록 한다.
Failover
클러스터에 올라간 리소스에 문제가 있는경우, 해당 리소스를 다른 노드로 마이그레이션한다. 이러한 방식으로 클러스터가 운영된다.
Fencing
클러스터 내에서 가장 안전하게 지켜야 하는것은 데이터이다. 여러 노드에서 한 파일시스템에 접근을 시도하면 데이터 무결성 문제로 파일시스템이 깨지게 된다. 이것을 막기 위해 Fencing 이라는 방식이 있으며, 크게 서버의 전원을 끄거나 스토리지 연결을 끊는 방식이 있다. 서버 전원을 끄는 방식을 일반적으로 많이 사용한다. 노드에 문제가 생기면, 문제는 너무나 많은 종류가 있고 다 추측할 수 없다. 따라서 리소스에 문제가 있다고 판단되면 단순하게 Fencing을 수행해서 리소스를 다른 노드로 마이그레이션한다.
Quorum
클러스터의 무결성을 유지하기 위해 필요한 투표 시스템이다. 클러스터 노드에 문제가 생기면, 의사결정을 할 노드가 누가 될지를 결정하는데, Quorum으로 결정을 한다. 모든 노드는 투표수를 1개씩 가지며, 전체 노드 수에 기반하여 과반수 이상의 투표 수를 가진 노드의 그룹이 Quorum을 얻게 된다. Quorum을 얻지 못한 노드 (과반수가 아닌 노드)는 모두 Fencing된다. 만약 클러스터가 Quorum을 얻지 못한 상태라면, 어떠한 리소스도 시작되지 않으며, 실행된 리소스들은 중지된다. 예를들어 5노드 클러스터에서 3노드가 응답이 없고 2노드만 투표하면 그 클러스터는 Quorum을 잃게 되는 것이다.
* 클러스터 네트워크/하드웨어 아키텍쳐
클러스터 구성을 위해서는 아래와 같이 복잡한 구성이 필요하다. 아래는 5노드 클러스터의 일반적인 구성이다. 파란색은 IP 네트워크이며, 녹색은 SAN 네트워크(iSCSI, FCoE도 가능)이다. 하늘색은 상황에 따라 다른데, 아래 예시에서는 IP 네트워크이다.

- 왼쪽 Public Network 는 일반 사용자들이 접근하는 네트워크로, 외부에서 접근하는 공개적인 네트워크이다.
- 오른쪽 Private Network 는 엄격하게 비공개되어야 하며, 절대 외부에서 접근하지 않도록 해야 한다.
- Private Network 의 Ethernet Switch는 노드간 통신하는 경로로, Heartbeat 가 포함된다.
- Power Control은 전원을 끄는 Fencing에 필요한 것으로, 서버 전원을 끄기 위해 IPMI를 사용하여 서버 전원을 종료한다.
일반적인 서버 벤더는 전용 IPMI 관리툴이 있다. (Dell/iDRAC , HP/iLO 등)
* 클러스터 소프트웨어 구성요소
클러스터 소프트웨어는 Red Hat Enterprise Linux Add-ON : High Availability 에서 제공된다. 클러스터는 아래와 같이 여러 소프트웨어 데몬/컴포넌트들이 연계되어 작동한다.
Corosync
클러스터 노드간 통신을 핸들링하기 위해 페이스메이커에 의해 사용되는 프레임워크이다. corosync는 Pacemaker의 멤버십 및 쿼럼 데이터 소스이기도 하다.
Pacemaker
모든 클러스터에 관련된 활동에 대한 책임을 가지는 컴포넌트이다. 클러스터 멤버쉽을 모니터링하고, 서비스와 리소스를 관리하고, 클러스터 멤버를 fencing 한다. pacemaker RPM 패키지는 아래 3가지 중요 기능이 포함된다.
