Logical Volume Management (LVM)은 디스크 공간 관리를 더 쉽게해준다. 예를들어, logical volume에서 생성된 파일시스템이 공간이 더 필요한 경우, logical volume이 있는 volume group의 남는 공간을 사용하여 해당 logical volume을 확장하고, 파일시스템을 리사이즈 할 수 있다. 만약 디스크 장애가 발생하면, 대체 디스크를 해당 volume group에 physical disk로 등록하고 해당 logical volum의 extent들을 새로운 디스크로 마이그레이션 할 수 있다.
* lvm 주요 용어 정의
Physical Devices
물리적 장치는 논리 볼륨에 저장된 데이터를 저장하는 데 사용되는 저장 장치이다. 이러한 장치는 블록 장치이며 디스크 파티션, 전체 디스크, RAID 어레이 또는 SAN 디스크가 될 수 있다. LVM과 함께 사용하려면 장치를 LVM 물리적 볼륨으로 초기화해야 한다. 전체 장치가 물리적 볼륨으로 사용된다.
Physical Volume (PV)
Physical Volume은 LVM과 함께 사용되는 기본 물리 스토리지이다. LVM 시스템에서 사용하기 전에 장치를 물리적 볼륨으로 초기화해야 한다. LVM tool은 물리적 볼륨을 물리적 볼륨에서 가장 작은 스토리지 블록 역할을 하는 작은 데이터 청크인 Physical Extents(PEs)으로 세분화한다.
Volume Group (VG)
볼륨 그룹은 하나 이상의 물리적 볼륨으로 구성된 스토리지 풀이다. 이는 기본 스토리지에서 전체 디스크와 기능적으로 동일하다. PV는 하나의 VG에만 할당할 수 있다. VG는 사용되지 않는 공간과 논리 볼륨으로 구성될 수 있다.
Logical Volume(LV)
논리 볼륨은 볼륨 그룹의 free physical extents을 가지고 생성되며 애플리케이션, 사용자 및 운영 체제에서 사용하는 "스토리지" 장치를 제공한다. LV는 logical extents (LE) 의 모음으로, PV의 가장 작은 스토리지 청크인 physical Extents (PE)에 매핑된다. 기본적으로 각 LE는 하나의 PE에 매핑된다. 특정 LV 옵션을 설정하면 이 매핑이 변경됩니다. 예를 들어 미러링은 각 LE가 두 개의 PE에 매핑되도록 한다.
* lvm 스토리지 구현하기
LVM 스토리지 생성은 여러 스탭이 있다. 첫번째는, 어떤 physical device를 사용할지 결정하는 것이다. 이러한 physical device는physical volume으로 초기화된다. 이를 통해 PV들은 LVM에 belonging 된다고 인식한다. PV는 VG로 합쳐진다. 이것은 LV를 할당할 수 있는 디스크 공간 풀을 생성하는 것이다. LV는 VG의 사용가능한 공간으로부터 생성되며, 이것은 파일시스템으로 포맷될 수 있다. 또한 스왑 공간으로 쓸수도 있고, 마운트되고 영구적으로 사용될 수 있다.
* LVM 생성 명령어들
LVM 구성을 진행하기전에 PV를 만들 블록 장치를 찾아야 한다. 이것은 전체 디스크가 될 수도 있고, 디스크 내의 특정 파티션이 될 수도있다. 아래 예제에서는 sdb, sdc를 LVM에 사용할것이다. lsblk, blkid, cat /proc/partitions 명령으로 장치들을 식별할 수 있다.
pvcreate
물리적 장치 또는 파티션에다가 이것이 Physical Volume이라고 라벨링을 한다. 또한 이 명령은 Physical Volume을 고정된 사이즈인 Physical Externts (PEs)로 나눈다. 예를들어 PE의 크기는 4MiB가 될 수 있다. 간단히 정리하면, pvcreate 명령은 물리적 장치 또는 파티션을 PV로 만든다. 이러한 PV는 VG에 할당될 준비가 된다.
vgcreate
하나나 하나 이상의 Physical Volume들을 하나의 Volume Group 으로 만든다. VG는 기능적으로 하드 디스크와 동일하다. 사용자는VG에 할당된 PV들이 가지고 있는 PE의 단위로 Logical Volume을 생성할 수 있다. 간단히 말하면 vgcreate 명령은 PV들을 모아 하나의 Pool을 만들고, 다시 거기서 PE의 개수단위로 LV를 생성하는 것이다. 아래 vg01의 크기는 /dev/sdb, /dev/sdc의 크기를 합친 것이 된다.
lvcreate
VG에서 사용가능하 PE를 가지고 새로운 Logical Volume을 생성한다. 몇가지 옵션이 있다. 아래 예시는 LV 생성을 위해 최소한의 옵션이며, 맨 마지막에는 LV를 생성할 VG를 명시한다. 결과적으로 vg01에서 700M 를 가져와서 lv01을 생성하게 된다.
-n : LV의 이름을 지정한다
-L : LV의 크기를 bite로 명시하여 생성한다. / -l : LV의 크기를 extents 개수로 명시하여 생성한다.
-L 옵션의 경우, 그냥 M이 아니라 MiB로 명시하여 명확하게 값을 지정할 수 있다. (KiB, GiB 등) 또한 -l 옵션은 사전에 정해진 extents의 크기에 따라 실제 크기가 결정된다. 예를들어 extents 크기가 4M 이고 200개라면 800M 가 될 것이다. 또한, lvcreate 명령 사용 시 크기가 정확히 일치하지 않을 경우 크기가 물리적 범위 크기의 인수로 반올림된다.
* Filesystem 생성
mkfs 명령어로 LV를 파일시스템으로 만들 수 있다. xfs 외에 여러 파일시스템이 있으나 더이상 자세한 설명은 생략한다.
* LVM의 상태 확인 명령어들
pvdisplay
이 명령은 PV에 대한 상세 정보를 보여준다. pvdisplay 단독으로 사용할수도 있고, 여러 옵션을 사용할수도 있다.
1. 장치에 매핑된 PV의 이름
2. PV가 할당되어있는 VG의 이름
3. 사용하지 않은 용량을 포함하여, 해당 PV의 물리적 크기
4. Physical Extent의 크기 PE는 해당 lV에서 할당될 수 있는 가장 작은 사이즈 단위이며, 또한 사용된PE, 사용하지 않은 PE 값을
계산할 때의 곱하기 계수가 된다.예를들어 175개의 PE 와 4MiB(PE크기) 를 곱하면 700MiB가 된다. 또한 LV의 크기는 PE 단위의
계수로 반올림된다. LVM은 PE 크기를 자동으로 설정하지만 따로 지정을 할 수도 있다.
5. Free PE는 새로운 LV 할당에 사용할 수 있는 PE가 몇개나 남았는지 보여준다.
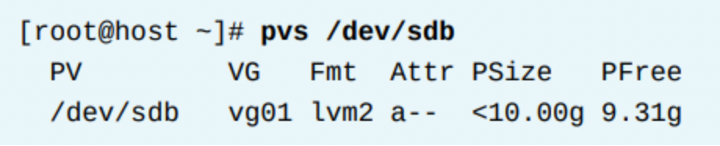
pvs
다른 정보들을 좀 더 컴팩트하게 보여준다.
vgdisplay
VG에 대한 상세 정보를 보여준다. vgdisplay 단독으로 사용할수도 있고, 여러 옵션을 사용할수도 있다.
1. VG의 이름
2. 논리적 볼륨 할당에 사용할 수 있는 스토리지 풀의 총 크기
3. PE의 개수로 표현된 총 사이즈
4. 새로운 LVf를 만들거나 존재하는 LV를 확장하는데 사용할 수 있는 남은 공간이 얼마나 있는지 보여줌
vgs
다른 정보들을 좀 더 컴팩트하게 보여준다.
lvdisplay
LV 에 대한 상세 정보를 보여준다. lvdisplay 단독으로 사용할수도 있고, 여러 옵션을 사용할수도 있다.
1. LV의 장치명을 보여준다. 어떤 툴에서는 /dev/mapper/vgname-lvname 형태로 보여주기도 하는데, 동일한 것이다.
2. 이 LV가 위치한 VG를 보여준다.
3. LV의 전체 크기를 보여준다. 파일 시스템 도구를 사용하여 데이터 저장을 위한 여유 공간과 사용 공간을 확인할 수 있다.
4. 이 LV에 의해 사용된 LE의 수를 보여준다. LE는 일반적으로 VG 안에서 PE와 1:1 매핑된다.
lvs
lv에 대한 다른 정보들을 좀 더 컴팩트하게 보여준다.
* References
lvm(8), pvcreate(8), vgcreate(8), lvcreate(8), pvdisplay(8), pvs(8), vgdisplay(8), vgs(8), lvdisplay(8), lvs(8), and lvm.conf(5) man pages
Knowledgebase: "What are the advantages and disadvantages to using partitioning on LUNs, either directly or with LVM in between?"
리눅스 시스템에서는 스토리지 시스템 (FC, SAS, iSCSI 등)연결시 동일한 디스크를 하나의 통로가 아닌 여러개의 경로로 액세스하게 할 수 있다. Multipath는 이러이러한 중복 경로를 가지는 가상 스토리지 장치를 구성할 수 있도록 하여 시스템에서 스토리지 접근 시 여러 경로를 사용하도록 한다. 이러한 중복 경로는 다음과 같은 이점을 가진다.
- 가용성 증가 : 여러개의 경로 중 하나의 경로에 문제가 생겨도, 시스템은 남은 정상적인 경로로 스위치하여 운영에 문제가 없게 한다. 다만 스토리지 자체가 문제가 생기면 사용은 불가하게 된다.
- 대역폭 증가 : 여러개의 경로를 그룹으로 모아 스토리지 대역폭을 넓혀 성능을 향상시킬 수 있다.
아래는 HBA 카드를 통해 FC를 사용하여 스토리지에 접근하는 예시이다. 서버가 아래처럼 2개의 FC HBA를 가지고 있다. 각 연결은 독립된 FC 스위치에 연결되며, 또한 스토리지 ARRAY에 있는 독립된 컨트롤러와 연결되게 된다.
다른 예시로, 이전 iSCSI 에서 Portal 주소가 1개가 아니라 여러개인 경우, 하나의 target IQN이지만 Portal 주소 경로가 여러개이므로 이 Muiltipath를 구성하여 가용성을 높이거나 대역폭을 증가시킬 수 있는 것이다.
