설치할것 3주차
파이썬 설치하기
https://www.python.org/downloads/
download python 3.8.x 버튼 눌러서 설치하기.
프로그램 실행
add python 3.8 to path 를 꼭 체크해줘야 함.
파이썬 설치할 때 32비트던데, 64비트는 왜 안씀?
몽고디비 설치하기
c드라이브에 /data/db 라고 디렉토리 만들기.
https://www.mongodb.com/try/download/community
몽고디비 커뮤니티 서버를 받아야 하며, 운영체제는 내 운영체제에 맞게 선택하고 다운.

설치시 커스텀을 선택하고,
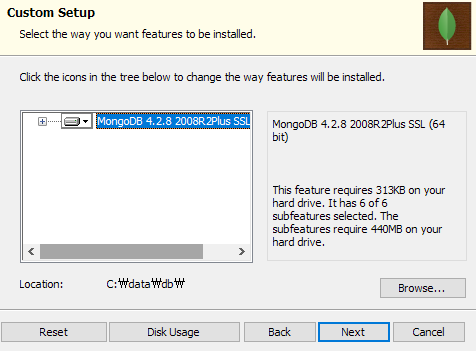
위치만 아까 만든 디렉토리로 바꾼다.
여긴 기본값 그대로 넘어간다.

컴퍼스는설치하지 않는다.
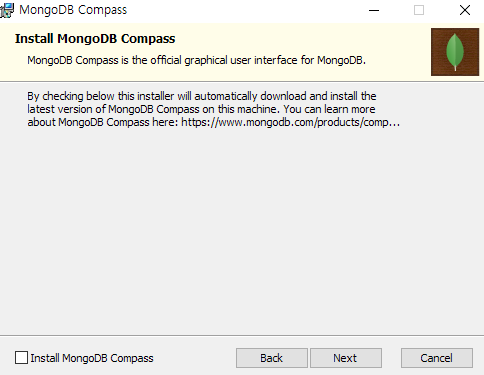
이런 메시지 뜨면 ignore

다끝나면 리스타트하라고 보내느데 일단 나중에.
환경 변수설정을 위해 다음을 들어간다.

여기서 환경변수를 누른다.
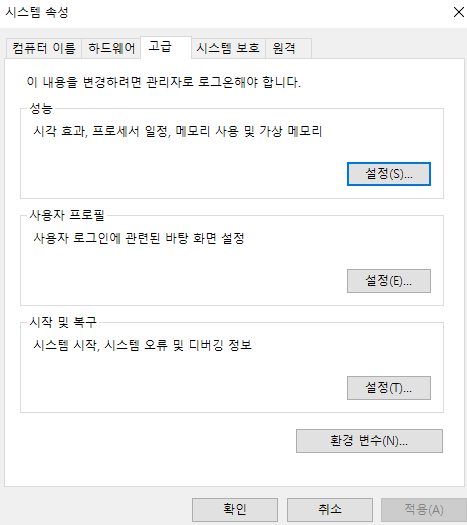
시스템 변수 (사용자변수 아님)에 path를 찾아 편집을 누른다.

오른쪽상단에 새로만들기 누르고, 아까 몽고디비가 깔린 경로에 bin까지 들어간 경로를 넣어준다.

완료.
몽고디비 시작
윈도우 cmd 에서 mongod 치면 실행됨.

이런식으로 나옴. (끄면 안될 것 같은데, 원격강사는 꺼도 된다고 함;; 끄고 한번 해보자)
브라우저 가서,
localhost:27017 쳐서 다음과 같이 나오면 잘 실행되고 있다는 것임
robo3t 설치
https://robomongo.org/download
오른쪽 거 받아야 함.
상단 exe 선택

이건 그냥 다음다음다음 쭉쭉쭉 하면 설치하면 됨.
git bash 설치하기 (윈도우만)
https://tnsgud.tistory.com/648 참고
https://git-scm.com/ 에 들어가서,

다운로드 선택
64비트 git for windows setup 선택
설치중 선택할 게 엄청 많은데, 싹 다 next로 넘어감.
=========================================================
2주차 복습
스파르타가 만든 영화 가져오는 openapi 사용하기
api 주소 : API주소(GET 요청) → http://spartacodingclub.shop/post
빈 메모장에, 해당 api를 통해 아래처럼 영화를 가져오기.
나홀로 메모장에 들어가는 **아티클들의 정보를 불러오는 OpenAPI**입니다.
서버에서 JSON 형식으로 아티클 정보(articles)를 응답(response) 데이터로 보내주죠!
이 API를 써서 '저장된 포스팅 불러오기' 기능을 만들어볼게요!
(나중에 이 API를 우리가 직접 만들어 볼겁니다)
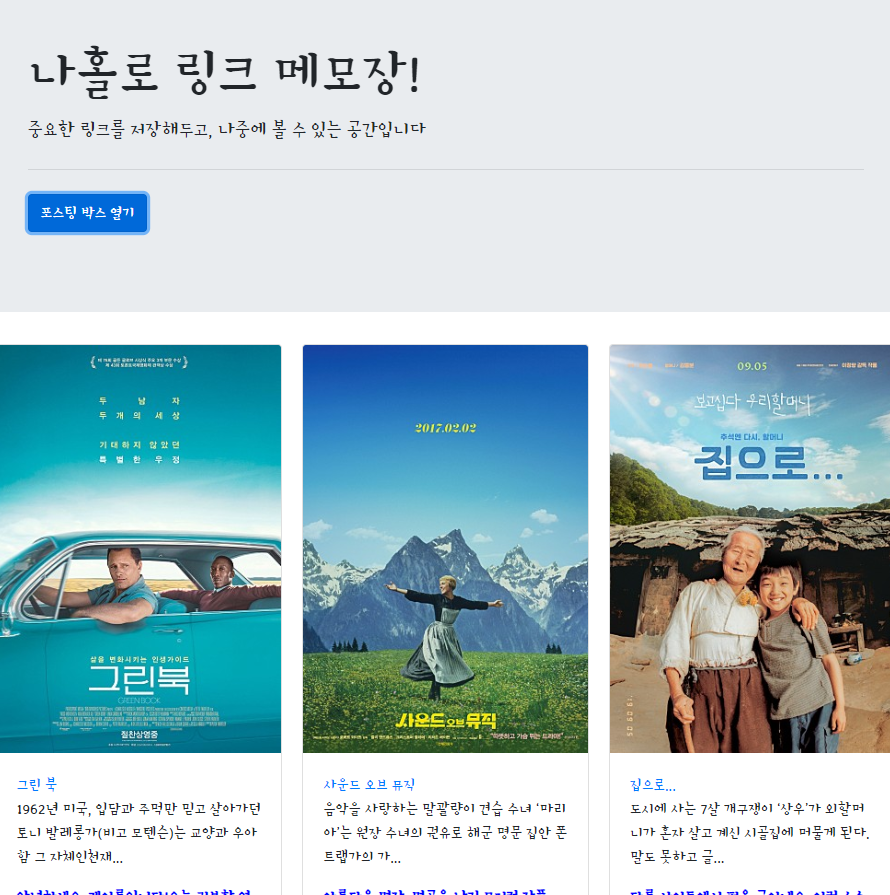
api 훑어보기

