High Availability Cluster는 구축 전 기본적인 네트워크 구성이 필요하다. 아래 예시가 가장 기본 네트워크이며, 해당 교육과정 수업시 실습을 위해 기본적으로 구성되는 Lab 시스템이다. 해당 네트워크 구성을 이해해야 기본적인 수업이 가능하다.
* 기본 네트워크 구조

workstation
핸즈온 메인으로 사용하는 컴퓨터. 실제 시험장에서 내가 직접 사용하는 물리적 PC라고 생각하면 된다. GUI이며, 항상 여기에서 먼저 로그인을 한다. 여기서 모든 다른 VM에 SSH로 연결할 수 있다. standard 유저 계정을 가지며, student / student 계정이다. student는 필요한 경우 root가 될 수 있다. 어떠한 작업도 root로 다이렉트로 로그인하는것을 요구하지 않는다. 하지만 만약 필요하다면 비번은 redhat 이다.
nodea / nodeb / nodec / noded
실제 클러스터 구성과 실습을 수행하는 서버들이다. workstation과 동일한 권한을 가진 계정인 student / student 를 가진다. 모든 VM은 lab.example.com DNS 도메인을 가진다. (172.25.250.0/24) 그리고 그 다음에는 3개의 다른 네트워크가 있다.
private.example.com (192.168.0.0/24) : private 클러스터 커뮤니케이션으로만 사용한다.
an01.example.com (192.168.1.0/24) / san02.example.com (192.168.2.0/24) : ISCSI와 NFS 스토리지 트래픽으로 사용한다.
private.example.com 은 클러스터 인프라에 있어 아주 중요하다. 왜냐면 이 네트워크가 fail되면 전체 클러스터가 fail 되기 때문이다. 이 때문에, 레드햇은 production에서는 클러스터 회복력을 높이기 위해 네트워크 이중화를 사용하도록 권고한다.네트워크 이중화는 이후 코스에서 설명한다.
bastion
bastion 시스템은 항상 실행중이어야만 한다. bastion 시스템은 사용자의 lab machine과 classroom 네트워크에 연결하는데 있어 router처럼 작동한다. 만약 bastion이 죽으면, 다른 lab machine들은 제대로 작동하지 않거나 부팅중 hang이 발생할 수 있다.
기타 서버들
몇몇 서버들은 support service를 하는 시스템이 classroom에 있다. content.example.com / materials.example.com 이 둘은 핸즈온 활동에서 사용되는 소프트웨어와 material이 있다. (이부분은 실제 공부에서는 중요하지 않다) 또한 iSCSI와 NFS를 제공하는 스토리지 서버인 storage.lab.example.com 도 제공된다. 이 스토리지는 매우 중요하지만 실습을 위해 구축하는 방법은 따로 이 수업에서 제공되지 않는다.
* 서버 역할 및 IP 표
- 아래는 classroom 환경에서 사용되는 여러 머신들을 ip와 역할들을 포함하여 표로 만든 것이다.