* Multipath 설치 패키지
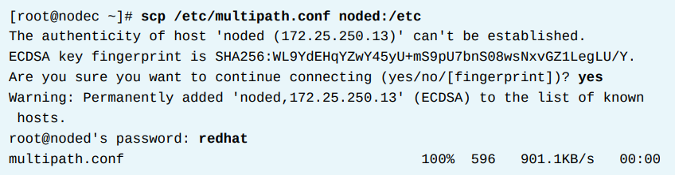
레드햇 엔터프라이즈 리눅스는 device-mapper-multipath 라는 패키지를 통해 Multipath의 기본적인 바이너리와 데몬을 제공한다. 이 데몬을 통해 시스템은 동일한 디스크와 연결된 여러개의 경로를 자동으로 감지하고, /etc/multipath.conf 파일의 설정에 따라 그룹으로 결합한다. 그룹은 여러 경로로 구성될 수 있다. 이 구성을 사용하면 시스템이 그룹 내부의 경로 사이에 I/O 트래픽을 분산한다.
또한 레드햇 엔터프라이즈 리눅스는 dm-multipath 서브시스템을 사용하여 multipath 지원을 제공한다. dm_multipath 커널 모듈은 가상 디바이스를 생성한다. (여러개의 경로를 가진 하나의 가상 디스크) multipathd 데몬은 이러한 가상 디바이스를 관리하고, 각 경로를 모니터링한다. 사용자는 multipath 명령어를 통해 멀티패스 장치의 상태를 확인할 수 있다.
멀티패스 패키지를 설치할때는 아래와 같은 명령어를 수행한다.
* Multipath 이름 및 구성
커널은 모든 멀티패스 장치 (가상디바이스)에 WWID(World Wide Identifier)를 할당한다. WWID는 글로벌하게 유니크하며, 바뀌지 않는다. 디폴트로, 시스템은 멀티패스 장치명을 WWID로 세팅한다. 시스템은 또한 /dev/mapper 디렉토리에 각각의 WWID로 된 장치 파일을 생성한다. 그러나 이 WWID 는 길고 복잡하여 식별이 어렵다.
/etc/multipath.conf 파일에서 만약 user_friendly_names 옵션을 yes로 세팅하는 경우, 시스템은 심플하고 변하지 않고 유니크한 값을 해당 멀티패스 장치에 할당한다. 이 이름의 형태는 /dev/mapper/mpathN 로 만들어진다. 또한 만약 해당 멀티패스 장치가 파티션을 가졌다면, 시스템은 또한 파티션에 대한 디바이스 명을 만든다. 예를들어, /dev/mapper/mpathap1은 /dev/mapper/mpatha 장치의 파티션1이다.
또한 mpath라는 기본 이름 말고 사용자가 직접 커스텀해서 사용할 수 있다. /etc/multipath.conf에서 multipaths 섹션에 alias 옵션을 사용하면 된다.
시스템은 WWID가 장치 이름에 매핑된 정보를 /etc/multipath/bindings 파일에 저장한다. 모든 동일한 클러스터 노드에서 동일한 이름을 가지려면, 각 노드에 /etc/multipath/bindings를 똑같이 배포해야 한다.
시스템은 /dev 경로에 디스크 장치에 대하여 /dev/dm-N 의 형태로 이름을 생성한다. 이러한 장치는 엄격하게 시스템 내부용으로만 사용된다. 저장소에 액세스하는 데 직접 사용하지 말 것.
* Multipath 구성파일
위와 같이 multipath 패키지를 설치한 후에는 /etc/multipath.conf 파일을 생성하여 multipath 구성을 사용자가 직접 config 해야한다. 이 파일은 자동으로 생성되지 않으며, 또한 이 파일이 없으면 multipathd 데몬 서비스는 시작하지 않는다. 이 multipath.conf 파일을 생성하기 위해서는 다음 명령을 사용한다.
이 명령은 /etc/multipath.conf 파일을 생성하고, multipathd 데몬도 시작한다. 또한 mpathconf 명령은 가장 자주 사용되는 구성 파라미터를 세팅할 수 있는 추가적인 옵션을 허용한다. 예를들어 해당 명령은 default로 user_friendly_names 을 y로 활성화하는데, --user_friendly_names n 옵션은 이 파라미터를 multipath.conf 구성파일에서 사용하지 않도록 한다.
user_friendly_names 설정을 y로 하면, /dev/mapper/mpathX 라는 이름으로 multipath 장치가 생성되며, n으로 설정하면 멀티패스 디바이스에 WWID를 기반으로 한 이름이 지정된다.
또한 multipath.conf 파일을 수정하는 경우, multipathd 데몬을 재시작해야 한다.
- 디스크의 경로들을 찾는동안, 시스템은 찾을 수 있는 모든 장치를 multipath topology에 추가한다.
- 블랙리스트 섹션을 설정하면 이러한 토폴로지 추가에서 제외할 장치들의 리스트를 정의한다.
blacklist_exceptions{}
- 블랙리스트 섹션에 나열되어있음에도 불구하고, 멀티패스 토폴로지에 포함해야 하는 장치를 정의한다.
defaults{}
- 이 섹션은 devices나 multipaths 섹션에 명확하게 덮어씌워지지 않는 이상 모든 멀티패스 장치들에 대하여 디폴트 세팅을 정의한다.
- 즉 여기 설정은 devices나 multipaths 설정보다 후순위라는 것.
devices{}
- device 섹션에는, 특정 타입의 storage controller에 대한 default 섹션에서 정의한 것의 재정의 (덮어씌우는)가 포함된다.
- 시스템은 vender, 제품, revision 키워드를 통해 device를 식별한다.
- 이러한 키워드는 sysfs에 있는 정보와 일치되는 정규표현식이다.
multipaths{}
- 특정 multipath devices에 대한 설정이 포함된다.
- 이 설정은 defaults와 devices에서 정의한 파라미터를 덮어씌운다.
- 시스템은 멀티패스 장치의 WWID 로부터 멀티패스 장치를 식별한다.
특정 multipath device의 파라미터를 검색하려면, 시스템은 multipaths 섹션에서 먼저 일치하는 device를 찾고, 그다음 devices 섹션에서 찾는다. 위 두 섹션에서 일치하는 항목을 찾지 못하는 경우, 이제 파라미터를 defaults에서 찾는다. 즉 multipaths > devices > defaults 순으로 찾는다는 것이다.
* defaults() 파라미터 상세
multipath -t 명령을 사용하여 현재 구성 정보를 볼 수 있다. 여기에는 구성 파일에 명시적으로 세팅되지 않은 모든 파라미터를 보여준다. multipath.conf(5) man 페이지에서 각 파라미터의 기본값을 볼 수 있다. 아래는 몇가지 useful한 세팅들을 보여준다.
path_selector
- 이 설정은 I/O에 사용될 "그룹안에 있는 경로"를 선택하는데 있어 멀티패스가 사용할 알고리즘을 세팅한다.
- service-time 0 : 기본값이다. 예상 서비스 시간이 가장 짧은 경로로 다음 I/O 요청을 보낸다.
- round-robin 0 : 그룹 안의 모든 경로에 걸쳐 I/O를 분배한다.
- queue-length 0 : 처리되지 않은 요청 (outstanding request)의 대기열이 가장 짧은 경로로 다음 I/O 요청을 보낸다. (The "queue-length 0" algorithm sends the next I/O request to the path with the shortest queue of outstanding requests. )
path_grouping_policy
- 이 설정은 시스템이 path(경로)를 그룹으로 결합하는 방법을 정의한다.
- 기본 값은 failover 로, multipath가 각 경로를 별도의 그룹에 넣도록 지시한다. 이 구성을 쓰면 시스템은 I/O에 한나의 경로만 사용하고 장애 발생 시 다음 경로로 전환한다.
- multibus 정책을 사용하면, 시스템은 모든 가능한 경로를 하나의 그룹으로 합친다. 그다음 multipath는 path_selector 알고리즘 설정에 따라서 I/O 요청을 경로들에게 분배한다.
- multibus로 매개변수를 설정하기 전에, storage controller가 active-active 연결을 지원하는지 확인해야 한다.
path_checker
- 이 설정값은 multipathd 데몬이 path가 정상인지 확인하는 방법을 구성한다.
- 기본값은 tur 이며, 이 값은 multipathd 데몬이 TUR(Test Unit Ready) SCSI 명령을 사용하여 스토리지 컨트롤러의 상태를 검색하도록 지시한다.
- 일부 path 검사기는 특정 하드웨어에서만 작동한다. 예를들어 emc_clariion 검사기는 EMC VNX 스토리지를 위해 사용되고, hp_sw 검사기는 HPE MSA 스토리지를 위해 사용된다.
- PATH 검사기는 종종 스토리지 장치에 따라 달라질 수 있으므로, 사용자는 일반적으로 path_check 파라미터를 구성파일의 devices 섹션에다 세팅한다.
no_path_retry
- 이 설정은 모든 path가 fail되었을때 multipath 동작을 제어한다. 디폴트값은 fail 이며, multipath가 즉시 상위 레이어에 I/O 에러를 보고한다.
- 이 파라미터는 또한 오류를 보고하기 전에 재시도 회수를 나타내는 값으로 숫자를 사용할 수 있음.
- 값을 queue로 하면, multipath 경로가 정상화될 때까지 모든 I/O 요청들을 대기열에 추가한다. 이 조건에서는, 일부 프로세스가 중단되지 않는 sleep 상태로 영원히 hang 걸릴 수 있음.
user_friendly_names
- multipath device가 이름을 WWID로 받거나 (no 설정) mpathN으로 받게 (yes 설정) 할 수 있다.
* multipath가 아닌 장치를 제외하기
관리하는 디스크들 중에 multipath가 되지 않도록 할 제외 리스트를 사용한다. 일반적으로 로컬 디스크나 이중화 경로가 없는 스토리지 컨트롤러들에서 설정한다. 이러한 장치들은 /etc/multipath.conf 구성파일의 blacklist 섹션에서 정의한다.
find_multipaths 라는 파라미터가 있다. 이 파라미터는 defaults 섹션에서 정의되는데, yes로 하는경우 이 파라미터는 자동으로 하나의 패스만 있는 모든 장치를 멀티패스에서 제외한다. 이 구성은 로컬 디스크나 이중화 경로가 없는 storage device가 멀티패스 되는것을 막는다. 이렇게 쓰면, 보통으로 blacklist 섹션에는 아무것도입력하지 않는다.