값이 있고 그 아래 articles 라는 리스트 안에 딕셔너리 자료들이 있다. 딕셔너리는 형태가 동일하다.
comment, desc, image, title, url
참고
크롬에서 주소 입력해서 엔터 = get요청 = ajax get 요청 모두 동일
일단 홈페이지를 들어가면 바로 api를 접근해서 데이터를 받아오는 식으로 할것임.
그러므로 ready 함수가 필요하다.
$(document).ready(function(){
showPost();
});즉, html에 영화내용은 없다가, html에 접속하면 showPost()함수가 시작하여 영화내용 데이터 카드들을 가져오는것.
function showPost() {
$.ajax({
type: "GET",
url: "http://spartacodingclub.shop/post",
data: {},
success: function(response){
console.log(response);
}
});
}이렇게 하면, response에 저 json값들이 다 들어가므로 response['article'][i]['comment'] 이런식으로 접근할 수 있음.
이제 ajax를 수정한다. 카드를 가져오도록.
즉 따로 카드(html)을 만드는 함수를 만들고 ajax에서 그 함수를 돌려서 카드를 해당 api내용만큼 만드는 식으로 하고, 그 값을 ready함수에 넣고.. 이런식으로 최종적으로 만들 수 있다.
완료
<!Doctype html>
<html lang="ko">
<head>
<!-- Required meta tags -->
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<!-- Bootstrap CSS -->
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/css/bootstrap.min.css"
integrity="sha384-Gn5384xqQ1aoWXA+058RXPxPg6fy4IWvTNh0E263XmFcJlSAwiGgFAW/dAiS6JXm" crossorigin="anonymous">
<!-- JS -->
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.12.9/umd/popper.min.js"
integrity="sha384-ApNbgh9B+Y1QKtv3Rn7W3mgPxhU9K/ScQsAP7hUibX39j7fakFPskvXusvfa0b4Q"
crossorigin="anonymous"></script>
<!-- 구글폰트 -->
<link href="https://fonts.googleapis.com/css?family=Stylish&display=swap" rel="stylesheet">
<title>스파르타코딩클럽 | 나홀로 메모장</title>
<!-- style -->
<style type="text/css">
* {
font-family: 'Stylish', sans-serif;
}
.wrap {
width: 900px;
margin: auto;
}
.comment {
color: blue;
font-weight: bold;
}
#post-box {
width: 500px;
margin: 20px auto;
padding: 50px;
border: black solid;
border-radius: 5px;
}
</style>
<script>
function openClose() {
// id 값 post-box의 display 값이 block 이면(= 눈에 보이면)
if ($("#post-box").css("display") == "block") {
// post-box를 가리고
$("#post-box").hide();
// 다시 버튼을 클릭하면, 박스 열기를 할 수 있게 텍스트 바꿔두기
$("#btn-post-box").text('포스팅 박스 열기');
} else {
// 아니면(눈에 보이지 않으면) post-box를 펴라
$("#post-box").show();
// 다시 버튼을 클릭하면, 박스 닫기를 할 수 있게 텍스트 바꿔두기
$("#btn-post-box").text("포스팅 박스 닫기");
}
}
$(document).ready(function () {
$("#cards-box").empty(); // 일단 비우고 (원래 밑에 있는 데이터때문)
showPost(); // 자동으로 아래 포스트를 실행한다. 브라우저 새로고침하거나 들어갈 때
});
function showPost() {
$.ajax({
type: "GET",
url: "http://spartacodingclub.shop/post",
data: {},
success: function (response) {
let articles = response['articles'];
for (let i = 0; i < articles.length; i++) {
let article = articles[i];
makeCard(article["image"], article["url"], article["title"], article["desc"], article["comment"]);
}
}
});
}
function makeCard(image, url, title, desc, comment) {
let tempHtml = `<div class="card">
<img class="card-img-top" src="${image}" alt="Card image cap">
<div class="card-body">
<a href="${url}" target="_blank" class="card-title">${title}</a>
<p class="card-text">${desc}</p>
<p class="card-text comment">${comment}</p>
</div>
</div>`;
$("#cards-box").append(tempHtml);
}
</script>
</head>
<body>
<div class="wrap">
<div class="jumbotron">
<h1 class="display-4">나홀로 링크 메모장!</h1>
<p class="lead">중요한 링크를 저장해두고, 나중에 볼 수 있는 공간입니다</p>
<hr class="my-4">
<p class="lead">
<button onclick="openClose()" id="btn-post-box" type="button" class="btn btn-primary">포스팅 박스 열기</button>
</p>
</div>
<div id="post-box" class="form-post" style="display:none">
<div>
<div class="form-group">
<label for="post-url">아티클 URL</label>
<input id="post-url" class="form-control" placeholder="">
</div>
<div class="form-group">
<label for="post-comment">간단 코멘트</label>
<textarea class="form-control" rows="2"></textarea>
</div>
<button type="button" class="btn btn-primary">기사저장</button>
</div>
</div>
<div id="cards-box" class="card-columns">
<div class="card">
<img class="card-img-top"
src="https://www.eurail.com/content/dam/images/eurail/Italy%20OCP%20Promo%20Block.adaptive.767.1535627244182.jpg"
alt="Card image cap">
<div class="card-body">
<a href="#" class="card-title">여기 기사 제목이 들어가죠</a>
<p class="card-text">기사의 요약 내용이 들어갑니다. 동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라만세 무궁화 삼천리 화려강산...</p>
<p class="card-text comment">여기에 코멘트가 들어갑니다.</p>
</div>
</div>
<div class="card">
<img class="card-img-top"
src="https://www.eurail.com/content/dam/images/eurail/Italy%20OCP%20Promo%20Block.adaptive.767.1535627244182.jpg"
alt="Card image cap">
<div class="card-body">
<a href="#" class="card-title">여기 기사 제목이 들어가죠</a>
<p class="card-text">기사의 요약 내용이 들어갑니다. 동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라만세 무궁화 삼천리 화려강산...</p>
<p class="card-text comment">여기에 코멘트가 들어갑니다.</p>
</div>
</div>
<div class="card">
<img class="card-img-top"
src="https://www.eurail.com/content/dam/images/eurail/Italy%20OCP%20Promo%20Block.adaptive.767.1535627244182.jpg"
alt="Card image cap">
<div class="card-body">
<a href="#" class="card-title">여기 기사 제목이 들어가죠</a>
<p class="card-text">기사의 요약 내용이 들어갑니다. 동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라만세 무궁화 삼천리 화려강산...</p>
<p class="card-text comment">여기에 코멘트가 들어갑니다.</p>
</div>
</div>
<div class="card">
<img class="card-img-top"
src="https://www.eurail.com/content/dam/images/eurail/Italy%20OCP%20Promo%20Block.adaptive.767.1535627244182.jpg"
alt="Card image cap">
<div class="card-body">
<a href="#" class="card-title">여기 기사 제목이 들어가죠</a>
<p class="card-text">기사의 요약 내용이 들어갑니다. 동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라만세 무궁화 삼천리 화려강산...</p>
<p class="card-text comment">여기에 코멘트가 들어갑니다.</p>
</div>
</div>
<div class="card">
<img class="card-img-top"
src="https://www.eurail.com/content/dam/images/eurail/Italy%20OCP%20Promo%20Block.adaptive.767.1535627244182.jpg"
alt="Card image cap">
<div class="card-body">
<a href="#" class="card-title">여기 기사 제목이 들어가죠</a>
<p class="card-text">기사의 요약 내용이 들어갑니다. 동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라만세 무궁화 삼천리 화려강산...</p>
<p class="card-text comment">여기에 코멘트가 들어갑니다.</p>
</div>
</div>
<div class="card">
<img class="card-img-top"
src="https://www.eurail.com/content/dam/images/eurail/Italy%20OCP%20Promo%20Block.adaptive.767.1535627244182.jpg"
alt="Card image cap">
<div class="card-body">
<a href="#" class="card-title">여기 기사 제목이 들어가죠</a>
<p class="card-text">기사의 요약 내용이 들어갑니다. 동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라만세 무궁화 삼천리 화려강산...</p>
<p class="card-text comment">여기에 코멘트가 들어갑니다.</p>
</div>
</div>
</div>
</div>
</body>
</html>
완료===========================================
이제 3주차는 직접 서버를 구축하는 쪽의 개념임

파이썬 시작
파이썬을 설치한다는 것은, 일종의 번역팩, 즉 컴퓨터는 2진수만 쓰는데, 파이썬문법으로 된 것을 컴퓨터가 읽을 수 있도록 번역해주는 번역기를 설치하고, 프로그래밍을 돕는 기본코드오 ㅏ함수들을 설치하는것.
파이썬은 매우 직관적인 언어이고, 할 수 있는 것도 많습니다. 그런데, 개발자들도 모든 문법을 기억하기란 쉽지 않습니다. 오늘 배우는 것 외에 필요한 것들은 구글링해서 찾아보면 됩니다. (추천 검색어 : python 찾고자_하는_기능)
또한 파이썬은 할 수있는것도 많고 모든 문법을 개발자가 기억하고 있는것도 아님.
여기서 배우는 것외에 필요한 것들은 구글링하면 된다.
추천 검색어 : python 찾고자_하는_기능
만약 configure python interpreter.. 이런식으로 나오는 경우,


파이썬에서 결과 바로바로 보는 콘솔 열기

파이참에서 파이썬 구문 바로 실행하기 : ctrl+shift+f10
파이썬도 보통 프로그래밍언어처럼 변수, 자료형(리스트, 딕셔너리등), 함수, 조건, 반복문 정도를 이해하면 된다.
파이썬에서 이름지을때는 보통 snake style을 사용함. 변수는 명사형, 함수는 동사형
파이썬 공식 스타일 가이드
pep8 : https://www.python.org/dev/peps/pep-0008/
파이썬자습서-코딩스타일https://docs.python.org/ko/3/tutorial/controlflow.html#intermezzo-coding-style
파이썬의 특징
리스트 안에 딕셔너리가 있는데, 들어간 것과 다른 딕셔너리 혁식의 딕셔너리를 넣었음. 그럼 잘 들어감. 딱히 문젝 없고 매우 유연함. 아무거나 다 넣을 수 있어서 좋음 그래서 일관성을 잘 만들어야 하며, 문제가 있어도 모를 수 있음.
자바스크립트는 중괄호로 여러가질 나눴는데, 파이썬은 중괄호가 없음. 들여쓰기로 구분한다. 들여쓰기 안맞으면 에러남.
함수, if 같은 정의를 쓸 때 끝에 : 를 붙인다.
return은 해당 조건이 맞으면 바로 끝난다.
for 문에다가 특정 조건을 주고 return을 하면, 그 조건에 맞으면 for문은 그냥 끗.
반복문, 조건문에서 중간에 끝낼라면 리턴을 넣으면 됨.
프로그래밍언어를 다 외울려고 하지 말자.어차피 못한다. 우린 다른것도 해야 하잖아.
파이썬 변수와 자료형

a = 3
name = "uktaekim"
print(a+name)
이건 에러남. int와 str은 + 연산이 안됨.
파이썬 에러메시지 뜨면 꼭 읽어보자 에러메시지 뜨면, 에러메시지 제대로 복사해서 구글링해보자. 잘 나온다.


파이썬 함수

조건문
형식이 조금 다를 뿐, 논리는 같다.
if 하고 조건을 준 후 : 로 마무리한다.
그게 맞다면, 아래 구문을 넣고, 아니라면(else) else 밑에 구문을 넣는다.

반복문
자바스크립트에서 반복문은 반복할 범위도 직접 정해줘서 length함수를 썼었는데, 파이썬에서 반복문은 일단 기본적으로 임의의 열 (sequence, 리스트나 문자열처럼) 의 항목을 그냥 그 순서대로 하나씩 끝까지 꺼내서 반복한다.
그래서 리스트를 많이 쓴다.
자바스크립트에서는 반복문을 보통 리스트에서 리스트의 사이즈를 정의하고 꺼냈는데,
파이썬에서는 쿨하게 그냥 리스트에 있는것들을 하나 쓰는걸 반복문이다! 라고 정의해버림.
fruits = ['사과', '감', '배',
for p in fruits:
p(fruit)
이렇게하면, fruits 배열에 있는 내용 하나하나를 꺼내서 fruit에 넣은다음, 아래 print(fruit)를 실행함.
p는 뭐라고 써도 상관없고, 보통 p를 단수값, in 뒤에 배열은 복수값으로 많이 한다고 함.
for fruit in fruits 이런식.
개수세기가 있다면, 개수를 넣을 변수가 필요함. 그래서 보통 count 라고 for 전에 씀.
count = 0
for fruit in fruits:
내용쓰고 ㅁ지막에
count += 1 이런식으로 넣음.
이런 폼을 기억하자.
def count_fruits(name):
count = 0
for fruit in fruits:
if fruit == name:
count += 1
return count
여기에서, for를 count+=1 까지 계속 돌려서 count를 증가시키고, for문이 끝나면 (fruits배열의 끝까지 가면,) count를 return 하는것임.