Cluster Information Base (CIB)
CIB는 클러스터와 클러스터 리소스들의 구성과 상태 정보를 XML 포맷형태로 포함한다. 클러스터 안에 있는 하나의 클러스터 노드는 DC(Designated Coordinator)로 행동하도록 페이스메이커에 의해 선택되며, 또한 모든 다른 노드에 싱크되는 클러스터/리소스 상태와 클러스터 구성을 저장한다. 스케줄러 (pacemaker-schedulerd)는 CIB의 컨텐츠를 사용하여 클러스터의 이상적인 상태와 어떻게 그 상태에 도달할지에 대해 계산한다.
Cluster Resource Management Daemon (CRMd)
클러스터 리소스 관리 데몬은 모든 클러스터 노드에서 실행되는 LRMd(Local Resource Management Daemon)에다가 리소스의 시작/종료/상태 체크 action을 조정/전송 한다. LRMd는 CRMd에게 받은 Action을 resource agents에게 전달한다.
Shoot the Other Node in the Head (STONITH)
stonith는 fence 요청을 처리를 담당하는 시설이며, 또한 해당 요청 액션을 CIB 안에 구성된 fence 장치에게 보낸다.
Pcs
pcs RPM 패키지는 두개의 클러스터 구성 툴을 포함한다. pcs 명령어는 커맨드 라인 인터페이스를 제공한다. 이것으로 pacemaker / corosync 클러스터의 모든 부분을create/configure/control 할 수 있다. pcsd 서비스는 클러스터 구성 동기화를 제공하며, 또한 pacemaker/corosync 클러스터를 create/configure 하도록 하는 웹프론트엔드를 제공한다.
* 클러스터 요구사항 및 조건
클러스터의 요구사항 및 조건은 매우 중요하며, 가능하면 클러스터 설정, 네트워크 아키텍쳐, 펜스 구성 같은 관련 데이터를 레드햇 support로 전송해서 검토받을 수 있다. 주요 고려사항은 다음과 같다.
1. 노드 개수
2. 클러스터의 네트워크 범위 (같은 네트워크 대역이 아닌 거리적으로 먼 거리 등)
3. Fence 장치
4. 노드의 가상화/클라우드 환경
5. 네트워크 구조
6. selinux
* 장애 조치 계획
모든 하드웨어는 결국엔 장애가 발생한다.. 하드웨어 수명 주기는 주 단위에서 연 단위까지의 범위를 가진다. 게다가 거의 모든 소프트웨어는 버그가 있다. 어떤것은 눈에 띄지 않지만, 다른것들은 전체 데이터베이스를 손상시킬 수도 있다.
시스템 관리의 주요 TASK 중 하나는 이런 문제가 발생할 것을 알고, 그에 따라 계획하는 것이다. 클러스터는 많은 Single Point of Failure (SPOF) 를 가진다. 이를 하드웨어단에서, OS 단에서, 인프라단에서, 소프트웨어단에서 이중화를 통해 막을 수 있다.
아래는 완전한 목록은 아니지만 일반적인 문제들이다.
• Power supply - > 파워 이중화
• Local storage -> 레이드 구성
• Network interfaces -> 네트워크 포트 본딩
• Network switches -> 스위치 이중화
• Fencing software -> Fence 이중화
• User data -> 정기적인 외부 백업
* References
pcs(8) man page For more information, refer to Chapter 2.
For more information, refer to the High Availability Add-On Overview chapter in the Configuring and managing high availability clusters guide at
Knowledgebase: "How can Red Hat assist me in assessing the design of my RHEL High Availability or Resilient Storage cluster?" https://access.redhat.com/articles/2359891
Knowledgebase: "Support Policies for RHEL High Availability Clusters" https://access.redhat.com/articles/2912891
Getting started with Pacemaker in the Configuring and managing high availability clusters guide at
* 실습 : BASIC High Availability Cluster 구성하기
노드 소프트웨어 설치하기
RHEL HA ADD-ON은 요구되는 소프트웨어 패키지 모음과 방화벽 설정, 그리고 노드 인증이 필요하다. 추가적으로, RHEL8과 RHEL7 클러스터 노드는 호환되지 않는다. 페이스메이커 클러스터에 있는 모든 노드들은 동일한 메이저 버전의레드햇 리눅스를 써야만 한다. (마이너 버전 얘기는 없음) 커뮤니케이션을 위해 RHEL8은 corosync 3.x를 쓰며, RHEL7은 corosync 2.x를 쓴다.