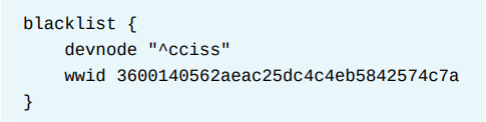
직접 구성파일에서 제외하는 경우, 아래처럼 blacklist에 디스크를 명시하거나 (wwid 등으로) devnode 매개 변수를 사용하여 장치 파일을 기반으로 장치를 제외할 수 있다. 두 방법 모두 정규식을 사용할 수 있다. 아래 예시는 두가지 방식 모두를 보여준다.
또 다른 방식은 blacklist 섹션을 사용하여 모든 디바이스를 제외시킨 다음 blacklist_exceptions 섹션을 사용하여 개별 디바이스를 허용하는 방법도 있다. 이 구성에서 blacklist_exceptions 섹션은 an inclusive list으로 작동하게 된다.
* wwid 찾기
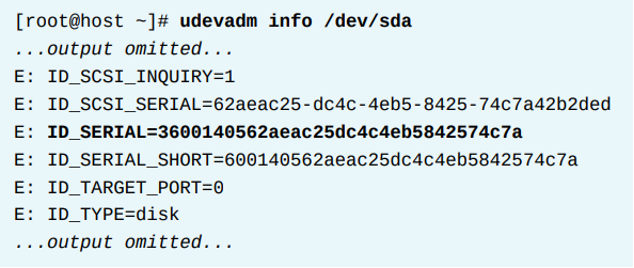
시스템은 device의 serial number를 WWID에 사용한다. 시스템은 udev 데이터베이스를 쿼리하여 해당 정보를 가져온다. udev 데이터베이스는 시스템의 모든 device 목록과 속성을 유지관리한다. 따라서 udevadm info 명령을 사용하여 해당 데이터베이스를 볼 수 있다. 예를들어 iSCSI를 통해 등록된 디스크가 /dev/sda인 경우, 아래 명령으로 wwid를 찾을 수 있다.
이 예시는 장치 파일 (/dev/sda)가 ID_SERIAL이라는 속성으로부터 WWID를 검색하여 인수로서 쓰는것을 보여준다. 이 36으로 시작하는 문자열을 multipath.conf의 wwid로 사용하면 된다.
* Multipath를 제공하는 스토리지 종류별 멀티패스 설정 구성하기
스토리지 종류에 따라 Multipath 설정을 다르게 해야할 수 있다. 대부분 일반적인 스토리지 하드웨어는 이미, built-in defaults에 정의된 스토리지들의 섹션이 있다. multipath -t 명령을 통해, 이러한 스토리지 컨트롤러의 구성정보를 볼 수 있다. 아래 예시는 알려진 장치의 몇몇 리스트이다.
만약 해당 리스트에 현재 사용자가 쓰고 있는 스토리지가 리스트에 없다면, 설정값을 찾아 섹션을 추가해야 한다. 현재 Multipath로 사용할 디스크의 스토리지 정보는 여러가지 명령들로 확인 가능하다.
- multipathd show paths format "%d %s" (vendor, product, revision 등) - cat /sys/block/sda/device/vendor
- cat /sys/block/sda/device/model
- cat /sys/block/sda/device/rev
아래는 존재하지 않는 스토리지 하드웨어에 대한 정보를 정의한 예시이다. 위 명령어들로 확인된 값들을 넣을 수 있다.
* 특정 경로의 상세 정보를 구성하기
specific multipath devices의 경우, 사용자는 multipaths{ } 섹션을 사용하여 defaults{ }와 devices{ } 섹션의 파라미터 값들을 덮어씌울 수 있다.
multipaths 섹션의 일반적인 용도 중 하나는 mulitpath device의 alias를 정의하는 것이다. alias를 정의하면, 시스템은 /dev/mapper/ 디렉토리 안에 있는 device 파일의 이름을 해당 alias로 사용한다. 따라서 여러 multipath devices 들을 더 쉽게 구분할 수 있다. 예를들어, 아래 구성은 해당 multipath device인 WWID 3600140562~~를 알리아스를 clusterstorage라고 설정했다. 결과적으로multipath는 /dev/mapper/clusterstorage라는 디바이스 파일을 생성하게 된다.
* Multipath 장치에 대한 파티션을 만들기
multipath device에서 파티션 생성하려면, 아래 두가지 방식 중 한가지를 선택해서 수행한다.
- 파티션 에디터를 사용한다. parted /dev/mapper/mpatha (상세한 parted의 설명은 여기서는 제공하지 않음)
- udevadm settle 명령 사용. 이 명령은 시스템이 새 파티션을 감지하고 /dev/mapper/ 디렉터리에 관련 장치 파일을 생성할 때까지 기다린다. 완료된 경우에만 결과를 리턴한다.
* Multipath 장치 삭제하기
multipath device의 모든 경로를 제거한 후에는, multipath -f <multipath_device> 명령으로 멀티패스 장치를 클리어한다. 만약multipathd 데몬이 실행중이 아니고, 여전이 multipath device 파일이 존재한다면, 그때는 multipath -F 명령으로 모든 멀티패스 장치들을 flush 한다. (완전히 제거하는 명령)이 명령은 다양한 구성을 테스트할 때 이전 구성의 남아있는것들을 제거하려는 경우에 유용하다.
* Multipath 장치 상태 확인하기
multipath -ll 명령은 모든 경로를 컨트롤하고 그들의 스테이터스를 보여준다. 각 multipath device의 정보를 보여준다. 각 device에 대하여, 이 명령은 path group과 각 그룹에 있는 path들을 보여준다. 가장 많이 사용한다. 또한 multipath -l 명령은 multipath topology에 대한 quick review를 보여준다.
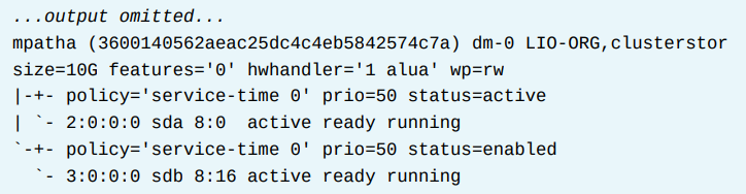
아래 예시에서는 두개의 multipath device가 있다. (mpathb, mpatha)
기본 정보
- 첫번째 라인은 user-friendly name (mpathb)를 보여주고, 그다음 device의 WWID를 보여준다. 그리고 vendor와 product 이름을 보여준다.
- 두번째 라인은 devices size, 그리고 write permission (wp) 및 다른 상세사항을 보여준다.
각 path 그룹
- 위는 아래는 각 path 그룹을 보여준다. 이 예시에서는, mpathb 는 2개의 path group을 가진다. 한 번에, 하나의 path group만 active 되어있다.
- 그리고 multipath는 active group이 fail되는 경우 inactive group으로 스위치한다.
- 여기서 status 부분이 path group이 active 되어있는지를 보여준다. 두번째 path group은 enabled로 되어있는데, 이것은 active 그룹이 fail에 대비해 이 path group이 ready 상태라는 것을 의미한다.
- policy 부분은 group의 path들 사이에 I/O 요청을 어떻게 분배할지 multipath가 사용하는 알고리즘을 명시한다. 이 속성은path_selector 파라미터와 연관되어있다.
path 그룹 아래에 path 리스트
- 각 path group,은 위와 같이 path들의 리스트가 있다. multipath는 active group안에 있는 모든 path 들 사이에 I/O 요청을 분배한다.
- 이 status 정보는 path의 상태를 가늠하는데 도움을 준다. up 되어있고 I/O 작업에 대해 준비가된 PATH는 ready 상태이다.
- 다운된 path는 faulty로 나온다.
- 위 이미지의 failed, faulty 각각은 동일한 정보를 보여준다. failed는 커널의 관점에서 path device 의 상태를 리포트한다. faulty는multipath path 검사기로부터 나온 상태를 보여준다.
- /etc/multipath.conf 파일은 path_checker 파라미터를 사용함으로써 path 검사기를 정의한다.
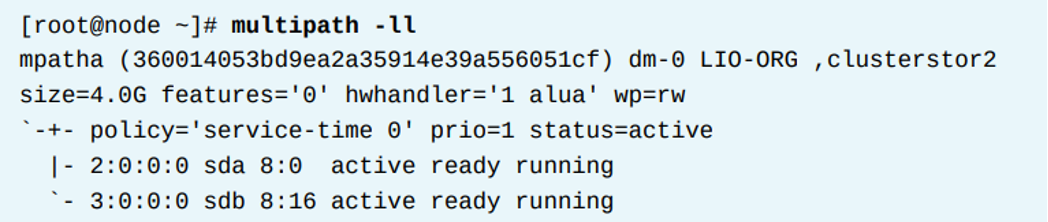
다른 예시
- 아래 결과는 시스템이 두번째 multipath device를 가진 것을 보여준다. 이 devie의 이름은 mpatha이다.
- 이 devie는 2개의 포트그룹을 가졌고 각 그룹마다 하나의 path를 가지고 있다.
* path group 정책 식별하기
multipath -ll 명령은 multipath device의 path 그룹화 정책을 명시적으로 보여주지 않는다. 그러나, 명령의 결과를 잘 보면 해당 정보를 추론할 수 있다.
- path 그룹화 정책이 failover인 multipath device 는 각 그룹마다 오직 하나의 path만 가진다.
- 아래 결과는 이 정책의 예시를 보여준다. 각 path 그룹은 단일 path를 포함한다.
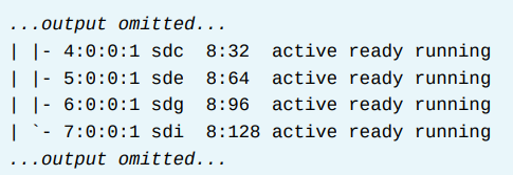
- path 그룹화 정책이 multibus인 multipath device 는 모든 path를 하나의 그룹에 넣는다.
- 아래 예시는 하나의 path group을 보여준다. 모든 path는 하나의 group의 멤버가 된다.
* Failover 확인하기
multipath -ll 명령어는 multipath device의 failover 활동을 가늠하는데 도움을 준다. 주어진 시간에 단 하나의 path group만 active 상태에 있어야 한다. 남아있는 path group들은 enabled 상태로서 wait 하고 있다. 아래 정상 상태의 예시를 보자.
아래 예시는 passive path group의 한 path가 fail되었을 때 multipath -ll 명령의 결과 내부의 변화를 보여준다. passive path group에 있는 path의 상태가 변경되었다 하더라도, active path group과 여기에 연계된 path의 상태는 변경되지 않고 손상되지 않은 상태로 유지된다.
아래 예시는 active path group이 fail된 것을 보여준다. 이전에 active path (2:0:0:0) 가 failed faulty offline 상태이다. 이에 따라, 이것과 연관된 path group의 상태도 또한 변경된다. active에서 enabled로 변경되는 것이다. passive path group은 active가 된다.