파이썬 패키지와 라이브러리
누가 구현한 파이선의 함수, 모듈등을 모아놓은 것. 이러한 패키지를 모아놓은것이 라이브러리이다.
여기서는, 라이브러리를 사용하기 위해 어떤 패키지를 설치하는 것.
가상환경이란?
회사프로젝트에서 패키지a,b,c를 쓴다.
개인프로젝트에서는 패키지 b,c,d,e를 쓴다.
근데 회사에서 패키지b+를 쓰라고 함;;
그럼 개인프로젝트ㄱ가 난감해짐.
패키지는 다 깔아놓고, 회사프로젝트는 abc를 쓰고, 개인프로젝트는 bcde 를 쓰도록 해서, 프로젝트별 가상환경을 만드는 것.
정리하면, 가상환경은 같은 시스템에서 실행되는 다른 파이썬 응용 프로그램들의 동작에 영향을 주지 않기 위해 파이썬 배포 패키지들을 설치하거나 업그레이드하는 것을 가능하게 하는 격리된 실행환경임.
공식설명
https://docs.python.org/ko/3/glossary.html#term-virtual-environment
라이브러리를 여러개 까는건 문제없다.
이런 가상환경은 별거 없고 그냥 폴더이다. 아래 그림에서 venv 라는 디렉토리 (virtual environment)
사용하는 패키지들이 거기 들어간다고 생각하면 됨. 여기에서 패키지를 읽어오므로, 다른 프로젝트와 문제생길 일이 없음.

가상환경 설치하기
어떤 파이썬을 쓸 지 선택
confiture python interpreter -> add interpriter 하고 그냥 ok 하면, 파이참 왼쪽에 venv 디렉토리가 생김. 이게 가상 그건가봐.
venv는 우리눈에 보이지만, 안보이는거로 생각하면됨. 여기 밑에 파일 절대 만들지마라.
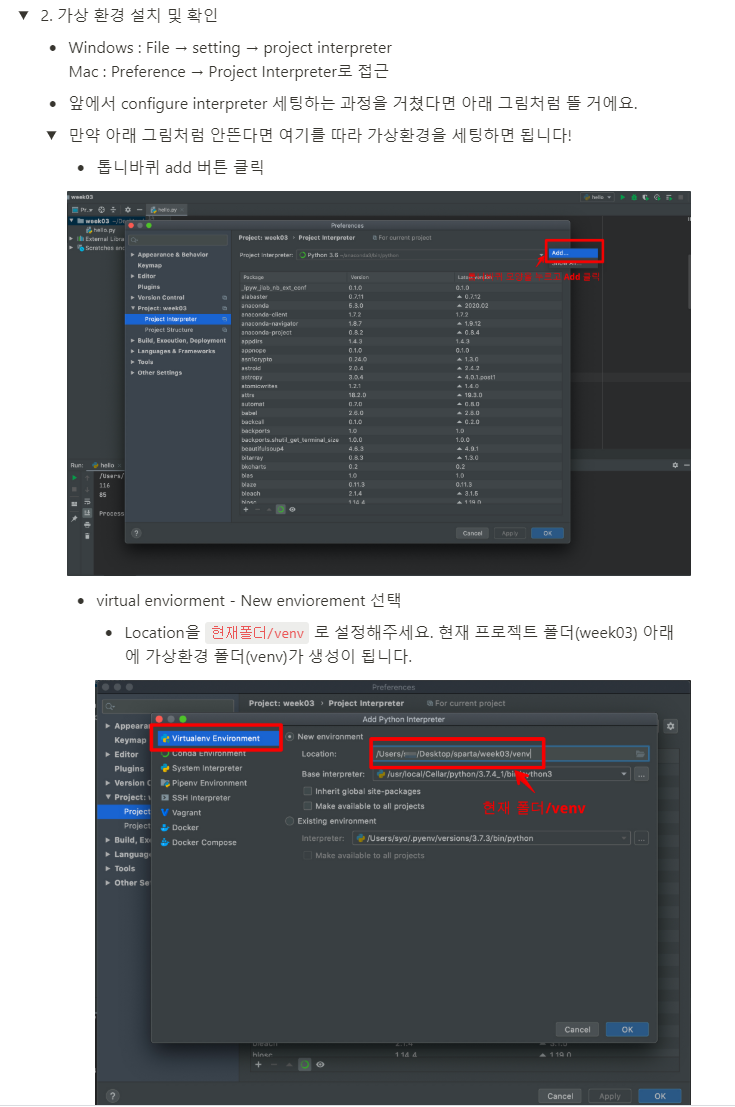
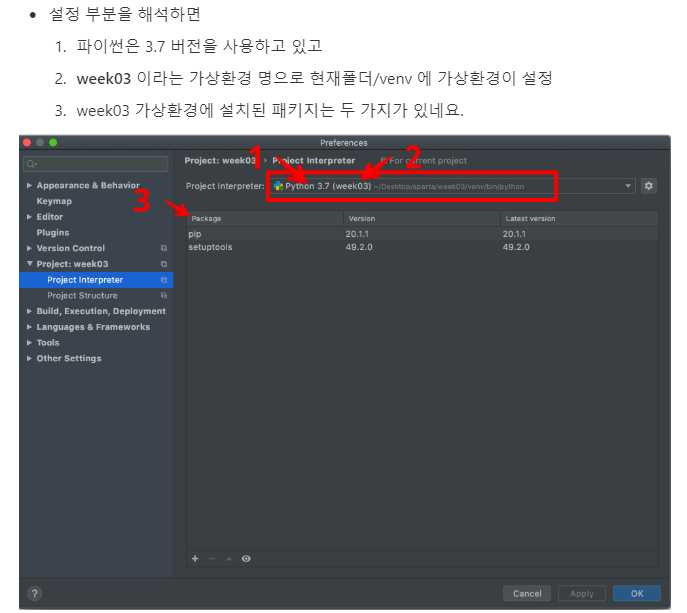
더 추가하여 자세한건 아래 내용 참고
https://dojang.io/mod/page/view.php?id=2470
pip 사용하여 패키지 설치하기
앱을 설치할 때 앱스토어를 가듯이 새로운 프로젝트의 라이브러리를 가상환경에 설치하려면 pip을 이용한다.
file -> setting -> project interpreter에 들어가서, 오른쪽 더하기 (아래에 있을수도 있음) 를 누름.
이런 패키지들은 패키지/라이브러리의 홈페이지 가면 사용법과 예제코드 들 있음. 아래에서 패키지검색할 때 사이트가 나옴.

그리고 여기 오른쪽 기어모양 누르면 가상 공간 관련하여 세팅할 수 있음.
라이브러리를 사용하는 기초 연습 : 서울시 openapi 사용하기
서울시 권역별 대기현황
api : http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99
딱 중구의 NO2 값만 가져오기
# requests 라이브러리 설치
import requests
# requests 를 사용해 요청(Request)하기
response_data = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99')
# 응답(response) 데이터인 json을 쉽게 접근할 수 있게 만들어 city_air 에 담고
city_air = response_data.json()
# 값을 출력
print(city_air['RealtimeCityAir']['row'][0]['NO2'])
requests는 명시된 경로의 데이터를 가져오는 것이며 거기 get()을 써서 가져옴.
이미구현되어있는 json() 이라는 함수를 사용한다. json함수는 받은 값을 json형태로 구현하는 것임.
json()으로 넘어온 데이터를 접근가능하게 .json()으로 바꿔준 것 뿐임 -> 온라인강사가 한 얘기. 서로 다르니깐 찾아바ㅗ야함.
json()을 안쓰면, 값이 안나온다.
여기서 json 함수와 get 함수는 requests를 임포트했기때문에 사용가능한것임.
이걸 두줄로 만들어버리면 아래처럼 된다.
import requests
print(requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99').json()['RealtimeCityAir']['row'][1]['NO2'])
다시정리
데이터를 가져올 때 다음과 같이 데이터 자체가 여기 딕셔너리부터 시작하는것임.
이 빨간게 request.get해서 받은 값이고 그걸 변수에 넣고 이제 ['RealtimeCityAir'] 부터 시작하는거

PM10 값이 20미만인 구만 출력하기
gu_infos = city_air['RealtimeCityAir']['row']
for gu_info in gu_infos:
print(gu_info['MSRSTE_NM'], gu_info['PM10'])
웹 스크래핑
스크래핑이란, 한국에선 크롤링이라고 하기도 하며, 웹페이지에서 우리가 원하는 부분의 데이터를 수집하는 것임.
크롤링 : 검색엔진이 웹사이트를 가져오는거
스크래핑 : 사이트에서 데이터 추출하는거
구글로 더 검색할때는 web scraping으로 검색해야 자세한 정보가 나옴.
스크래핑 할때마다 서버에 붙는게 아니다. 일단 html을 받고, (즉 접속하고,) 다운받아진 html에서 데이터를 추출하는것이다. 즉 받은 html은 우리꺼니까 서버 부하는 없다.
참고
[Web Scarping](https://en.wikipedia.org/wiki/Web_scraping)(wikipedia)
[Web Crawler](https://en.wikipedia.org/wiki/Web_crawler)(wikipedia)
[Web Scraping vs Web Crawling: What’s the Difference?](https://dzone.com/articles/web-scraping-vs-web-crawling-whats-the-difference)
관련 패키지 다운
beautifulsoup4 = html 코드를 쉽게 스크래핑해오기 위한 도구
requests 패키지 설치한것처럼 설치하자.
beautifulsoup4 가 bs4인듯함. 이 안에 여러가지 패키지가 있다.
bs4라고 해서 설치해도 됨. 같은거라고 한다.
import를 할 때, bs4를 전체를 임포트해도 되는데, 여기 스크래핑할 때 다 임포트할필요는 없다. 필요한게 BeautifulSoup이거든.
그래서 아래와 같이 from을 써서, bs4 에서 beautifulSoup만 임포트할 수 있다.
beautifulSoup만 임포트한다고 해서 from bs4를 빼면 당연히 안됨.
import requests
from bs4 import BeautifulSoup
네이버 영화 스크래핑하기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200716',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#############################
# (입맛에 맞게 코딩)
#############################
설명
requests 패키지 import 수행 : request.get 함수를 사용하기 위함
bs4 패키지에서 BeautifulSoup 패키지 import 수행 : BeautifulSoup 함수 사용하기 위함
text 함수 : 태그 안에 있는 글자 <a>안녕</a> 여기서 안녕을 가져온다.
requests.get 함수
이 함수는 명시한 경로의 html 통데이터를 다 가져온다. json이 아니고 그냥 raw 데이터를 가져와버린다. ajax콜을 수행하며 아주 쉽게 할 수 있다.
즉 2개의 값을 받는다. (더받을수도 있음. 여긴 일단 2개값만) html 데이터를 가져올 주소, 헤더정보를 넣어주며, 이 함수의 결과를 data 변수에 넣었다.
우리가 브라우저로 접속하는거랑, requests로 땡겨오는것은 조금 차이가 있다. 보통 헤더에서 차이가 나는데, 헤더를 넣는것은 우리가 마치 브라우저에서 엔터친것처럼 강제로 넣어준것임.
헤더 정보는 접속하는 클라이언트의 정보를 명시하는 것이며, headers 변수에 넣었고 그 변수를 requests.get 함수에 넣었다. 사실 이 헤더정보는 없어도 되고 있어도 된다. 하지만 있는게 좋다. 왜냐면 실제로 인터넷에는 자동 웹 스크래핑 봇이 엄청 많으며, 봇 때문에 어떤 서버는 헤더정보를 주지 않으면 봇이 접근한다고 생각해서 데이터를 가져가지 못하게 막는 경우가 있다. 그래서 헤더를 사용한다. 근데 봇도 헤더를 쓸 수 있다고 한다.. 뭐 어쩌라는건지 잘 모르겠다. 아래 내용도 참고할 것.
BeautifulSoup 함수
html 내용에 이 함수를 적용하여 검색하기 용이한 상태로 만들어준다. 즉 예쁘게 만들어준다. 일단 이 함수도 2개의 값을 받는데, 아까 네이버영화의 html 을 넣은 data 변수에 text 함수를 적용한 값과, 예쁘게 만드는 파싱 이라는 걸 수행하도록 어떤 파서를 쓸 지 명시한다. 결과는 soup 변수에 담긴다.
테스트로 soup 변수를 출력해보면, 다음과 같이 나온다. print(soup)