노드에 필요한 소프트웨어 설치
클러스터 구성 소프트웨어는 pcs 패키지이다. pcs 패키지는 corosync와 pacemaker 패키지를 필요로한다. yum으로 pcs 설치시 corosync와 pacemaker는 dependency로 자동으로 설치된다. fencing agents는 각각 클러스터 노드에 설치되어야 한다.
fence-agents-all 패키지는 모든 사용가능한 fancing agent 패키지를 당겨온다. 관리자는 fence-agents-all을 할지 아니면 fence-agents-XXX 패키지만 설치할지 선택해야 한다. 여기서 XXX는 fence 에이전트 종류에 따른 이름이다. pcs와 fence-agents-all(또는 다른 fence agent) 패키지는 모든 클러스터 노드에 설치되어야 한다.
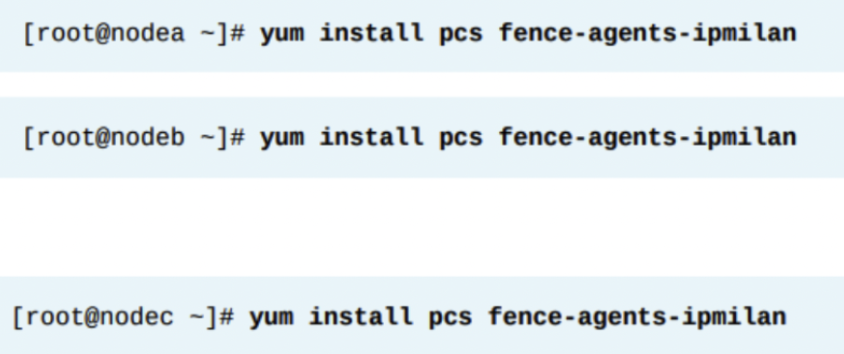
클래스룸 환경은 서버를 IPMI OVER LAN을 통해 전원끄기/켜기/재시작 할 수 있는 BMC를 포함한다. 클러스터에서 BMC를 사용하기 위해서는 fence-agents-ipmilan 패키지를 모든 클러스터 노드에 설치해야 한다.
클러스터 통신을 위한 방화벽 설정
모든 클러스터 노드의 방화벽에서 클러스터 통신을 위해 방화벽을 해제해야 한다. rhel8의 기본 방화벽은 firewalld이며, 방화벽 데몬은 클러스터 통신을 허용하기 위해 High-Availability 이라는 표준 서비스와 함께 제공됩니다. high-availability 방화벽 서비스를 각 노드에서 허용하기위해서는 아래와 같이 한다.

Pacemaker와 Corosync를 각 노드에서 활성화하기
pcsd 서비스는 클러스터 구성 동기화와 클러스터 구성을 위한 웹 프론트엔드를 제공한다. 이 서비스는 모든 클러스터 노드에 있어야 한다. systemctl을 사용하여 pcsd를 활성화한다. 모든 클러스터 노드에서 한다.
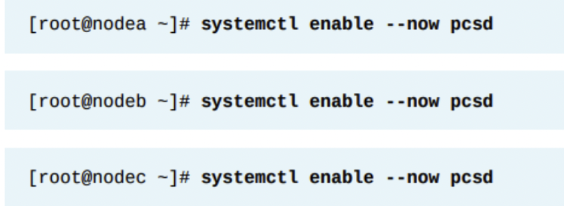
클러스터 커뮤니케이션을 위한 유저 설정
pcsd는 클러스터 커뮤니케이션과 구성을 위해 hacluster라는 유저를 사용한다. 레드햇은 클러스터 내의 모든 노드의 hacluster 유저가 동일한 비번을 쓰기를 권고한다. 아래처럼 비번을 redhat으로 구성할 수 있다.