위와 같이 문제가 발생한 후, failed path가 회복된다 하더라도, 현재 active path는 active 인 그대로 남는다. 만약 사용자가 이러한 동작을 컨트롤하고 싶으면 /etc/multipath.conf 파일의 failback이라는 파라미터를 수정하면 된다. 이 failback 파라미터의 default 값은manual이다. manual이면 이전 원래 패스로 돌아가지 않고 그대로 유지하는 것이다.
* References
mpathconf(8), multipath.conf(5), and udevadm(8), multipath(8) man pages
For more information, refer to the Overview of Device Mapper Multipathing and Multipath devices chapter in the Configuring device mapper multipath guide at
iSCSI는 IP기반 네트워크에서 SCSI 명령을 보내기 위한 TCP/IP 베이스 프로토콜이다. 즉 iSCSI 서버는 IP기반 네트워크를 통해 클라이언트에 디스크로 동작하게 하는 블록 스토리지를 제공할 수 있다. iSCSI 서버가 있고, 서버에 연결된 클라이언트에게 디스크를 제공하는 방식이다.
iSCSI는 IP네트워크로 디스크 I/O를 수행하므로, 대역폭을 여유있게 하기 위해 일반적인 서비스 네트워크와는 대역을 분리해야 한다. 일반적으로 고성능을 위해서는 10G 네트워크를 사용한다. WAN 보안을 위해, ISCSI 관리자는 IP 네트워크 트래픽 보안을 위한ipsec 이라는 프로토콜 suite 을 사용할 수 있다.
HA 클러스터에서, 관리자는 종종 공유 스토리지를 모든 노드에 제공하기 위해 iSCSI를 사용한다. 이렇게 하여 클러스터가 관리하는 어플리케이션의 데이터를 공유 스토리지에 저장할 수 있다. 어떤 노드에서든 어플리케이션이 데이터에 접근할 수 있기 때문에, 클러스터는데이터의 복사,복제,이동 등 없이 빠르게 다른 노드에서 재시작할 수 있다.
* iSCSI 서버/클라이언트 구조
target (서버)
- iSCSI 서버에 있는 iSCSI 스토리지 리소스이다.
- target은 유니크 이름을 가져야만 한다. (IQN 참고)
- 각 target은 하나 또는 하나 이상의 블록 디바이스를 제공하거나, logical unit들을 제공한다.
- 대부분의 케이스에서 하나의 target은 정확히 하나의 디바이스를 제공한다.
- 하나의 서버는 여러개의 target을 제공할 수 있다.
initiator (클라이언트)
- iSCSI 에게 디스크를 제공받는 클라이언트는 리모트 서버 스토리지인 target에 SCSI 명령을 보내기 위한 initiator 소프트웨어 구성이 필요하다.
- iSCSI 클라이언트, 일반적으로 소프트웨어로써 사용가능하다.
- 사용자는 또한 HBA iSCSI의 형태로 하드웨어 initiator를 구매할수도 있다.
- initiator는 유니크 이름을 가져야만 한다. (IQN 참고)
- 클라이언트 시스템에서, iSCSI targets은 단순히 SCSI 케이블또는 FC 로 연결된 로컬 SCSI 디스크처럼 보인다.
* iSCSI 서버에서 사용하는 구성요소
여기서 나오는 구성요소들은 iSCSI "서버"를 구축할 때 사용하는 요소이며, 서버 구축은 이 장에서는 다루지 않는다. 개념만 이해해 두면 된다.
IQN (iSCSI Qualified Name)
- initiator와 target 둘다 식별하는 unique worldwide name 이다.
- IQN은 아래와 같은 형태를 가진다
YYYY-MM
DNS 도메인 이름을 처음으로 컨트롤한 첫번째 해와 전체 월. 예를들어, 2020년 6월이라면 2020-06 이다.
com.reserved.domain
예약된 사용자의 도메인 네임. 예를들어, www.example.com 은 -> com.example.com 으로 쓰면 된다. 정해져 있는것은 아니며 자유롭게 사용 가능.
name_string
관리하는 특정 대상을 식별하는 네임스페이스 (YYYY-MM.com.reserved.domain) 의 고유 문자열이다. 관리하는 특정 대상을 식별하는 것으로, 직접 자유롭게 만들면 된다. 예약된 도메인 이름이 정확히 하나의 target을 가진 단일 서버의 특정한 호스트 이름인 경우 생략하기도 한다.
portal
각 target은 하나 또는 그이상의 portal을 가진다. portal은 해당 target에 도달 할 수 있도록 initiator가 사용할 수 있게 하는 ip주소와 포트 쌍을 가진다.
LUN (Logical Unit Number)
LUN은 target에 의해 제공되는 블록장치를 대표한다. 각 target은 하나나 하나 이상의 LUN을 제공한다. (그러므로, 하나의 target은 여러개의 스토리지 디바이스를 제공할 수 있다)
ACL (Access Control List)
접근 권한을 식별하기 위해서 initiator의 IQN이 사용하는 접근 제한. Initiator의 IQN을 사용하여 액세스 권한을 검증하는 액세스 제한이다.
TPG (Target Portal Group)
TPG는 target에 대한 완전한 구성이다. portal, LUN, ACL이 포함된다. (Portal, LUN, ACL이 합쳐져 하나의 TPG) 거의 모든target은 하나의 TPG를 사용한다. 하지만 advanced configuration에서는 여러 개의 TPG를 정의하는 경우도 있다.
* iSCSI 클라이언트 구성하기
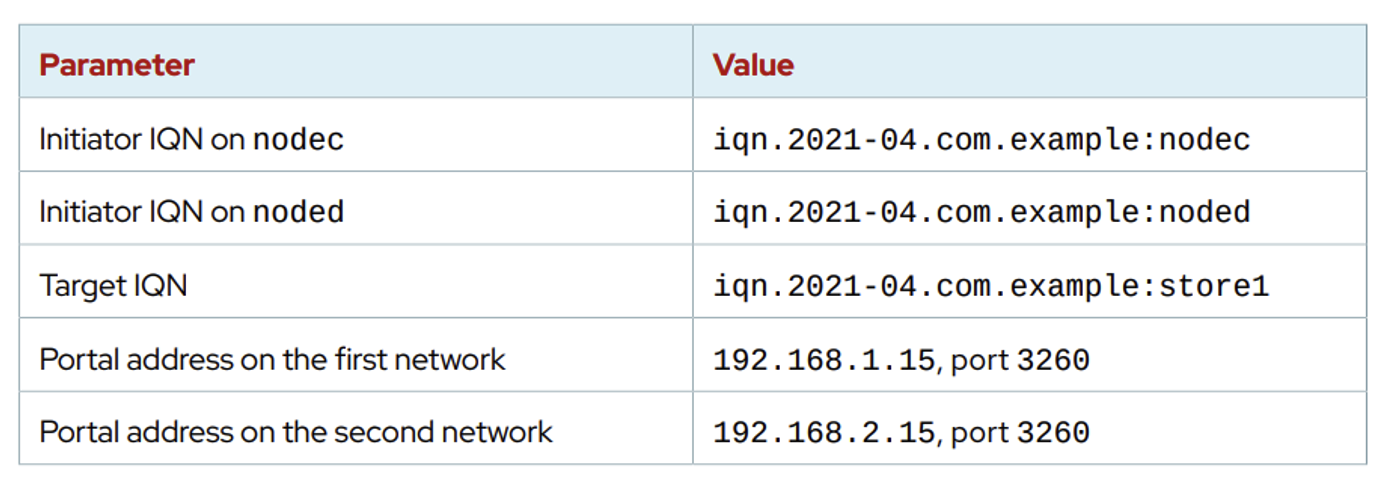
여기서는 iSCSI 서버는 이미 구성되어 있다고 가정하고 클라이언트 구성법만 제공한다. 연결을 위한 정보는 다음과 같다.
1. 패키지 설치
iSCSI 클라이언트 initiator를 구성하는것은 iscsi-initiator-utils 패키지 설치가 요구된다. 이 패키지에는 iscsi, iscsid 서비스가 포함되어 있고, /etc/iscsi/iscsid.conf와 /etc/iscsi/initiatorname.iscsi 구성파일이 포함되어있다. 아래와 같이 설치를 진행한다.
2. initiator 의 IQN 생성
iSCSI initiator 로서, 클라이언트는 자신의 유니크한 IQN이 있어야 한다. 해당 IQN은 iSCSI 서버에 등록되어 있어서, 연결시 이 IQN이 일치해야만 연결이 가능하다. iscsi-initiator-utils를 설치한 후에, /etc/iscsi/initiatorname.iscsi 파일에서 관리자는 일반적으로 이 파일에 있는 IQN을 그들의 도메인 명 등으로 입맛에 맞춰 수정한다. vi로 /etc/iscsi/initiatorname.iscsi 파일을 열어 위 예시에 맟게 initiator IQN을 구성한다.
InitiatorName=iqn.2021-04.com.example:noded
3. iscsid.conf 구성
/etc/iscsi/iscsid.conf 파일은 연결할 target의 디폴트 세팅을 포함한다. 이 세팅에는 iscsi timeout이나 retry 파라미터 등이 있고, 인증을 위한 유저명과 패스워드 등이 있다. 여기서는 아무것도 건드리지 않고 default 값으로 진행한다.
4. iSCSI 서비스 실행 및 자동시작 구성
이 패키지는 자동으로 iscsi와 iscsid 서비스를 구성한다. 그래서 시스템 부팅시 initiator는 자동으로 이전에 discover된 target을 재연결한다. 이러한 재연결을 위해서는 iscsid 데몬이 서버 실행시 실행되어야 한다. 다음 명령어로 구성한다. 또한 initiator의 configuration file을 수정하는 경우, iscsid 서비스를 재시작해야 한다.
systemctl start iscsid / systemctl enable iscsid
5. iSCSI target (서버) 찾기
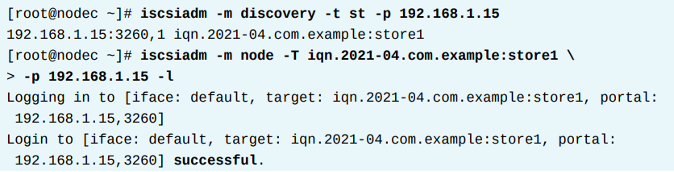
iSCSI장치를 사용하고 연결하기 전에, 해당 target을 먼저 discover해야 한다. discover 절차는 target 정보를 저장하고, default인/etc/iscsi/iscsid.conf를 사용하여 /var/lib/iscsi/nodes/ 의 디렉토리에서 세팅을 구성한다. 아래 명령어를 통해 원격 target을 discover 할 수 있다. 이명령은 사용가능한 target의 IQN 넘버를 리턴한다.