이렇게 태그가 예쁘게 나온다. 이제 원하는 값을 찾는 방법을 알아보자.
text함수와 json()함수 문의.
text 함수는 태그 안의 텍스트를 가져온다. 태그.text
원하는 값을 찾기 : 셀렉터
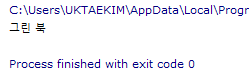
아까 네이버 영화에서, 그린 북 이라는 글자를 한번 찾아보자.
크롬에서 그린북 글자를 오른클릭하고, 검사 누른다음 표시된 html부분을 오른클릭하고 copy->copy selector를 선택한다.
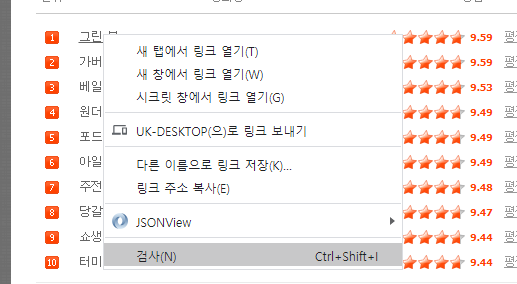

복사된 것을 붙여넣어보면 이런 결과가 나온다.
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a이 내용을 잘 보면, 맨 앞의 #old_content는 선택자이며, table, tbody, tr, td, div, a 등은 태그이다.
따라서 그린북이라는 내용이 있는 하나의 경로를 출력한 것이다. "위와 같은 순서를 통해 "그린북" 이라는 글자 위치가 있다." 뭐 이런 뜻.
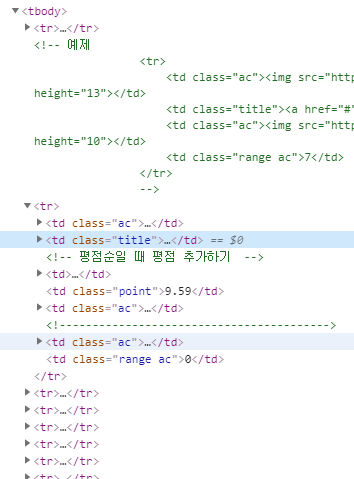
근데 왜 #old_content 부터일까? 실제로 해당 html 사이트의 최상위부터 그린북까지 쭉 태그를 가져와야 하지 않나? 라는 의문이 있을 수 있다. 다음 그림을 보자.
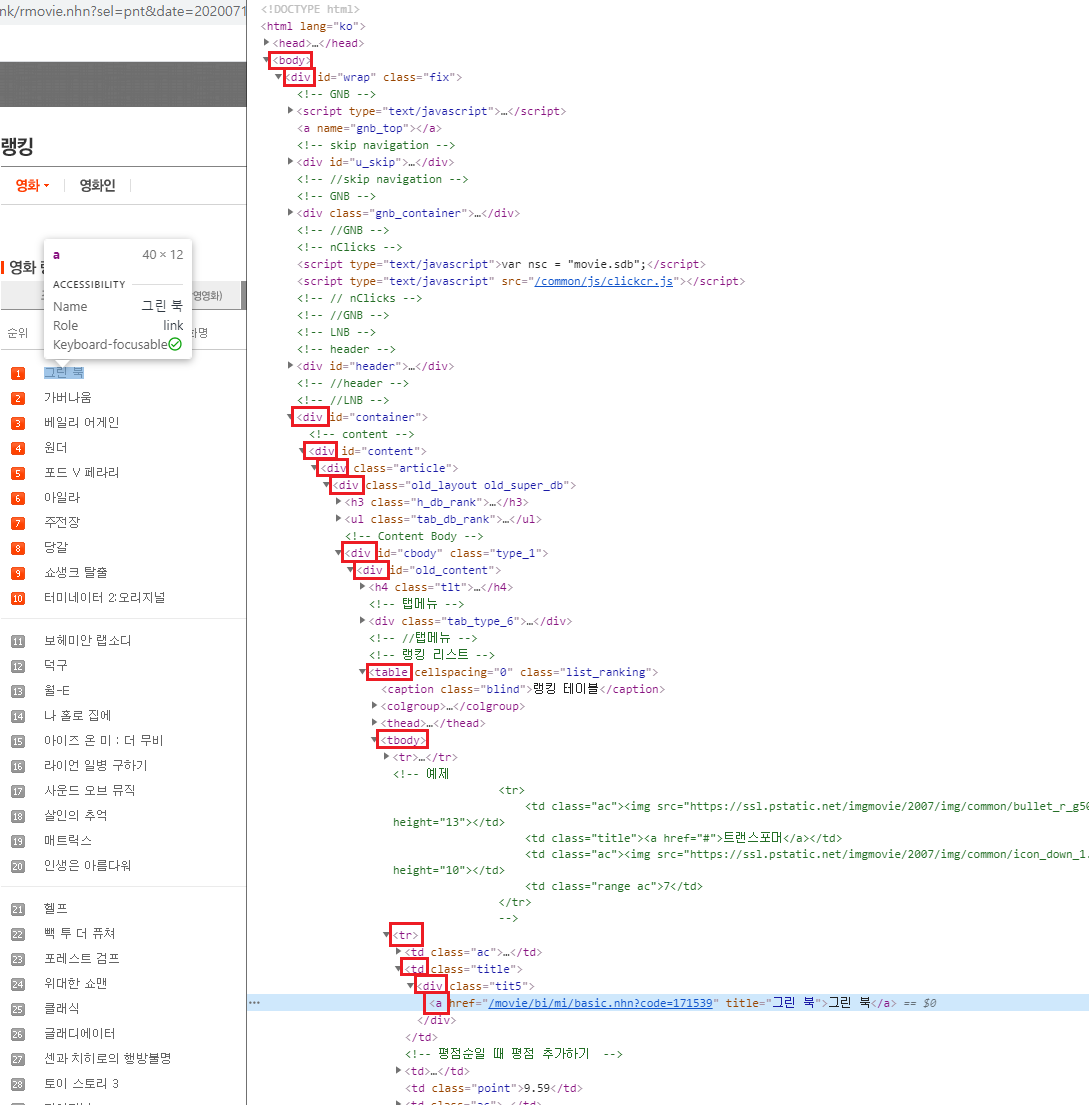
이 그림은 해당 사이트의 <body> 부분부터 그린 북 글자가 있는 <a> 태그까지의 모든 태그의 경로를 보여준다. 근데 실제로 copy selector를 했을 때는 중간에 <div>가 있는 id인 old_content 부터이다.
그림처럼 싹 다 나와야 할 것 같은데, 그렇지 않고 old_content 부터 나오는 이유는, 해당 html에 old_content라는 선택자(id)가 있고 딱 하나만 있어서 이값으로 바로 액세스할 수 있기 때문이다. 만약 old_content라는 값이 여러개 있었다면, 좀 더 상위로 가야 했을수도 있다. 어쨌든 하나의 경로로 인식해야 하기 때문.
아무튼 핵심은, 내가 가져오고 싶은 그린북이라는 글자가 있는 위치를 selector를 통해 다음과 같이 특정할 수 있다는 것이 중요하다.
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
추가로, 위와 같이 글씨 말고 다른 형식이라면? 예를들어 아까 순위에서 그린북이 1위였는데, 1이라는 글자? 또는 그림? 암튼 이걸 가져오고 싶다면?