* Fencing 환경
fencing은 클러스터에서 중요한 부분이다. 자세한 설명은 이후 코스에서 하겠지만, 간단히 정의하면 문제있는 클러스터 노드가 클러스터 자원에 엑세스하는것을 제한하기 위한 것이다. 우선 중요한 것은 네트워크 측면에서의 Fencing 설명이며, 이 부분만 설명한다. 이 코스에서는 두가지 다른 fencing 방법이 사용된다. Fence은 최소 하나 이상 구축해야 하며 아래 예시 둘 중 하나만 사용해도 되고, 둘다 사용해도 된다. 그 외 여러가지 다른 종류가 많고 다른것을 사용해도 상관없다.
fencing 방법1 - BMC
이 방법은 실제로 프로덕션 레벨에서 사용할 때 가장 많이 사용하는 방법이며, 물리적 서버의 관리 포트를 사용하는 방법이다. 물리적 서버의 종류는 대표적으로 Dell, Lenovo, HP 등이 있고, 각 회사마다 다른 이름의 관리 툴을 사용한다. (iDRAC, xClarity, IMM, iLO 등) 이 툴들은 서로 다르지만 모든 기반은 BMC에 기반을 두고 있다.
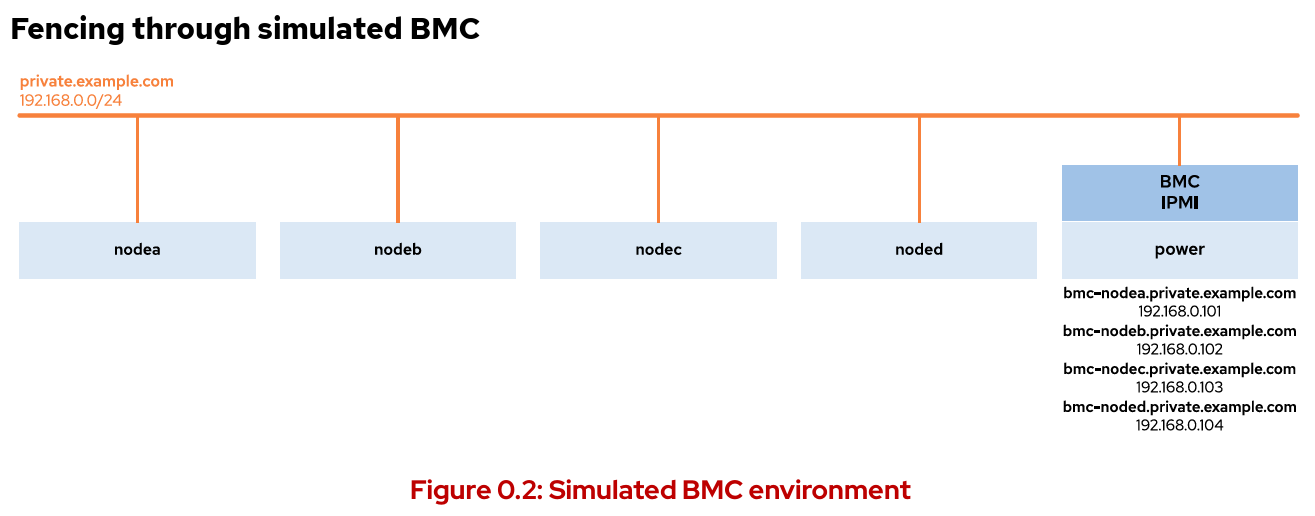
가상머신은 Power 관리에 관련된 BMC(Baseboartd Management Controller) 가 없다. 래서 BMC 동작은 power 라는 machine 의해 시뮬레이트된다. 시뮬레이션된 BMC 메커니즘은 클러스터 노드에서 원격으로 모니터링 및 관리 작업을 수행한다. (BMC에서 펜싱을위한 파워 모니터링을 말하는것으로 보임) BMC 장치의 IP주소는 (192.168.0.101/102/103/104) 이며 각각 nodea/b/c/d 를 위해 사용된다. 이것은 power 에 의해 호스트된다.
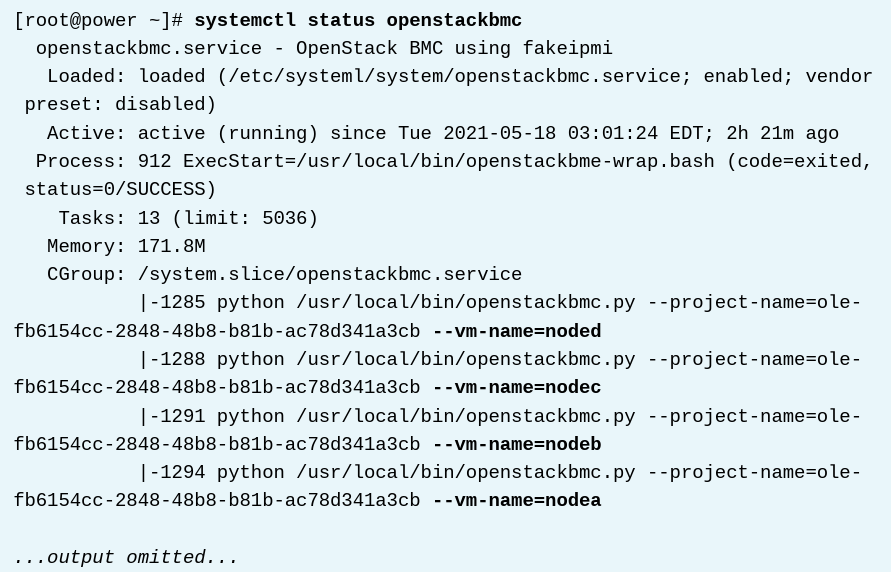
BMC IP주소와 노드 이름은 classroom 환경이 생성될 때 할당된다. openstackbmc 서비스는 power 에서 power-managed cluster node 하나당 하나의 프로세스로 실행된다. (즉 4개의 프로세스가있음) 이 서비스는 해당 노드를 대신하여 IPMI (Intelligent Platform Management Interface)의 요청에 응답한다. 모든 BMC 장치에 대하여, 로그인 정보는 admin / password 이다.
Fencing 방법2 - Simulated chassis