- portal_ip : target portal의 ip주소
6. iSCSI target (서버) 연결하기
discover 명령에서 확인된 target의 IQN을 명시하여 연결한다.
# 주의사항
동시에 동일한 target에서 동일한 파일시스템을 마운트하기 위해 multiple initiator를 허용하지 말 것. local block device와 다르게, 각각의(여러개의) 원격 initiator는 iSCSI block device를 네트워크를 통해 discover 할 수 있다. 로컬 파일시스템, 예를들어 ext4, xfs등은 여러 시스템에서 동시에 마운트하는것을 지원하지 않는다. 그렇게 하면 파일을 읽을 때 파일시스템 무결성이 깨지고 커럽션이 발생한다.
# 연결이 잘 안되는 경우
discover는 성공했는데 initiator가 discover 된 target에 로그인하는데 문제를 겪는 경우, 이 문제는 access control이나authentication에 문제가 연관되어 있을 수 있다. 액세스를 허용해야 하는 initiator의 IQN을 iscsi 서버에 있는 iscsi target에 명시함으로써 권한을 부여된다. 즉 initiator의 이름이 iscsi target 서버에 등록되어 있어야 한다는 것이다. 클라이언트에서는 위 절차 2번 항목에서IQN을 명시한다. 이부분이 오타나 문제가 있을 수 있으므로 확인을 해봐야 한다. 만약 /etc/iscsi/initiatorname.iscsi 파일을 수정했다면iscsid 서비스를 재시작해야 한다. 또한 iscsi target 서버에서도 특이사항이 있을 수 있으므로 확인이 필요하다.
7. 연결된 디스크 장치 식별하기
이 시점에서, 서버에는 새로운 SCSI 블록 디스크가 등록되며, 시스템은 로컬로 연결된 디스크처럼 해당 디스크를 감지한다. 현재 iSCSI 로그인 세션에 대한 정보를 print level 3 으로 표시하는 iscsiadm --mode session --print 3 명령으로 새 장치를 식별할 수 있다.
또는 dmesg, tail /var/log/messages 또는 ls - l /dev/disk/by-path/*iscsi* 명령의 출력을 살펴볼 수도 있다. 이 로그인 프로세스는 재부팅 시에도 지속되므로, 따라서 부팅 후 자동으로 block device를 사용할 수 있다.
8. 식별된 장치를 포맷하여 사용하기
블록 장치가 이미 파티션/파일시스템 또는 lvm 볼륨을 가지고 있다면, mount 같은 명령어로 데이터에 접근할 수 있다. lsblk --fs 명령으로 이러한 구조를 확인할 수 있는데, 아래에서는 /dev/sda는 3개의 파티션이 있고 (OS 영역), /dev/sdb는 LVM 물리적 볼륨이고 파일시스템이 있다. 즉 마운트할 수 있다. 그리고 /dev/sdc는 아무것도 없다. 사용하려면 파일시스템을 생성해야 한다. (아래 예시는 이 iSCSI 클라이언트 구성 예시와 관계 없음)
7번 진행된 부분의 연장선으로 (/dev/sda가 등록된 것) 연결된 디스크가 /dev/sda이고, 아무것도 없다면 아래처럼 파일시스템을 구성하여 마운트하고 사용할 수 있다.
(1) 파일시스템 생성 (ext4 사용()
(2) 마운트 포인트 생성
(3) uuid 확인
(4) /etc/fstab에 설정
#참고 : iSCSI 디스크를 /etc/fstab에 등록하는 경우, 다음 지침을 따라야 한다.
첫번째, lsblk --fs 명령을 사용하여 파일시스템의 UUID를 확인하고, 파일시스템 마운트 시 해당 UUID를 사용하도록 한다. 디바이스 네임(/dev/sda같은) 를 쓰지 않는다. 이것은 부트할 때 바뀔 수 있기 때문이다. device name은 iSCSI device가 네트워크를 통해 응답한 순서에 따라 달라진다. 만약 /etc/fstab에 device name으로 등록을 하고 리부팅 후에 이름이 바뀐다면, 시스템은 잘못된 마운트 포인트에 마운트할것이다. 두번째, /etc/fstab에서 _netdev 마운트 옵션을 사용한다. iSCSI는 원격 장치에 접근시 네트워크에 의존하므로, 이 옵션을 사용하면 네트워크와 initiator가 올라올까지 시스템이 파일시스템을 마운트하려고 시도하지 않게 한다.
(5)마운트 테스트
* 연결된 iSCSI 해제하기
해제를 위해서는 마운트 해제, fstab 수정, iSCSI 로그오프 및 삭제를 해야한다. 아래 예시는 예시일뿐 위 절차와는 관계가 없음.
(1) 마운트 해제
(2) fstab 내용 수정
(3) iSCSI 로그오프
(4) iSCSI 삭제
이렇게 해야 initiator가 부팅할때 해당 target에 자동으로 로그인하지 않는다.
* References
iscsiadm(8) man page
/usr/share/doc/iscsi-initiator-utils/README
Knowledgebase: "What are the advantages and disadvantages to using partitioning on LUNs, either directly or with LVM in between?"
RHEL High Availability Cluster Add-on 은 클러스터 노드 멤버쉽을 컨트롤하기 위한 여러가지 방법을 제공한다. systemd 는 클러스터에 조인되고 클러스터의 한 부분이 되기 위해 클러스터 노드에서 꼭 실행되어야 하는 클러스터 서비스인 corosync 와 pacemaker를관리한다. pcsd가 실행되는 인증받은 노드에서, 클러스터 서비스는 pcs로 컨트롤된다. pcs 명령으로 클러스터를 관리할 수 있다.
* 클러스터 시작/중지하기
pcs cluster start / pcs cluster stop 명령은 클러스터를 각각 시작/중지한다. 이 명령은 명령이 실행되는 해당 노드에서 적용되며, 다른노드는 파라미터로 따로 정보를 주거나, --all로 전체노드를 대상으로 한다. pcs cluster start --all / stop --all 이것은 해당 명령을 치는 노드와 동일한 클러스터에 있는 모든 노드를 시작/중지한다.
단일 클러스터 서비스 시작하기
전체 클러스터 서비스 중지하기
* 클러스터 서비스 enable / disable 하기
pcs cluster enable / disable명령은 systemd로 관리되는 corosync와 pacemaker 두 클러스터 서비스를, 노드가 부팅되었을 때 자동으로 실행할지 말지를 결정한다. enable 하면, 리부팅시 자동으로 클러스터 서비스가 올라가서 클러스터에 조인된다. 두 명령어 모두 해당명령어를 친 노드만 적용되며, 다른 노드를 하려면 파라미터를 줘야하며, 모든 노드도 마찬가지로 파라미터를 줘야한다.
해당 노드에서 enable 수행
특정 노드 enable 수행
모든 노드 enable 수행
* 클러스터 노드를 추가하고 빼기
RHEL High Availability Cluster Add-on 은 클러스터 노드를 즉시 넣을수도, 뺼수도 있다. 이것은 클러스터 내에서 서비스 다운타임 없이 클러스터를 확장하거나, 노드를 교체할 수 있다는 것이다.
클러스터에 새로운 노드 넣기
새로운 노드가 조인되도록 해당 새로운 노드에 다음과 같은 설정이 필요하다. 방화벽 설정 / 펜스 설정 / pcsd 시작 및 enable / hacluster 패스워드 설정 (현재 존재하는 노드와 일치해야 함) 이 4가지 설정 후 아래 절차를 통해 클러스터에 해당 노드를 조인한다.
1. 노드 인증
pcs host auth node.fqdn 명령 사용, 원래 있던 클러스터 노드 사이의 인증.
2. 클러스터에 노드 추가
아래 명령은 현재 클러스터 안에 있는 노드에서 해야하며 정상상태여야 한다.
3. 클러스터 시작 및 enable
노드가 성공적으로 추가되고 인증되면, 시스템 관리자는 새 노드에서 클러스터 서비스를 시작하고 enable한다. 서비스가 이 새로운 노드에 올라가기 전에, 펜싱도 꼭 구성하고 정상작동하도록 해야한다. pcs cluster start node4.example.com / pcs cluster enable node4.example.com 이 명령어가 사용되지 않는 한 새로운 노드는 클러스터의 활성화된 멤버가 되지 않는다.
클러스터에서 노드 제거하기
pcs cluster node remove node.fqdn 명령을 사용하여 노드를 영구적으로 제거할 수 있다. 이 기능은 실제로 클러스터에 노드가 필요하지 않거나, 클러스터 노드를 새 하드웨어로 변경하는 경우 사용한다.
1. 노드 제거
아래 명령은 클러스터 내에 있는 정상 상태의 노드에서 사용해야 하며, 제거될 노드에서 사용하면 안된다.
2. 해당 노드의 펜스 제거
노드가 제거되었기 때문에, 해당 노드의 전용 펜스 장치를 제거하거나 해당 노드가 포함된 공유 펜스 장치를 재구성해야 한다. 아래 예시는해당 노드의 전용 펜스를 제거하는 예시이다.
* 클러스터 노드가 리소스를 실행 하는것을 금지하기
관리자가 일반 클러스터 운영을 중단하지 않고 클러스터 노드의 리소스 실행을 일시적으로 중단해야 하는 경우가 있다. 첫번째로 노드별작업이 필요할 때가 있다. 예를 들어 실행된 노드에 중요한 보안 업데이트를 적용해야 할 때 이러한 상황이 발생할 수 있다. 노드별로standby 모드 전환한 후 업데이트를 적용할 수 있으므로 다운타임을 줄일 수 있다. 두번째로는 리소스 마이그레이션 테스트가 있다. 노드가 standby 모드로 전환되면 리소스가 할당되지 않는다. 현재 노드에서 실행 중인 리소스는 다른 노드로 마이그레이션을 진행하게 된다.
pcs node standby/unstandby 명령은 해당 명령이 실행되는 노드를 standby모드로 만든다. 다른 노드도 인수로 주거나, --all옵션으로전체를 할 수 있다.
standby 모드는 해당 노드에 resource constraint 가 세팅되는것이고, pcs cluster unstandby는 해당 resource constraint 를 삭제하는 것이다. resource constraint를 제거한다고 하여, 해당 노드가 원래 standby전에 리소스가 있었다면 그게 반드시 다시 마이그레이션되는것은 아니다. (원래 리소스가 원복되는것이 아니라 변경 없이 그대로 있게 된다)
* 클러스터 상태 보기
클러스터 상태, corosync 상태, 구성된 리소스 그룹, 리소스, 클러스터 노드 상태는 pcs status 로 본다. 아래 명령어들로 특정 일부만 볼수도 있다. 또한 pcs status --full 모든 전체값을 확인할 수 있다.
pcs status cluster : 클러스터 상태만 확인
pcs status resources : 리소스 그룹과 각각의 리소스들만 확인
pcs status nodes : 구성된 클러스터 노드만 확인
pcs status corosync : corosync 상태만 확인
pcs status pcsd : 모든 구성된 클러스터 노드의 pcsd 상태만 확인
1. node3.example.com 은 현재 스탠바이 모드이다.