여기서 보면 1이라는 부분이 img이다. 따라서 이미지라서 좀 어려운데, 보니 alt=01이 있다. 이건 개발자가 이미지가 깨지는 경우 숫자로라도 01이라고 나오게 하라는 것이다. 이 alt로 하면 되겠네!
이걸 copy selector로 복사해보니 아래와 같이 나온다.
#old_content > table > tbody > tr:nth-child(2) > td:nth-child(1) > imgimg 태그에 해당 01이 있고, img 태그의 속성 중 alt가 01인 것이다.
# 선택자를 사용하는 방법 (copy selector)
위 방식처럼 #아이디를 사용해서 선택자를 사용했다면, 그 외에 다른방법도 더 있다.
아래 방법은 구글링을 좀 해야할 것 같다. 볼드체는 해본것이며, 볼드 아닌것은 찾아보자.
일단 구글 검사에서 copy selector를 하는것은 동일하며, 태그, 클래스 등도 선택자로 사용할 수 있다는 거.
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
여기까지 확인할 줄 안다면 이제 코딩을 하기 위한 기본 준비가 된 것이다. 이제 어떻게 출력할지를 코딩하면 된다. 아래 예제를 해보자.
사전 함수 이해
변수.select_one 함수 : 태그 하나만 가져온다.
text 함수 : 태그가 감싸고 있는 글자를 가져온다.
select는 해당 태그를 모두 리스트로 가져옴.
beautifulsoup는 select랑, select_one만 잘 알면 된다.
예제 : 영화 순위 가져오기
아까 확인했던 영화 순위를 가져와보자.
구문
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200716',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movieRank=soup.select_one('#old_content>table>tbody>tr:nth-child(2)>td:nth-child(1)>img')
print(movieRank['alt'])설명
soup에 해당 영화 사이트 html이 들어가있고, soup에 select_one 라는 함수를 적용하고, 인자값으로 아까 확인했던 img 태그까지의 경로를 지정해주면, html 사이트에서 #old_content부터 시작해서 img를 찾아낼 수 있게 되고, 그 값을 movieRank 변수에 넣는다. 그 변수의 결과는 다음과 같다.

이렇게 딱 <img> 태그 전체가 나오는데, 이 값 중 alt에 있는 01을 최종적으로 가져와야 한다. 그래서 movieRank변수에 딕셔너리처럼['alt']라는 항목을 가리킬 수 있다. alt : 01 이런식의 딕셔너리라고 생각하면 된다. 이렇게 지정해서 01이라는 결과를 확인했다.
결과

여기서는 운이 좋게 01을 가져올수 있었다. 왜냐면 alt값에 개발자가 01로 했기 때문. 만약 alt 값이 없었다면, 어떻게 해야 할지 모르겠지만, src 항목의 이미지 경로를 받고 그 경로에 있는 01이라도 추출해야할지도 모른다.
예제 : 영화 제목 하나 가져오기
구문
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200716',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select_one('#old_content>table>tbody>tr:nth-child(2)>td.title>div>a')
print(movies.text)
설명
위와 동일한데, movies라는 변수로 가져오는 결과는 다음과 같다.

이 안에서 그린 북 이라는 글자를 가져오려면, 2가지 방법 title 속성에 있는 그린 북 을 가져오던지, 태그가 감싸고 있는 글자인 그린 북 을 가져올 수 있다. 속성에서 가져오는건 위에서 했으니, 태그가 감싸고 있는 걸 가져오는 방식인 text 함수를 사용해서 가져온다.
결과
예제 : 영화 제목을 싹 다 가져오기
import requests
from bs4 import BeautifulSoup
# URL을 읽어서 HTML를 받아오고,
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200716', headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
# a의 text를 찍어본다.
print(a_tag.text)
설명
저 그린북부터 맨 아래까지 순위 리스트를 다 가져오려면 셀렉터를 어떻게 지정해야 할까? 생각해보자. 이게 해당 사이트 html을 분석하는 것이다. 분석을 해서 패턴을 찾고, 패턴에 맞게 코딩을 짤 수 있는 것이다.
여기서는 보면, 1, 2, 3 번의 리스트들이 오른쪽에 1, 2, 3 의 <tr>..</tr> 과 매치된다. 이러한 <tr>..</tr>은 바로 상단인 <tbody> 아래에 있다. 그럼 우리는 <tr>..</tr>들만 다 추출을 하면 되지 않을까?
(실제로 그린북 이라는 글자를 가진 태그는 <a>태그인데, 그 글자를 가진 가장 높은 수준의 태그가 <tr>..</tr> 이라는 것이다. 만약 <tr>..</tr> 보다 더 상위를 가져오면, 그린북 글자가 있는 <a>태그 뿐만 아니라 가버나움, 베일리 어게인 등등 싹다 가져오게 되기 때문에 그 상위를 하면 안되고, 딱 <tr>..</tr>을 해야 한다는 것이다)

그럼 이제 아래처럼 tbody 아래에 나열된 <tr>...</tr> 들을 하나하나 오른클릭해서 copy -> copy selector 해보면, 맨 첫번째 tr 부터 다음과 같이 나온다.
#old_content > table > tbody > tr:nth-child(1)
#old_content > table > tbody > tr:nth-child(2)
#old_content > table > tbody > tr:nth-child(3)tr:nth-child(1) 값에서 1은 해당 열의 첫번째를 말한다. 그림에서 숫자 1,2,3 이 여기 나온 tr:nth-child(1),(2),(3)과 동일하다. tr을 다 가져올것이니 tr 옆에 붙은 nth-child(1) 이런건 무시한다. 딱 하나만 가져올거면 무시하면 안되겠지만.
그럼 다음과 같이 하면, movies 변수에 tr값들을 싹 다 가져오게 된다.
movies = soup.select('#old_content > table > tbody > tr')이 movies 변수는 리스트이며, 각각에 tr들을 저장한다. 그래서 반복문으로 가져올 수 있게 된다.
movies 변수 안에 있는 내용을 보면 다음과 같다.
각 <tr> .. </tr> 하위내용까지 <tr> .. </tr>들을 싹 다 가져온다.

우리의 목적은 그린 북, 가버나움 같은 글자를 가져오고 싶은것이다. 이러한 글자를 가진 태그는 <a> 태그이다. 그래서이제 for 문을 돌려서 다 추출해야 되는데, 그 태그의 selector는 다음과 같다.
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
근데 아래처럼 movies 변수는 이미 tr까지의 값을 가지고 있으므로, tr 바로 아랫단인 td.title 부터 for문을 돌리면 된다.
그래서 아래 구문에서 for문으로 a_tag라는 변수를 select_one 함수로 (td.title > div > a) 1개를 추출하도록 구문을 넣는 것이다.
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
# a의 text를 찍어본다.
print(a_tag.text)movie는 for문에서 사용할 새 변수이며, <tr>..</tr> 하나하나를 movie 변수에 넣는다. movies 함수에는 <tr>..</tr>이 엄청 많기 때문이다. 그중에서 <tr>하나를 꺼내서, select_one함수를 돌려서 'td.title > div > a' 를 찾아 나온 결과를 a_tag에 저장하는 것이다. 결과적으로, a_tag 변수에는 다음과 같은 값이 들어간다.
movie는 새 변수이며, movies, 즉 tr묶음에서 <a>
<a href="/movie/bi/mi/basic.nhn?code=171539" title="그린 북">그린 북</a> 이 값에 text함수를 씌워 print를 하면 "그린 북" 이것만 나온다. 이걸 for로 돌려서 쭉 나오게 하는 것이다.
추가로, 여기 if가 있는데, 왜 있냐면, 실제로 <a> 태그를 찾다보면, 이런식으로 나온다. none이 나온다.
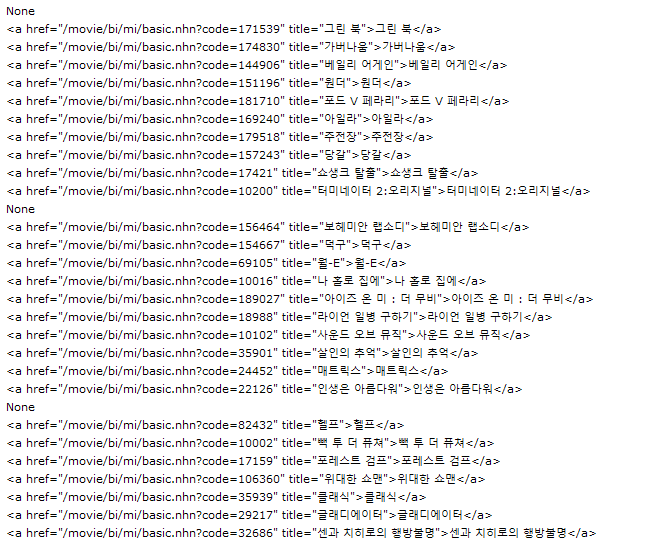
이 none 값은, 아래와 같은 가로줄이다;; 이 가로줄도 빼야하므로 if 문을 쓰게 된다.

참고로 가로술의 선택자는 다음과 같다.
#old_content > table > tbody > tr:nth-child(12) > td저 위에 none 값은, 위에 for문을 돌렸을 때 <tr>..</tr>에 <a>태그가 없는 부분이라 none이라고 뜨는 것임. none이라는 값은 원래 있는 글자가 아니라 파이썬 키워드이다. 값이 없을 때? 뜨는 듯하다. 아래 그림처럼, <tr>..</tr>에 <a>태그가 없는 가로줄이다.

그래서 if문으로 none이 나오면 이건 출력하지 않도록 하기 위해, 다음과 같이 if문을 넣는다.
if a_tag is not None:
# a의 text를 찍어본다.
print(a_tag.text)즉, a_tag (<a>태그가 모아져있는) 변수가 None 이 아니면, print를 한다는 것이다. 그리고 text 함수를 적용하여 딱 이름만 나오게 된다. 와 힘들다.
참고로, if title != None: 을 해야하지만 ,None 쓸 때 한정으로 파이썬에서는 title is not None: 을 쓰길 권고함.
실습 : 네이버 영화에서 순위, 제목, 별점을 얻어오기
구문
import requests
from bs4 import BeautifulSoup
# URL을 읽어서 HTML를 받아오고,
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200716', headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
rank = movie.select_one('td:nth-child(1) > img')['alt'] # img 태그의 alt 속성값을 가져오기
title = a_tag.text # a 태그 사이의 텍스트를 가져오기
star = movie.select_one('td.point').text # td 태그 사이의 텍스트를 가져오기
print(rank, title, star)
분석
for 문을 돌리기 직전, movies 선언하는곳까지는 이전 예시와 동일하다. 즉, 우리가 찾으려는 순위, 제목 평점 모두 다 가지고 있는 <tr>태그까지 진입한 상태이다.
이제 3개의 값을 확인해야 하므로, 다음과 같이 3개의 값을 크롬 - 검사에서 copy selector로 확인할 수 있다.
순위 : #old_content > table > tbody > tr:nth-child(2) > td:nth-child(1) > img
제목 : #old_content > table > tbody > tr:nth-child(2) > td.title > div > a
평점 : #old_content > table > tbody > tr:nth-child(2) > td.point
이제 반복문을 살펴보자
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
rank = movie.select_one('td:nth-child(1) > img')['alt'] # img 태그의 alt 속성값을 가져오기
title = a_tag.text # a 태그 사이의 텍스트를 가져오기
star = movie.select_one('td.point').text # td 태그 사이의 텍스트를 가져오기
print(rank, title, star)<tr> 부터 시작하여, 일단 a를 먼저 찾아서 a_tag에 넣는다.
그리고 a_tag가 not none이라면, 즉 html값이 있는 경우 아래를 수행한다.
rank 변수에 순위인 img값에서 alt의 숫자값을 넣고, title변수에는 a_tag를 text로 가져오고(제목), star는 td.point 그대로 참고해서 텍스트를 가져오게 한다.
그리고 print로 3개의 변수를 가져온다.
결과