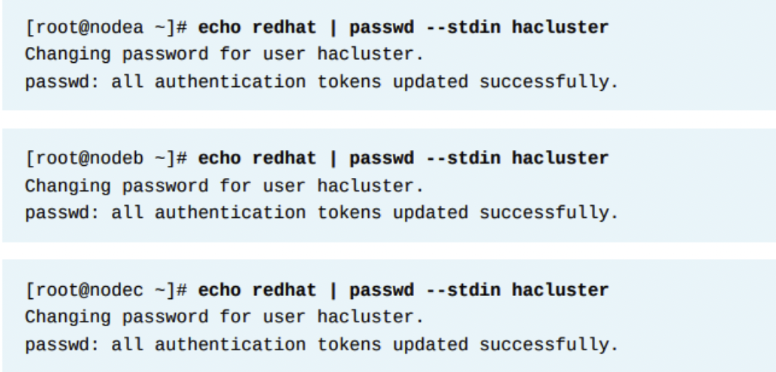
클러스터 노드 인증
pcsd 서비스 내에서 클러스터 노드를 인증해야 한다. 이 인증을 위해 hacluster 계정과 패스워드를 사용한다. pcs host auth 명령어로 클러스터 내의 모든 노드를 인증하기 위해서, 노드 중 하나의 노드에서만 아래 명령어를 실행하면 된다. 자동화를 목적으로 -u 유저명 , -p 패스워드 옵션을 사용할수도 있다.

클러스터 설치
3노드 클러스터 셋업 완료 후, pcs cluster setup 명령어를 통해 클러스터를 만든다. 이 명령어는 인수로 클러스터 이름과 모든 클러스터 노드들의 fqdn 또는 ip주소를 가져온다. 옵션 --start 파라미터는 모든 제공된 클러스터 노드에서 클러스터를 시작하는 옵션이다.

디폴트로, 리부팅된 클러스터 노드는 자동으로 크러스터에 rejoin 되지 않는다. pcs cluster enable 명령을 써서, 클러스터 서비스가 자동으로 실행되게 한다. --all 옵션은 모든 클러스터 멤버가 클러스터 서비스를 자동으로 실행되게 한다.
이 명령은 모든 클러스터 노드가 클러스터 서비스를 시작하고 클러스터 노드 중 하나에서 실행될 때 자동으로 클러스터에 참가할 수 있게 한다.
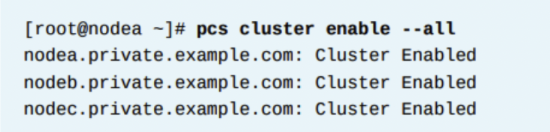
구성된 클러스터 상태 확인
레드햇은 클러스터가 기대한 대로 작동하도록 verify 하기를 권고한다. pcs cluster status 명령은 클러스터 상태의 전체 오버뷰를 보여준다. 아래처럼 나오면 기본 클러스터 구축은 성공이다.

'High Availability > RH436 & EX436' 카테고리의 다른 글
| [RH436/EX436] 5. 클러스터 관리 (0) | 2024.02.06 |
|---|---|
| [RH436/EX436] 4. 리소스 - 리소스 관리와 Constraint (0) | 2024.02.03 |
| [RH436/EX436] 3. 리소스 - 리소스 개념 (0) | 2024.02.03 |
| [RH436/EX436] 2. Fencing (1) | 2024.02.03 |
| [RH436/EX436] 0. High Availability Cluster Lab Network Environment (5) | 2024.02.03 |