2. node1.example.com / node2.example.com 은 현재 완전히 작동중이다.
3. node4.example.com 은 현재 오프라인이다. 클러스터 서비스 두개가 멈춰있거나, 클러스터의 Quorum 문제가 있을 수 있다.
* References
pcs(8), corosync(8), and pacemaker(8) man pages
For more information, refer to the Managing cluster nodes chapter in the Configuring and managing high availability clusters at
클러스터 관리자로서 필요에 따라 리소스와 리소스 그룹을 start/stop, 이동 등을 수행한다. 또한 클러스터의 특정 리소스/리소스 그룹을 특정 노드에 대하여 임시로 마이그레이션을 제한하거나, 현재 실행중인 노드가 아닌 다른 노드로 이동시키거나, 리소스가 특정 노드로 다시 마이그레이션 하는 것들을 컨트롤할 수 있다. 이러한 컨트롤은 특정 클러스터 노드 유지보수시 필요하며, 클러스터 운영에 수동으로 개입하여 서비스 이동을 가능한 줄임으로서 서비스 다운타임을 최소화 할 수 있다.
* 클러스터 리소스 활성화/비활성화 하기
클러스터 리소스/리소스그룹을 실행되지 않도록 또는 실행되도록 컨트롤한다.
리소스 disable / enable 개념
리소스 disable : 해당 리소스를 멈추고 다시 시작하지 않도록 한다.
리소스 enable : 클러스터가 해당 리소스를 시작할 수 있게 한다.
리소스 disable/enable 예시
원래 아래와 같이 리소스가 수행중이다.
아래 명령으로 firstweb 리소스를 disable 수행한다.
상태를 보면 stopped 된 것을 알 수 있다.
constraint에서는 따로 설정된 제한은 없다.
다시 아래 명령으로 firstweb 리소스를 enable 수행한다.
정상적으로 리소스가 시작된다. (시작되는 위치는 클러스터마다 다를 수 있다. 이것은 by design 이다.)
* 클러스터 리소스 이동하기
리소스 move 의 개념
리소스/리소스 그룹은 현재 실행중인 노드에서 다른 노드로 이동할 수 있다. 이동할 노드를 명시하면 해당 노드로 이동할 수 있다. 노드를 명시하지 않으면 가장 적절한 노드로 자동으로 이동한다. 일반적으로 클러스터의 특정 노드 유지보수를 위해 사용할 수 있다. 아래와 같이 실행하면 해당 myresource는 node2.example.com 노드로 이동하게 된다.
이 명령은 아직 배우지 않았지만 리소스를 "이동"시키는게 아니라 constraint 라는 것을 적용하여 이동 "되게" 만드는 것이다. 이동할 노드를 명시하지 않는 경우, 현재 리소스가 있는 노드에 임시 disable 규칙을 적용하여 해당 리소스가 다른 노드로 이동"되게" 만든다. 또한, The move command with a target creates for the original node a Enable rule.
리소스 move 예시
원래 firstweb은 nodea에 있었다. 아래와 같이 명령을 수행해서 이동시킨다.
상태를 보면 nodeb 로 이동한 것을 알 수 있다. (다른 노드로 갈 수도 있다)
constraint를 상세히 보면, firstweb 리소스는 nodea에 대하여 disable 이 된 것을 확인할 수 있다. (nodea에서 disable되었으니 자연히 다른 노드로 이동한다)
* 클러스터 리소스 마이그레이션 제한하기
특정 클러스터 노드에 리소스가 마이그레이션 되지 않도록 막기 위해 "pcs resource ban 리소스명" 명령을 사용할 수 있다. 이 명령은 해당 리소스가 실행되고 있는 노드에서 실행되지 못하게 만든다. 또한 리소스명 뒤에 특정 노드를 입력하면, 해당 리소스가 특정 노드로 마이그레이션 되는것을 막는다. 아래처럼 수행할 수 있다.
이 명령도 move 와 마찬가지로 임시 constraint 규칙을 만드는 것이다. 해당 명령을 수행 후 pcs constraint list 명령으로 새로 생성된constraint 규칙을 확인할 수 있다. 아래 예시에서 myresourcegroup은 node2.example.com에 대하여 ban 된 상태를 알 수 있다.
* 임시 리소스 제한 제거하기
move, ban 명령으로 인해 생성된 임시 constraint는 클러스터 동작에 영향을 주므로 제거가 필요할 수 있다. 기본적으로 다음과 같은 명령을 사용한다. "pcs resource clear 리소스명" 또한 특정 클러스터 노드에 지정된 리소스에 대한 임시 constraint를 제거하기 위해 노드명 파라미터를 추가할 수 있다. 또한 이 명령어는 pcs constraint 로 설정한 location constraint 에는 영향을 주지 않는다. (임시constraint 만 클리어한다)
예를 들어 node2에 있는 myresource 리소스에 대한 금지 제한을 해제하려면 다음을 실행하면 된다.
예시 - 임시 constraint 클리어 수행하기
위의 "리소스 move 예시" 에서 move 를 수행하여 생성된 constraint 를 삭제해보자.
다시 constraint 리스트를 보면 삭제된 것이 확인된다.
다시 리소스 상태를 보면, 이동했던 nodeb에서 변함없이 잘 실행되고 있는것을 확인할 수 있다.
* constraint 란?
High Availability Add-on에는 3가지 종류의 constraint가 있다. order / location / co-location 이 3가지이며, order는 리소스가 시작/중지되는 순서를 정의하며, location은 리소스가 배치될/배치되지 않을 위치를 정의한다. 그리고 co-location은 두가지의 리소스의 관계를 가지고 리소스 배치를 정의한다. 예를 들어, 특정 두 리소스가 항상 서로 같은 노드에 배치되어야 한다면 co-location constraint를 정의해야 한다. 또 다른 예시로, 어떤 리소스가 가능한한 특정 노드에서만 실행되도록 하고 싶을 수 있다. 이러한 경우 location constraint를 사용할 수 있다.
리소스 그룹은 명시적으로 리소스에 constraint를 지정하지 않고 자연스럽게 constraint를 세팅하는 가장 쉬운 방법이다. 리소스 그룹 안에 모든 리소스들은 내부적으로 서로 co-location constraint를 가진다. 즉 리소스들은 같은 노드에 있어야만 한다. 또한 리소스 그룹 안에 있는 멤버 리소스들은 서로 order constraint 를 가진다. 리소스그룹 내부에서 리소스가 생성된 순서대로 시작/중지하기 때문이다. 또한 리소스 그룹에 포함된 리소스 각각에 constraint를 설정하면 안되고, 리소스 그룹 전체에 constraint를 적용해야 한다.
3가지 각각의 constraint는 고유의 기능과 특성을 가지며, 서로 모두 완전히 다르다. 따라서 각각 개념을 잘 이해해야 한다.
* order constraint
order constraint 는 리소스가 실행되는 순서를 지정한다. 예를들어, 데이터베이스에 액세스하는 리소스는 데이터베이스 리소스가 먼저 올라와야만 사용이 가능하다.
pcs constraint order 설정하기
위와 같이 구성하면, 아래와 같은 효과가 발생한다.
- 만약 리소스 둘다 stop 된 경우, A가 시작되어야만 B도 시작 가능하다.
- 만약 리소스 둘다 실행중인 상태에서, A가 pcs에 의해 disable되는 경우, 클러스터는 A가 stop되기 전에 B를 stop시킨다.
- 만약 리소스 둘다 실행중이고, A가 restart되면, 클러스터는 또한 B도 리스타트한다.
- 만약 리소스 A가 실행되지 않고 있고, 클러스터가 A를 start 할 수 없는경우, B는 stop 된다. 예를 들어 첫 번째 리소스가 잘못 구성되었거나 손상된 경우 이러한 문제가 발생할 수 있다.
* colocation constraint
colocation constraint 는 두개의 리소스가 동일 노드에서 실행되어야만한다(실행되면 절대 안된다) 를 명시한다.
두 리소스/그룹이 동일한 노드에서 꼭 실행되도록 하기
아래 예시는 두개의 리소스/리소스그룹 (A,B)가 서로 함께 실행되게 한다.
Pacemaker는 A먼저 어디 노드에 있어야 할지 체크하고, 그 후에만 B가, 확인된 그곳(A가 있을 곳) 에 위치할 수 있는지 여부를 결정한다. A와 B의 시작은 병렬로 이루어지며, A,B 둘다 실행할 수 있는 위치가 없는 경우 A가 우선권을 가지며 B는 중지된 상태로 유지된다. 만약A가 실행할 위치가 없으면, B도 실행할 곳이 없다.
두 리소스/그룹이 절대 동일한 노드에서 실행되지 않도록 하기
아래 예시는 두개의 리소스/리소스그룹 (A,B)가 서로 함께 실행되지 않도록 한다.
colocation 예시
아래와 같이 nfs와 firstweb 두 리소스 그룹이 있다.
두 그룹을 아래와 같이 코로케이션 하면, nfs가 먼저 실행되고 그 뒤에 firstweb이 실행된다.
constraint 상태를 보면 다음과 같다. 이제 두 그룹은 항상 동일 노드에서 실행된다.
아래와 같이 nfs가 있는 nodea 로 firstweb이 넘어간 것을 확인할 수 있다.
* location constraint
클러스터는 다른 설정이나 constraint가 적용된 것이 없다면 클러스터 전체에 걸쳐 리소스를 고르게 분산시키려고 한다. location constraint는 리소스/리소스그룹이 실행할 노드 위치를 컨트롤할 수 있다. 리소스에 적용된 location constraint는 해당 리소스가 특정 노드/노드들을 선호/비선호하게 만든다.
location constraint의 score
location constraint는 여러 노드중 어떤 노드에 배치될지 결정하기 위해 score 라는 개념을 가진다. 이 score에 따라서 노드를 선호할지, 피할지를 결정한다. 스코어와 효과는 다음과 같다.