스크래핑 팁
화면을 분ㅂ석해야함. 어떤 식으로 계층이 되어있는지.
원하는 값의 부모들을 쭉쭉 올라가서 반복문으로 할 수 있는지
중간중간에 값들이 잘 나오는지 체크
사이트마다 코딩하는 내용이 다르니, 해당 사이트의 스크래핑 규칙을 찾아야 됨. 이게 오래걸리고 힘듬.
이 규칙을 찾게되면, 원하는 데이터를 찾을 수 있고 그걸 파이썬으로 만들면 되는거.
내가 원하는 데이터가 어딨는지 계속 개발자도구를 보면서 해야 함.
연습문제1 : 위 실습에서 날짜만 다른 날의 순위를 동일하게 구해보자.
아래처럼 2020년 7월 16일 순위에서, 2018년 3월 27일 순위를 구해보자.

사이트 내부의 html 규칙을 찾는 것 뿐만 아니라, 각 사이트 주소 를 마치 api라 고생각해서, 이런식으로 날짜만 바꿔서 할 수 있다. 즉 아래처럼 맨 뒤 date값만 바꿔준다.
https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20180327
여기서 20180327을 다른숫자로 바꾸면 바로 그날짜의 순위를 크롤링 할 수 있다는 거. 그럼 날짜를 한번에 여러개 할 수도 있겠지.
예를들어 웹페이지에서 날짜를 받고, 그 날짜로 크롤링하는.. 그런
연습문제2 : 네이버 한국프로야구 순위 가져오기
https://sports.news.naver.com/kbaseball/record/index.nhn?category=kbo
구문
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://sports.news.naver.com/kbaseball/record/index.nhn?category=kbo&year=2020', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
parse_text = soup.select('#regularTeamRecordList_table > tr')
for parse_text_data in parse_text:
ranking = parse_text_data.select_one('th > strong').text
team_name = parse_text_data.select_one('td > div > span').text
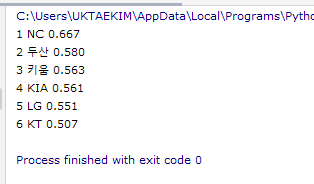
print(ranking, team_name)팁
아래처럼 랭킹의 경로를 정확히 인지하고, 팀 이름 경로도 정확하게 인지해둔 상태에서 for문을 작성하면 좋다.
랭킹 경로 = soup.select_one('#regularTeamRecordList_table > tr:nth-child(1) > th > strong').text
팀이름 경로 = soup.select_one('#regularTeamRecordList_table > tr:nth-child(1) > td > div > span').text
결과

이런식으로 나와야 한다.
연습문제3 : 연습문제2번의 결과에서 승률이 0.5 이상인 팀만 출력하기
코드
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://sports.news.naver.com/kbaseball/record/index.nhn?category=kbo&year=2020', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# rankings = soup.select_one('#regularTeamRecordList_table > tr:nth-child(1) > th > strong').text
# team_name = soup.select_one('#regularTeamRecordList_table > tr:nth-child(1) > td > div > span').text
# win_rate = soup.select_one('#regularTeamRecordList_table > tr:nth-child(1) > td:nth-child(7) > strong').text
parse_text = soup.select('#regularTeamRecordList_table > tr')
for parse_text_data in parse_text:
ranking = parse_text_data.select_one('th > strong').text
team_name = parse_text_data.select_one('td > div > span').text
win_rate = parse_text_data.select_one('td:nth-child(7) > strong').text
if float(win_rate) > 0.5:
print(ranking, team_name, win_rate)
팁
if 문 수행 시, win_rate는 글자형태이기 때문에 0.5랑 비교할 수 없어서 에러가 난다. 따라서 float 함수로 win_rate를 실수형으로 바꿔서 0.5랑 비교할 수 있게 하면 된다.
결과
몽고디비 실행하기
설치는 위에서 한 대로 하면 되고, 윈도우버전은 관리자권한으로 cmd에서 mongod를 실행한다.

실행 후 브라우저에서 localhost:27017 로 접속했을 때 아래와 같이 나온다면 완료

몽고디비의 디폴트 포트는 27017 이다.
robo3t 실행하기
robo3t는 db에 직접 콘솔로 명령을 보는게 아닌, gui로 쉽게 보기 위한 프로그램이다.
공식적으로 몽고디비는 compass를 제공한다. 근데 robo3t가 많이 쓰이는 듯 하다.
https://docs.ncloud.com/ko/database/database-10-5.html 혹시 robo3t 말고 compass 쓰고싶으면 여기참고
실행하면, 뭐 동의하라고 하고 개인정보 넣는데 그대로 진행하면 됨.
아래처럼 창 뜨면 붉은색 표시 create 선택

address를 로컬호스트로 하는 이유는 내 노트북에 몽고디비가 설치되어 있기 때문.
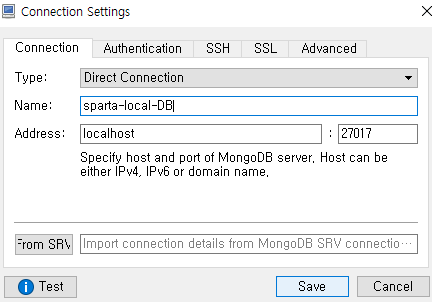
몽고디비와 개발하는 머신이 같은 경우 이렇게 localhost를 쓴다. name과 포트도 잘 써준다.
connect를 누르면 접속이 된다.

이렇게 뜨면 접속 완료

# 참고 : 데이터베이스의 종류
https://siyoon210.tistory.com/130
관계형 데이터베이스
관계형 데이터베이스는 정해진 규칙대로 넣어야만 제대로 데이터가 들어가고, 규칙을 지키지 않으면 데이터를 넣을 수 없음. 그래서 일관성과 무결성이 매우증요하고, 강함.
행/열의 생김새가 정해져있다. 정해진 규칙대로, 즉 정형화되어있다. 예를들어, 이름을 넣으려면 이름 행이 있어야 한다. 아니면 넣을 수 없음.
데이터 50만 개가 적재된 상태에서, 갑자기 중간에 열을 하나 더하기는 상대적으로 어려울 것입니다.
형식은 (데이터베이스 - 테이블 - 데이터들)
ex) postgreSQL(포스트그래 에스큐엘(시퀼)), MySQL(마이 에스큐엘(시퀼)) 등
NoSQL
no! 아니고 not only 라는 뜻임.
딕셔너리 형태로 데이터를 저장한다. 같은 값을 가진 데이터도 자유롭게 저장 가능.
장점은 자유롭고, 단점은 잘못 넣으면 무결성이 깨질 수 있음. 컨트롤이 안됨. 근데 무결성을 꼭 할 필요 없을 때 많이 사용.
형식은 (데이터베이스 - 컬렉션 - 데이터들)
파이썬과 mongodb 연결하기
파이썬에서 pymongo라는 라이브러리가 있어야 아주 쉽게 파이썬에서 몽고디비를 제어할 수 있다.
사전작업
pip으로 pymongo 설치
구문
from pymongo import MongoClient
client = MongoClient('ukdisk.asuscomm.com', 32768)
db = client.week3_sparta
설명
pymongo 패키지로부터 MongoClient를 임포트한다.
MongoClient함수는 2개의 인수를 받는다. 첫번째는 mongodb 서버 주소, 두번째는 mongodb의 포트
MongoClient함수의 결과를 client 변수에 넣고, week3_sparta 라는 컬렉션을 생성한다. 만약 이미 있는 db라면 생성하지 않고 그대로 사용한다. 그리고 db라는 변수에 결과를 넣는다.
mongodb에서 데이터 삽입하기
위에 구문 형식은 그대로 가져가며, db, client 변수를 설정에 따라 변경한다.
db명령(insert, find, delete, update 등)은 변수에 넣지 않고 작동해도 되며, 여러가지 로직을 수행하기 위해 변수에 들어간다.
구문
# db 연결 및 생성
from pymongo import MongoClient
client =MongoClient('ukdisk.asuscomm.com', 32768)
db = client.week3_sparta
## 데이터 생성하기
db.wow_named.insert_one({'name': '제이나 프라우드무어', 'race': 'human', 'level': 96})
db.wow_named.insert_one({'name': '리치왕', 'race': 'undead', 'level': 270})
db.wow_named.insert_one({'name': '가로쉬 헬스크림', 'race': 'orc', 'level': 99})
db.wow_named.insert_one({'name': '므우루', 'race': 'naaru', 'level': 142})
db.wow_named.insert_one({'name': '요그사론', 'race': 'old-gods', 'level': 299})
db.wow_named.insert_one({'name': '알렉스트라자', 'race': 'dragon', 'level': 273})
#이런식으로 변수를 사용할수도 있다.
character_wow1 = {'name': '티란데 위스퍼윈드', 'race': 'nightelf', 'level': 100}
db.wow_named.insert(chracter_wow1)
설명
db.wow_named.insert_one(내용)
붉은색 : 위에서 정의한 데이터베이스를 참고한다. 즉 week3_sparta라는 데이터베이스를 사용
파란색 : 컬렉션. 데이터베이스의 하위 단위이이다. wow_named라는 컬렉션을 생성한다. 원래 있으면 그대로 사용함.
녹색 : 삽입 명령. 해당 week3_sparta라는 데이터베이스의 wow_named라는 컬렉션에 데이터를 삽입한다.
주황색 : 녹색에 대한 조건 및 내용
결과