이 과정에서 사용되는 두 번째 fencing 방법은 관리 섀시(예: ibmbblade, hpblade 또는 블레이드 센터)를 시뮬레이션 한다. 이 방법은 fencing 요청을 위해 chassis IP 한개만 필요하다.
이 fencing 방법은 각 클러스터 노드에 플러그 번호를 할당하는데 fence_rh436 커스텀 스크립트와 pcmk_host_map 파라미터를 사용한다. 노드를 펜스하라는 요청이 chassis IP (192.168.0.100)에 보내질 때, 플러그 번호가 포함된다. fence_rh436 스크립트는 이 요청을 Fencing through simulated BMC 방법 에게 IPMI call 로 변환시켜 보낸다.

이 classroom에서 power 머신은 fence 할 노드인 가상머신을 전원 종료하는 요청을 simulate chassis에서 수행하도록 한다.
* 클러스터 구성 환경 초기화 할 때 유의사항
classroom 환경을 재시작하는것은 모든 classroom node들 또는 특정 노드를 초기 상태로 돌리는 것이다. 리셋을 통해 가상머실을 초기화하고 lab을 다시 시작할 수 있다. 이슈가 생기거나 해결이 어려운 문제가 있을 때 빠르게 해결할 수 있는 방법이다. 이 classroom은 전체 또는 일부 환경을 초기화 할 때 제약조건이 있다.
대부분의 레드햇 트레이닝 코스에서 개별 시스템은 필요한 경우 하나하나 리셋이 가능하다. 그러나, 이 과정에서는 클러스터 노드를 하나만 리셋하면, 그 결과로서 해당 노드가 필요한 정보들을 잃게되고, 클러스터의 일부로서 통신하는것이 실패하게 된다. 그러므로 올바른 절차는 클러스터에서 해당 노드를 제거하고, 그 후에 재시작해야한다. 클러스터에서 노드를 제거하는것은 2가지 스탭으로 진행된다.
1. 노드를 클러스터에서 제거한다. : pcs cluster remove newnode.example.com
2. 노드가 클러스터에서 제거된 것을 반영하기 위해 fence 구성을 조정한다. (dedicated fence 장치를 삭제하거나 shared fence 장치를 수정한다.
노드를 재시작한 후에는 해당 노드는 다시 클러스터에 포함해야 한다. 즉, 모든 요구되는 패키지를 설치하고, 해당 노드를 클러스터 안에 권한을 넣고, 방화벽 포트를 열고, pcsd 서비스를 시작하고, 해당 노드가 클러스터의 일부가 되도록 구성도 해야한다.
* 클러스터의 노드들
일부 클래스룸의 VM들은 작업동안 수정되지 않으며, 시스템 문제가 발생하지 않는 한 전혀 리셋할 필요도 없다. 예를 들어, workstation 머신은 불안정해지거나 통신이 끊긴 경우에만 재설정해야 하며 자체적으로 재설정될 수 있다. 아래 표에는 재설정할 수 없는 머신과 필요한 경우 재설정할 수 있는 머신이 나열되어 있다. 만약 재설정을 해야하는 상황이 있다면, 온라인 환경에서, 선택한 머신을 클릭하고 ACTION -> RESET을 하면 된다.

참고할 사항으로, 만약 power 머신을 리셋한다면, fencing resouces들은 fail되거나 stop된다. 타임아웃이 되기 때문이다. 이 경우, 클러스터에서 이 리소스들을 다시 사용하는것을 enable 하도록 resources의 fail count를 꼭 reset 해줘야 한다. 이를 위해 아래 명령을 치면 된다. pcs resource cleanup my_resource
또한 original course build를 재생성하여 클래스룸 환경을 리셋할수도 있다. 이것은 문제가 완전히 꼬였을 때 사용한다. 문제를 해결하는것보다 코스를 재생성하는것은 빠르며, 일반적으로 몇분이 걸리며 깔끔하다. 온라인 환경에서 delete를 클릭하고, 기다렸다가 create 버튼을 누르면 된다.
'High Availability > RH436 & EX436' 카테고리의 다른 글
| [RH436/EX436] 5. 클러스터 관리 (0) | 2024.02.06 |
|---|---|
| [RH436/EX436] 4. 리소스 - 리소스 관리와 Constraint (0) | 2024.02.03 |
| [RH436/EX436] 3. 리소스 - 리소스 개념 (0) | 2024.02.03 |
| [RH436/EX436] 2. Fencing (1) | 2024.02.03 |
| [RH436/EX436] 1. 클러스터 개념 및 기본클러스터 구성 (0) | 2024.02.03 |