INFINITY : 이 리소스는 여기서 실행되어야만 한다 (must)
양수 또는 0 (ex : 10) : 이 리소스는 여기서 실행되어야 한다. (should)
음수 (ex : -5) : 리소스는 여기서 실행되지 않아야 한다. 클러스터는 이 노드를 피한다. (should)
-INFINITY : 이 리소스는 절대 여기서 실행되면 안된다. (must)
리소스는 숫자끼리 경합할 때 가장 높은 score인 노드에 올라간다. 만약 여러 노드가 동일한 score를 가진다면 (예를들어, 둘다INFINITY 인 경우), 그때는 클러스터가 그 중 하나의 노드를 선택해 실행한다. 일반적으로 클러스터는 리소스가 없는 노드를 선호한다. 여러 노드가 서로 다른 점수를 가지는 경우, 그때 클러스터 리소스/리소스그룹은 가장 높은 점수를 가진 노드에서 실행된다. 또한 충분히 높은 점수를 가진 노드를 찾을 수 없는경우, 리소스는 stopped 상태로 남는다.
만약 여러개의 constraint나 스코어가 적용되는 경우, 그것들을 모두 합산해서 총점을 적용한다. 만약 INFINITY에 -INFINITY 를 더하면 결과는 -INFINITY가 된다. (즉 리소스가 항상 노드를 피해야 한다는 constraint가 있다면, 이 constraint가 이긴다)
또한, score를 통해 리소스가 올라갈 노드가 선택이 되었다 하더라도, 또한 colocation constraint도 고려된다. 예를들어, 만약 리소스 A가 리소스 B와 함께 있어야 하고, B는 노드1에서만 실행될 수 있는 경우, 리소스A가 노드2를 선호하는것은 영향이 없다. 리소스A는 B를 따라 노드1에서 실행되게 된다.
현재 score 확인 명령 - crm_simulate -sL
location constraint 선호 설정하기
이 명령은 리소스 또는 리소스 그룹인 A가 해당 node에 실행될 수 있도록 INFINITY 스코어를 가지게 한다. 다른 location constraint가 없다면, 이 설정은 A가 항상 해당 node에서 실행되도록 강제한다. 그게 안되면 클러스터의 다른 노드에서 실행하도록 한다.
A에 대하여 node에 500점 score 주기
location constraint 비선호 설정하기
이렇게 하면 -INFINITY 값을 주게 되며, A에 대하여 해당 node를 가능한 피하게 한다. 즉 가능한 다른 노드에서 A가 실행된다. 만약 다른 노드들중 어떠한것도 사용가능한 노드가 없다면, 리소스는 시작하지 못한다.
단순히 perfer, avoid 설정이나, 스코어를 주는 설정 모두 이러한 변경사항은 즉시 적용되며, 필요한 경우 리소스 이동이 이루어지므로 다운타임에 조심해야 한다.
stickiness 설정
클러스터는 기본적으로 리소스를 이동할 때 비용이 들지 않는다고 가정한다. 따라서 만약 더 높은 스코어의 노드가 사용가능해지면, 클러스터는 리소스를 해당 노드로 재배치한다. 그런데 리소스 이동은 리소스를 내렸다 올리게 되므로 일시적으로 다운타임이 발생하며, 실제 엔터프라이즈 운영에서는 잠깐의 다운타임이라도 아주 큰 영향을 줄 수 있다. 또한 리소스 종류에 따라 재배치에 시간이 많이 걸릴수도 있는데, 이러면 더 영향이 크다. stickiness 설정은 필요하지 않은 리소스 재배치를 피할때 사용한다.
default resource stickiness는 리소스가 현재 실행중인 노드에게 점수를 설정하여 리소스 재배치를 피하게 만든다. (문맥상 최초 실행할때는 하지 않고, 그 다음 실행중인 노드에 점수를 설정한다는 것이다)
예를들어, resource stickiness가 1000으로 세팅되어 있고, 리소스가 선호하는 노드의 location constraint 스코어는 500이라고 하자.
리소스가 시작되면, 리소스는 선호하는 노드에서 실행된다. 만약 선호하는 노드에 장애가 생기는 경우, 그때 리소스는 다른 노드로 이동할 것이다. 그리고 리소스가 이동한 그 노드는 새로운 스코어 1000을 얻는다.
선호하는 노드가 다시 정상화 되었을 때, 선호하는 노드의 스코어는 500이므로 해당 리소스는 선호하는 노드로 돌아가지 않는다.
이제 클러스터 관리자는 편한 시간 (계획된 다운타임 기간 등)에 선호하는 노드로 리소스를 수동 재배치 하면 된다.
default resource stickiness 1000 으로 설정하기
default resource stickiness 설정값을 없애기
리소스 그룹을 위한 리소스 stickiness 는 이 그룹에 실행되고 있는 리소스가 몇개인지 개수에 기반해서 계산된다. 만약 리소스 그룹이 5개의 활성화된 리소스를 가지고 있고 리소스 stickiness가 1000이라면, 그 리소스 그룹의 유효 점수는 5000점을 가진다.
stickiness 설정 보기 (현재 리소스 디폴트 값들 보기)
stickiness 예시
현재 firstweb은 nodeb에서 실행중이다. 따로 score는 없는 상태이다. 이 상태에서 firstweb의 location constraint를 nodea 에서 선호하도록 200 점을 준다.
위 명령 후 firstweb은 nodeb에서 nodea로 이동한다. default resource stickiness 는 0이고 이 값보다 nodea 의 200점이 더 높기 때문이다.
default resource stickiness를 500으로 변경한다.
firstweb에 대하여 nodeb에다 499점을 준다.
리소스 그룹은 바뀌지 않는다.
stickiness 는 원래 prefer 값 (nodea의 200점)에 더하는 게 아니라 stickiness 값 자체가 되는 것으로 보인다. 즉 nodea는 200점, nodeb는 499점인데 stickiness 때문에 nodea가 500이 되고 nodeb는 499로 이기지 못해 리소스 이동이 발생하지 않는 것이다.
* Constraint 관리 명령
constraint 상태 확인하기
pcs constraint list --full
constraint 제거하기
pcs constraint delete id (id는 위에서 나온 결과의 id 부분이다)
* References
pcs(8) and crm_simulate(8) man pages
For more information, refer to the Managing cluster resources, Displaying resource constraints, and Performing cluster maintenance chapters in the Configuring and managing high availability clusters guide at
For more information, refer to the Determining which nodes a resource can run
on, Determining the order in which cluster resources are run, Colocating cluster resources, and Displaying resource constraints chapters in the Configuring and managing high availability clusters guide at
어떠한 서비스는 하나 이상의 리소스로 이루어진다. 리소스는 IP주소, 파일시스템, httpd같은 서비스 등 여러가지가 있다. 사용자에게 서비스를 제공하는데 필요한 가장 작은 구성요소들을 의미한다. 클러스터에서는 이러한 리소스를 직접 실행하거나 중지시키고, 상태를 모니터링한다. 클러스터가 전담하여 이러한 역할을 수행한다.
* 리소스를 실행하는 방식
리소스 실행 방식은 총 3가지가 있다. (LSB, OCF, systemd) 클러스터 관리자는 클러스터 소프트웨어가 어떤 시스템 서비스를 지원하는지 이해하는 것이 중요하다. 서비스 구성 시 최대한의 구성 용이성을 가진 ocf 스크립트를 통해 클러스터가직접 서비스를 지원하는 것이 이상적이다. ocf로 다이렉트 서비스가 안되는 경우, systemd나 lsb 를 쓸 수 있다.
LSB (Linux Standard Base)
/etc/init.d/ 에 들어가는 init 스크립트와 호환되는 LSB 이다. 간단하게 말하면 스크립트로 서비스를 만드는 것이다.
OCF (Open CLuster Framework)
클러스터 리소스에 대한 추가 제어를 제공하기 위해 추가 입력 매개변수를 처리할 수 있는 확장된 LSB init 스크립트인 오픈 클러스터 프레임워크 호환 스크립트이다. /user/lib/ocf/resource.d/provider 에 파일들이 있다. 클러스터에서 여러가지 리소스들을 쉽게 사용하도록 구성한 것이다. 일반적으로 이 형식의 리소스를 가장 많이 사용한다.
systemd
레드햇8에서 서비스를 관리하고 정의하기 위한 표준인 systemd 유닛 파일이다. 이것으로도 리소스를 만들 수 있다.
* 자주 사용하는 리소스 종류
filesystem
파일시스템을 마운트할 때 사용한다. 로컬 파일시스템이 될 수 있고, iscsi나 fc 또는 nfs, smb 등이 가능하다.
ipaddr2
ipaddr2는 유동아이피를 할당한다. 참고로 ipaddr 도 있었는데, 이전에 쓰던아이피 할당 방법이다. 레드햇8에서는, ipaddr은 심볼릭 링크로 ipaddr2에 연결되어 있다.
apache
apache httpd 서비스를 시작하는 리소스이다. 따로 설정하지 않으면, /etc/httpd의 구성을 사용한다.
mysql
이 리소스는 mysql 데이터베이스를 컨트롤한다. stand-alone 운영 / a clone set with external replication / full primary/secondary setup 3가지 방식으로 데이터베이스를 구성할 수 있다.
* 리소스 에이전트
Redhat High Availability 애드온은 클러스터 리소스를 위한 광범위한 지원을 제공한다. 클러스터 리소스들은 agents라고 부르는 스크립트에 의해 관리된다. agents 들은 클러스터 리소스에 대하여 start/stop/monitor 3가지를 하는데 필요하다.