# 참고 : _id란?
실제로 유저가 넣은 값이 아니고, 각각 열들을 구분하기 위한 식별자로써 저장된다.
mongodb에서 데이터 읽기
find() 함수는 모든 내용을 찾는다. 찾은 내용을 리스트로 받아야 하므로 list() 함수도 함께 사용한다.
find_one() 함수는 하나만 찾는다. 처음에 찾은 것 하나만 나온다.
find와 find_one 모두 인자로 검색할 조건을 명시한다. 해당 조건에 맞는 값만 가져온다. 값을 명시하지 않으면 조건이 없으므로 그대로 모두 찾는다.
데이터 읽는것이 가장 공부할 게 많고 까다롭다.
출력 결과에서, 길게 나오는건 리스트화된거고, for등으로 보기좋게 출력된것은 다르게 나온것임.
기본 방식
구문
from pymongo import MongoClient
client =MongoClient('ukdisk.asuscomm.com', 32768)
db = client.week3_sparta
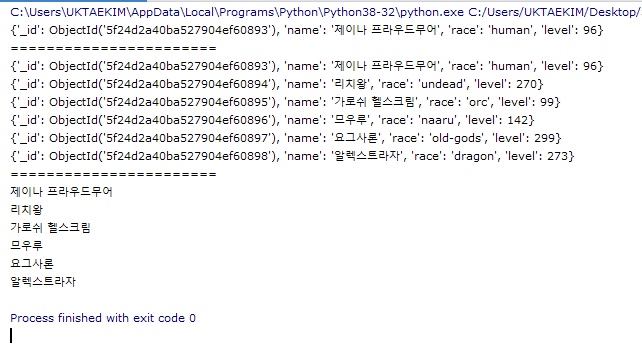
nameds = list(db.wow_named.find({}))
print(nameds[0])
print('=======================')
for named in nameds:
print(named)
print('=======================')
for named in nameds:
print(named['name'])
결과
조건에 맞춰서 가져오기
현재 데이터

구문
from pymongo import MongoClient
client =MongoClient('ukdisk.asuscomm.com', 32768)
db = client.week3_sparta
# find는 전체를 찾는다. 거기에 level이 96인 캐릭터를 보여준다.
named = list(db.wow_named.find({'level': 96}))
for p in named:
print(p)
print('=======================')
# find_one 은 가장 먼저 찾은 하나만 보여준다.
selectOne = db.wow_named.find_one({'level': 299})
print(selectOne)
print('=======================')
# find, find_one은 2개의 중괄호를 인수로 가지며, 첫번째 중괄호는 검색조건, 2번째 중괄호는 제외조건? 을 넣는것으로 보임. 중괄호를 계속 추가하는게 아니다.
# for문으로 돌리면, 변수에 list()함수를 적용하지 않아도 잘 작동한다.
except96 = db.wow_named.find({'level': 96}, {'_id': False, 'level': False})
# db.wow_named.find({}, {'_id': 0}))이런식으로도 사용할 수 있음.
for e in except96:
print(e)
결과

mongodb에서 데이터 업데이트
update_one : 처음에 만나는거 하나만 바꾸고 끝
update_many : 조건에 맞는 모든걸 다 바꿈, 인수로 2개의 중괄호를 받는데, 첫번째 중괄호는 검색 조건, 두번째 중괄호는 변경할 딕셔너리값이다.
업데이트문은 꽤 복잡하다. 보통 복붙으로 많이 사용한다.
업데이트 할 때 many는 비교적 많이 쓰지 않는다. 한번에 많이 하다가 잘못되면 위험하기 때문ㅇ.
구문
from pymongo import MongoClient
client =MongoClient('ukdisk.asuscomm.com', 32768)
db = client.week3_sparta
updateLevel = db.wow_named.update_many({'level': 96}, {'$set': {'level': 100}})
checkLevel1 = db.wow_named.find({'level': 100})
for level in checkLevel1:
print(level)
#레벨 96인 사람들을 모두 100으로 변경하고, 출력
updateRace = db.wow_named.update_one({'race': 'undead'}, {'$set': {'race': 'scorge'}})
checkRace = db.wow_named.find_one({'race': 'scorge'})
print(checkRace)
## 언데드를 스컬지로 바꾸고 스컬지를 출력
mongodb에서 데이터 삭제하기
실제 개발할 때에는, 데이터를 삭제하면 복구가 어렵기 때문에 '삭제' 기능이라도 실제 DB 에서는 데이터 자체를 삭제하는 것보다 '사용하지 않음' 으로 처리해두는 경우가 많다.
delete_one : 하나만 지움
delete_many : 모두 지움
구문
from pymongo import MongoClient
client =MongoClient('ukdisk.asuscomm.com', 32768)
db = client.week3_sparta
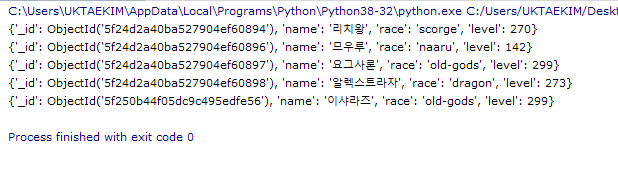
# 레벨 99인 캐릭터 하나만 지움
db.wow_named.delete_one({'level': 99})
# 레벨 100인 캐릭터 모두 다 지움
db.wow_named.delete_many({'level': 100})
levelCheck = db.wow_named.find({})
for e in levelCheck:
print(e)
결과
# 참고 : 몽고디비 뷰 형식 변경하기
트리 뷰

테이블 뷰
코드 뷰

실습1 : 크롤링한 데이터를 몽고디비에 넣기
import requests
from bs4 import BeautifulSoup
#DATABASE 사용 설정#####################
from pymongo import MongoClient
client = MongoClient('ukdisk.asuscomm.com', 32768)
db = client.week3_sparta
########################################
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200716', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
rank = movie.select_one('td:nth-child(1) > img')['alt']
title = a_tag.text
star = movie.select_one('td.point').text
#DATABASE에 삽입 #################################
doc = {
'rank': rank,
'title': title,
'star': star
}
db.movies.insert_one(doc)
##################################################설명
크롤링으로 RANK, TITLE, START 3개의 값을 가져오며 doc 변수에 {'rank': '변수'} 형식으로 데이터베이스에 값을 삽입한다.
결과
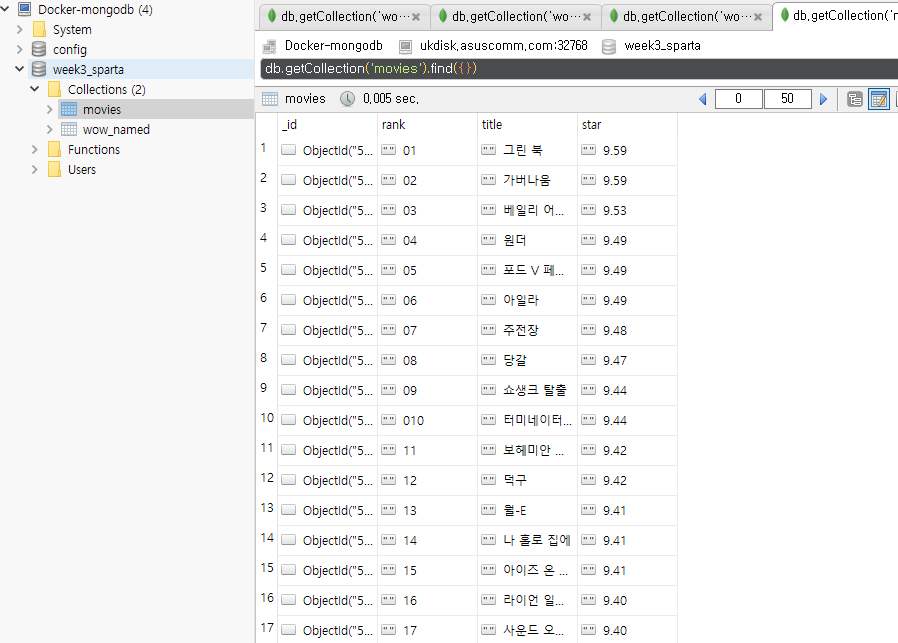
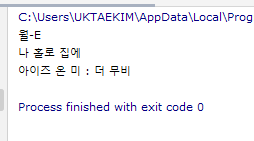
실습2 : 넣은 데이터에 데이터베이스 명령 사용해보기
월-E의 평점과 같은 평점의 영화 제목들을 가져오기
코드
from pymongo import MongoClient
client = MongoClient('ukdisk.asuscomm.com', 32768)
db = client.week3_sparta
walle = db.movies.find_one({'title': '월-E'})['star']
sameStar = db.movies.find({'star': walle})
for s in sameStar:
print(s['title'])결과
'월-E'의 평점과 같은 평점의 영화 제목들의 평점을 0으로 만들기
코드
from pymongo import MongoClient
client = MongoClient('ukdisk.asuscomm.com', 32768)
db = client.week3_sparta
walle = db.movies.find_one({'title': '월-E'})['star']
db.movies.update_many({'star': walle}, {'$set': {'star': 0}})
결과

git , github 사용하기
git이란?
작업 기록을 남기고 이력을 추적해 코드를 손쉽게 관리하도록 도와준다. 코드의 수정전, 수정후를 비교하고 최종적으로 fix하는 식이다. 버전관리도 매우 간편하다. 깃허브 데스크톱이라는 프로그램은, gui로 git을 쓸 수 있게 해주는 프로그램이다.
유용성
변경작업 후 문제가 발생했을 때 원본과 비교
여러사람/컴퓨터에서 코드 작업을 동시에 할 때 변경 내역을 정리하는 것
버전이 여러개면 쓰다가 다른버전으로 변경하는 등을 자유롭게 할 수 있다.
예시 (이력을 추적하고 비교하기)

github란?
작업 기록과 파일을 저장하는 git 원격 저장소(클라우드)를 지원하는 사이트.
또한 최근 트렌드인 오픈소스 찾기, 프로젝트 issue 관리처럼 다양한 부가기능을 제공한다.
또 다른 비슷한 곳으로 gitlab, bitbucket 등이 있다.
용어정리
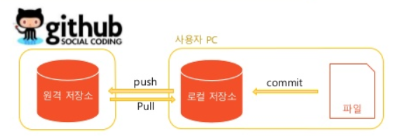
commit
내 로컬 저장소에 작업을 하고, (예를들어 파이참에서 수정을 하고, git desktop에 들어가서) 변경사항을 반영함. 즉 파이참(외에 뭐든,노트패드도 뭐도 다) 등의 내가 쓰는 프로그램에서 수정을 하면, git desktop에서 감지한다. 그걸 commit로 변경사항을 "이게 맛다" 고 갱신하는거.