사용가능한 에이전트 리스트 보기 (pcs resource list)
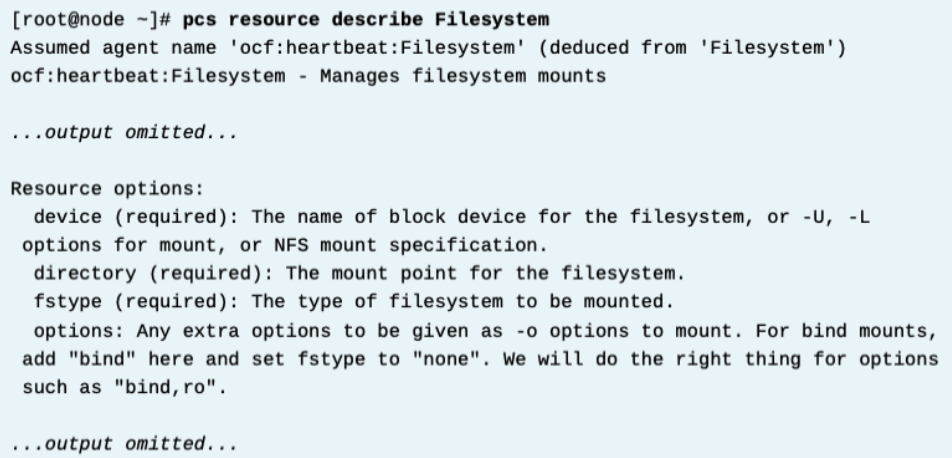
리소스 에이전트 상세정보 보기 (pcs resource describe 에이전트명 --full)
모든 resource agent들은 튜닝할 수 있는 파라미터들을 제공한다. 이 명령은 해당 클러스터 리소스의 설명과 튜닝할 수 있는 파라미터의 정보를 보여준다.
* 리소스 그룹
일반적으로 실제 클라이언트가 사용하는 서비스는 하나의 리소스로 이루어지지 않는다. 이러한 서비스 단위로 묶어놓은 리소스들을 리소스 그룹이라고 한다. 예를 들어 일반적인 웹 서비스는 IP 주소 리소스, Apache 리소스, 웹 서버의 DocumentRoot 폴더에 대한 공유 파일 시스템 리소스로 구성됩니다.
모든 웹 서비스 리소스가 동일한 클러스터 노드에서 실행되어야 제대로 작동하는 서비스를 제공할 수 있습니다. 이러한 리소스를 함께 묶는 편리한 방법은 동일한 리소스 그룹에 추가하는 것입니다. 동일한 리소스 그룹에 있는 모든 서비스는 리소스 그룹에 추가되는 순서대로 시작되고 역순으로 중지됩니다. 클러스터 노드에 장애가 발생하면 클러스터는 전체 리소스 그룹을 다른 노드로 마이그레이션하고 새 노드에서 리소스를 시작합니다.
예를들어 웹 서비스를 하려고 하는데, 3노드 클러스터에서 ip는 노드1에, 파일시스템은 노드2에, httpd 서비스는 노드3에 있다면 서비스가 성립되지 않는다. 리소스 그룹은 이러한 용도에 따른 리소스들을 한데 모아 한번에 한 노드에서 start/stop 하게 한다. 또한 그룹 안에서는 그룹 안의리소스 순서대로 start/stop 하게 한다.
또한 어떤 경우에는, 리소스 그룹안에 들어간 리소스들끼리 디펜던시가 있는 경우가 있다. 예를 들어 특정 IP 주소에서 수신 대기하도록 구성된 웹 서버는 노드에서 IP 주소를 구성할 때까지 시작할 수 없다. 즉 VIP리소스가 먼저 시작되어야 웹서버 리소스가 시작하게 된다. 일반적으로 리소스는 그룹에 추가되는 순서대로 시작되고, 중지될때는 역순으로 중지된다. 이러한 순서를 컨트롤하기 위해 리소스 생성/추가시 --before resourceid / --after resourceid 를 사용하여 특정 리소스의 전에 또는 후에 리소스를 등록할 수 있다. (리소스 생성 및 추가는 아래 참고)
리소스는 생성된 순서대로 배치되며, 그룹을 명시하면 그룹에 순서대로 들어간다. 이 순서는 리소스 시작/종료에 아주 중요한 부분으로, 운영에 큰 영향을 준다. 따라서 순서를 잘 확인해야 한다. 또한 리소스 그룹에 속하지 않는 리소스를 생성하려면 그룹 옵션은 생략하면 된다.
또한 리소스를 생성할 때는 해당 리소스에 대한 액세스 권한이나, 기본적으로 필요한 것들이 있어야 한다. 예를들어, apache 리소스를 올리려면 httpd 패키지가 설치되어 있어야 하고 방화벽이 해제되어야 한다.
예시 : filesystem 리소스 생성하기
myfs라는 이름을 가진 리소스이며, 디스크 장치는 /dev/sdb1, 마운트 포인트는 /var/www/html 이고 파일시스템 형식은 xfs 이다.
리소스 수정하기
pcs resource update
이미 생성된 클러스터 리소스의 값을 수정하거나 옵션을 변경할 수 있다. 아래 예시를 참고한다.
예시 : 이미 생성된 myfs 리소스의 장치를 /dev/sda1로 변경
리소스 삭제하기
pcs resource delete
더이상 필요하지 않은 경우 리소스 및 리소스 그룹 구성을 제거할 수 있다. 리소스명 또는 리소스그룹명을 명시하여 삭제할 수 있다.
예시 : 리소스 myfs 삭제
* 리소스 동작
리소스는 시작할때, 중지할때, 모니터링할때 3가지의 동작이 있으며, 이 동작들에 대한 주기(interval)과 타임아웃(timeout)이 있다. 주기는 모니터링에만 사용하며, 해당 주기마다 모니터링을 실행한다. 또한 타임아웃은 3가지 동작 모두 적용되며, 해당 타임아웃 시간까지 시작/중지/모니터링이 성공하지 않는경우 문제라고 간주하고 재시작, fence 등을 수행하게 된다.
이러한 주기와 타임아웃값들은 튜닝이 가능하며, 리소스 생성시 명시하여 설정할 수 있다. 형식은 아래 예시와 같다. webserver 라는 리소스를 monitor interval 20 초, timeout을 30초로 주어 생성할 때, 아래처럼 한다.
리소스 동작 값을 넣을 때는 op 로 시작하며, op monitor/start/stop interval= timeout= 이런식으로 명시한다. 다른 예시로, op monitor interval=20s timeout=30s start timeout=60s stop timeout=120s 이런식으로 사용할 수 있다.
시작 타임아웃을120초로 하고,모니터 인터벌을 30초로 하고, 모니터가 fail되면 fence 한다.
만약 리소스가 start 하는데 fail 된 경우, 그때는 리소스의 failcount가 INFINITY 로 세팅되어 해당 노드에서 리소스가 영원히 실행되지 않도록 막는다. 존재하는 failcount값은 pcs resource failcount show 로 확인이 가능하다. fail의 원인을 트러블슈팅하기위해, [pcs resource debug-start 리소스명] 을 사용하면 리소스 시작 시도의 오류 메시지를 표시하여 해당 부분을살펴보고 문제를 복구할 수 있다. 리소스가 복구되면, [pcs resource cleanup 리소스명] 을 사용하여 해당 리소스의Failcount를 리셋시켜야 해당 노드에서 해당 리소스가 다시 시작할 수 있다.
* 리소스 동작값의 추가 / 제거
리소스 동작값 추가
리소스의 operation은 pcs resource op add 명령으로 추가할 수 있다. 예를들어, 현재 있는 webserver 리소스에다가 모니터링 인터벌 10초, 모니터링 타임아웃 15 초, 그리고 모니터링이 fail되면 펜스시키는 옵션을 주는 경우, 아래처럼 한다.
리소스 동작값의 제거
pcs resource op remove 명령으로 제거할 수 있다. 아래처럼 webserver 리소스에서 op 값을 제거한다.
* 리소스 그룹 생성 예시 : 웹 서비스
클러스터된 웹 서비스는 3가지의 리소스를 요구한다.
1. Virtual IP : 퍼블릭 네트워크를 통해 아파치 웹서버에 의해 서비스되는 컨텐츠에 접속할 수 있도록 함. 각 노드들은 정해진 ip를 가지지만, 이 ip를 서비스 운영에 사용하면 노드가 죽었을 때 접속하지 못하는 문제가 발생한다. 이를 막기위해 노드 간 이동하는 대표 Virtual IP가 필요하다.
2. 파일시스템 : 아파치 웹서버에 의해 저장된 데이터들. (이론적으로는 모든 노드에 모든 웹 콘텐츠를 보유하는 것도 가능하지만 콘텐츠를 동기화하는 메커니즘이 필요합니다.)
3. apache 리소스 : httpd 서비스를 제공
1. Virtual IP
첫번째로 VIP가 필요하다. 아래와 같이 VIP를 생성한다. 당연히 해당 IP는 각 노드들의 네트워크 장치가 접근 가능한 대역으로 설정해야 한다.
2. 공유 스토리지
# 중요
클러스터 노드에서 SELinux를 활성화한 경우, 클러스터 관리자는 마운트된 파일 시스템의 콘텐츠를 관련 데몬에서 사용할 수 있는지 확인해야 합니다. 또한 block device 의 경우 적절한 SELinux 컨텍스트를 설정해야 하며, NFS의 경우 관련 SELinux booleans, (예: httpd_use_nfs=1)을 설정해야 합니다.
3.웹 서비스
홈페이지 파일을 서비스하는 apache (httpd) 리소스를 생성해야 한다. 이를 위해 httpd 패키지 설치가 필요하며 방화벽 해제도 필요하다. 또한 /var/www/html에 index.html 파일도 필요하다.
위와 같이 생성 후, curl 172.25.99.80 명령을 수행하면 index.html 파일을 읽어올 수 있다.
* 리소스 그룹에 리소스 추가/제거
리소스를 리소스 그룹에 추가하기
현재 존재하는 리소스는 리소스 그룹에 추가될 수 있다. 클러스터 관리자는 pcs resource group add groupname resourcename 명령으로 추가할 수 있다. 만약 해당 리소스가 이미 다른 그룹의 멤버라면, 위 명령어를 쳤을 때 현재 그룹에서 빠지고 명령어에 명시된 그룹에 추가되게 된다. 명시한 그룹이 없는 그룹이라면, 자동으로 그룹을 만들게 된다.
예시 : myresource 라는 리소스를 mygroup 에다 추가하려면 아래처럼 한다.
리소스를 리소스 그룹에서 제거하기
pcs resource group remove groupname resourcename 명령으로 리소스를 리소스 그룹에서 제거할 수 있다. 해당 리소스는 여전히 클러스터에 존재하지만, 해당 리소스 그룹에서는 빠지게 된다. 만약 리소스 그룹에 하나만 남은 리소스를 제거하면, 해당 리소스 그룹도 없어지게 된다.
예시 : myresource 라는 리소스를 mygroup 리소스그룹에서 제거하려면 아래처럼 한다.
* 기타 리소스 확인 명령어
pcs resource status : 구성된 리소스와 리소스 그룹에 대한개요, 리소스 상태를 볼 수 있다.
pcs resource config : 구성된 리소스의 상세 속성과 operation, 정보 확인
* References
pcs(8) man page
For more information, refer to the Configuring cluster resources chapter in the Configuring and managing high availability clusters guide at