push
원격 저장소에 작업 내역, 즉 commit 된 것 을 클라우드에 업로드하는 것.
보통 여러 사용자가 올린 것이라도 작업 내역에 겹치는게 없으면 자동으로 합쳐준다.
여러 사용자가 하나의 파일의 동일한 부분을 고쳤다면, 어떤 부분을 어떻게 반영해야할까요? Git이 충돌(conflict)났다고 알려주고 사용자에게 직접 수정하라고 알려줍니다.
push를 했으면, 이제 다른 사람들이 다 볼 수 있다. (오픈된경우)
pull
원격 저장소 작업 내역을 내 로컬 저장소로 가져오는 것
내가 내 컴에서 개발하고 있는것은 이거랑은 상관이 없고, 다른 사람의 작업내역을 가져오거나 다른 컴퓨터에서 작업한 내용을 가져오는 것.
예를 들어, 내가 코드 수정하고 commit 후 push 한 후, 다른사람이 그걸 수정하고 commit 하고 push하면, 내가 그걸 pull 해서 이어서 작업하는 식.

이런 일련의 기록들이 모두 남는다.
github 데스크탑 사용하기
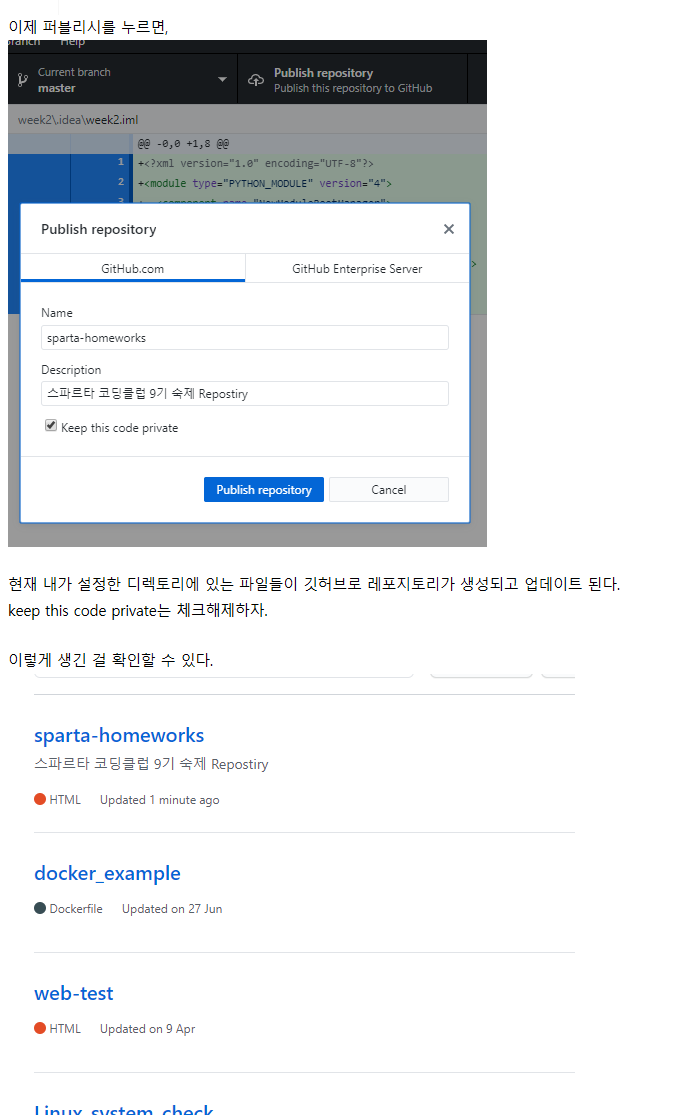
내 자료들을 원하는 경로에 저장해둔다.
깃허브 데스크탑을 실행하고, 아래 화면에서 add a repository to github desktop to start collaborating을 선택

내가 넣어놓은 자료들이 있는 경로를 지정해준다.

아래처럼 뜨면, create a repository 선택하면 됨. 여러가지 내용이있는데 잘 모르겠다. 그냥 create repository 하자. 그러면 조금 오래 걸린다. 기다리자.

다 되면 이런식으로 화면이 나온다.
이것은 기존에 존재하던 내 homeworks 폴더를 git이 tracking 할 수 있게 설정되었다고 생각하면 된다. 이제 아래 디렉토리처럼 이런 파일이 생긴다.
실제로 내 파일들을 수정하면, 깃허브 데스크탑에서 변동사항을 볼 수 있다.
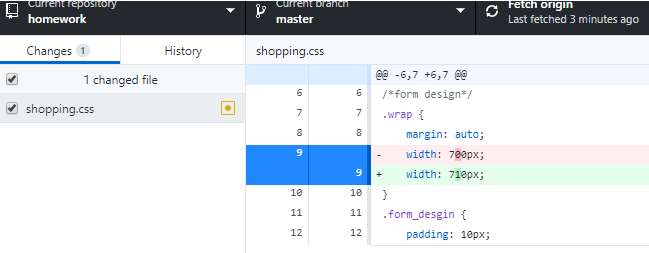
또 변동한 것을 원복하면 다시 변동사항이 여기서 사라진다.
그리고 이 변동사항을 git에서 commit 하면 되고, 코멘트를 달고 commit 하면, 적용되고 파일들이 모두 없어짐. 이러면 로컬 저장소에서는 이제 확정된것임. 수정이.
이제 깃허브 사이트로 가보자

여기 update shopping.css 를 누르면,
요런식으로 나옴

변동된 것을 확인할 수 있다.
슬랙과 github 연동하기
슬랙은 다양한 어플이 있고, 깃허브기능이 있는 어플이 있다. 원리는 슬랙에 있는 github 봇을 사용하는 것임.
참고 : slack 메시지 창에 /github라고 쓰고 엔터치면 더 많은 github 슬랙 앱의 명령어를 볼 수 있다. 더 이상 알람이 오지 않도록 unsubscribe도 가능
슬랙 채널에서,, 그러니까 대화방에서 다음과 같이 입력해보자.
/github subscribe uktaekim/sparta-homeworks (계정명/레포지토리명)
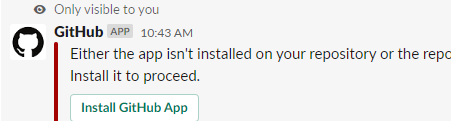
이렇게 뜸. install github app을 누른다.
쭉 진행한다

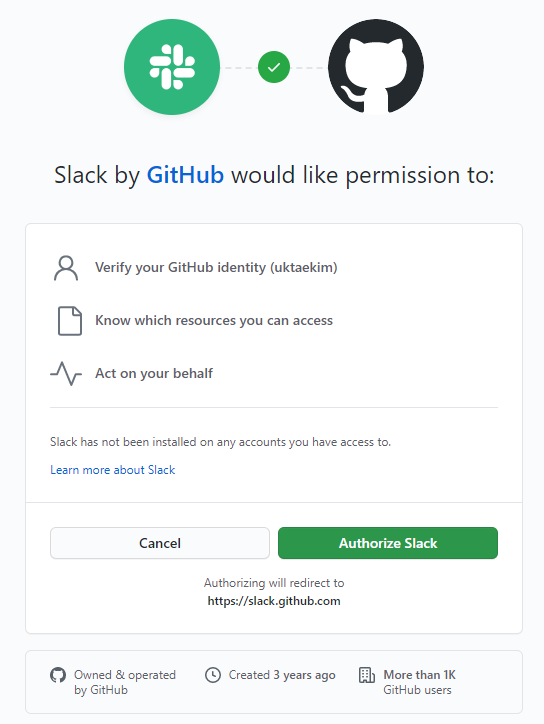
모든 레포지토리를 공개하지 말고 원하는 것만 공개한다.

이렇게 뜨면 완료이다.
슬랙에서도 이러한 메시지가 나온다.

이제 깃허브에서 push 하면 이런식으로 뜬다.
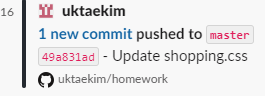
숙제 ===
지니뮤직에서 인기순위 크롤링하고, 몽고디비에 입력하기
## 패키지 및 라이브러리 등록
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
## 데이터베이스 연결 정보
DB_HOST = '내사이트:32768'
DB_ID = 'root'
DB_PW = '883030aa!'
client = MongoClient('mongodb://%s:%s@%s' % (DB_ID, DB_PW, DB_HOST))
db = client.sparta
## html 크롤링
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
music_data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&rtm=N&ymd=20200713', headers=headers)
soupped_data = BeautifulSoup(music_data.text, 'html.parser')
music_lists = soupped_data.select('#body-content > div.newest-list > div > table > tbody > tr')
# 데이터 추출
for music_list in music_lists:
ranking = music_list.select_one('td.number').text[0:2].strip() ## 텍스트 추출 후 앞 2글자만 따온 후 거기에 strip() 함수를 적용
title = music_list.select_one('td.info > a.title.ellipsis').text.strip()
artist = music_list.select_one('td.info > a.artist.ellipsis').text.strip()
print(ranking, "|", title, "|", artist)
## DATABASE에 입력
db.week3_homework.insert_one({'rank': ranking, 'title': title, 'artist': artist})
결과

'SCC 9기' 카테고리의 다른 글
| [SCC 9기] 5주차 (0) | 2020.08.11 |
|---|---|
| [SCC 9기] 4주차 (0) | 2020.08.11 |
| [SPC 9기] 2주차 (0) | 2020.07.24 |
| [SPC 9기] 1주차 - 프론트엔드 (0) | 2020.07.16 |
| [SCC 9기] 개발자를 위한 팁 (0) | 2020.07.16 |