개방 실습: 성능 모니터링 툴 선택
성능 체크리스트
이 랩에서는 다양한 시스템 모니터링 툴을 사용하여 시스템 동작을 관찰합니다.
결과
다음을 수행할 수 있습니다.
- sysstat 패키지를 설치하고 시스템 활동 보고서를 생성하도록 구성합니다.
- Performance Co-Pilot을 설치하고 원시 데이터를 캡처하여 로컬 및 원격 시스템을 모니터링하도록 구성합니다.
- Performance Co-Pilot 차트를 사용하여 특정 시스템 아카이브 로그의 성능 지표를 표시합니다.
workstation VM에 student 사용자로 로그인합니다. 이때 암호는 student를 사용합니다.
workstation에서 lab perftools-review start 명령을 실행합니다. 이 명령은 네트워크에 있는 serverb 호스트에 연결할 수 있는지 여부를 확인하고 이 랩 연습의 호스트에 필수 파일을 복사합니다.
[student@workstation ~]$lab perftools-review startworkstationVM에서 Performance Co-Pilot 차트를 실행하여 로컬 및 원격 성능 지표를 모니터링하도록 시스템을 구성합니다.pcp-gui패키지를 설치합니다.[student@workstation ~]$sudo yum install pcp-guiPerformance Co-Pilot 지표 수집기 데몬을 시작하고 활성화합니다.
[student@workstation ~]$sudo systemctl enable --now pmcd
workstation에서 ssh를 사용하여serverb에student사용자로 로그인합니다. 권한을root사용자 계정으로 에스컬레이션합니다.student사용자로serverb에 로그인합니다.[student@workstation ~]$ssh student@serverb [student@serverb ~]$sudo -i [root@serverb ~]#
serverb에서sysstat-collect.timer및sysstat-collect.service라는 systemd 장치를 제공하는 패키지를 설치합니다. 1분마다 한 번씩 시스템 활동 데이터를 수집하도록 타이머 장치 구성 파일을 수정합니다.sysstat 패키지를 설치합니다.
[root@serverb ~]#yum install sysstat ...output omitted.../usr/lib/systemd/system/sysstat-collect.timer를/etc/systemd/system/sysstat-collect.timer에 복사합니다.[root@serverb ~]#cp /usr/lib/systemd/system/sysstat-collect.timer \ /etc/systemd/system/sysstat-collect.timer타이머 장치가 1분마다 한 번씩 실행되도록
/etc/systemd/system/sysstat-collect.timer를 편집합니다.[root@serverb ~]#vim /etc/systemd/system/sysstat-collect.timer ...output omitted... # Activates activity collector once every minute [Unit] Description=Run system activity accounting tool once every minute [Timer] OnCalendar=*:00/01 [Install] WantedBy=sysstat.servicesystemctl daemon-reload 명령을 사용하여
systemd에 변경 사항을 알립니다.[root@serverb ~]#systemctl daemon-reloadsystemctl 명령을 사용하여
sysstat-collect.timer타이머 장치를 활성화합니다.[root@serverb ~]#systemctl enable --now sysstat-collect.timer
serverb에 Performance Co-Pilot 패키지를 설치하여 기본 시스템 수준 성능 모니터링과 추가 시스템 모니터링 툴을 제공하는 PCP 모듈을 지원합니다. 성능 지표 수집기 데몬을 활성화하고 시작합니다.pcp 및 pcp-system-tools 패키지를 설치합니다.
[root@serverb ~]#yum install pcp pcp-system-tools ...output omitted... Complete!Performance Co-Pilot 지표 수집기 데몬을 시작하고 활성화합니다.
[root@serverb ~]#systemctl enable --now pmcd ...output omitted...
serverb에서 실행되는 성능 지표 수집기 데몬에 대한 원격 액세스를 구성합니다.firewall-cmd 명령을 사용하여
pmcd서비스를 추가합니다.[root@serverb ~]#firewall-cmd --permanent --add-service="pmcd" success방화벽 구성을 다시 로드합니다.
[root@serverb ~]#firewall-cmd --reload success방화벽 구성을 확인합니다.
[root@serverb ~]#firewall-cmd --list-all public (active) target: default icmp-block-inversion: no interfaces: enp1s0 sources: services: cockpit dhcpv6-client pmcd ssh ports: protocols: masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:
serverb에서 Performance Co-Pilot을 통해mem.util.used지표 샘플 10개를 캡처합니다. 출력을/tmp/mem-util-used-grade.data로 리디렉션합니다.[root@serverb ~]# **pmval -s 10 mem.util.used > /tmp/mem-util-used-grade.data**serverb에서http://materials.example.com/labs/perftools-review/sampleserver.tgz의sampleserver.tgzPerformance Co-Pilot 로그 아카이브를 다운로드합니다. 경험한 최대 1분 부하 평균을 확인하고 이 값을/tmp/high-1min-load.data에 저장합니다. 작업을 마쳤으면 1분 부하 평균이 처음으로 해당 값에 도달한 시간을 확인하고 이 값을/tmp/time-1min-load.data에 저장합니다.샘플 시스템에 대한 Performance Co-Pilot 로그 데이터를 다운로드합니다.
[root@serverb ~]#wget \ http://materials.example.com/labs/perftools-review/sampleserver.tgz아카이브의 압축을 풀어 Performance Co-Pilot 로그 데이터에 액세스합니다.
[root@serverb ~]#tar -xf sampleserver.tgz1분 부하 평균을 제공하는 매개 변수를 확인합니다.
[root@serverb ~]#pminfo | grep load ...output omitted... kernel.all.load ...output omitted... [root@serverb ~]#pminfo -t kernel.all.load kernel.all.load [1, 5 and 15 minute load average]경험한 최대 1분 부하 평균을 확인합니다. 이 값을
/tmp/high-1min-load.data로 리디렉션합니다.[root@serverb ~]#pmval -a sampleserver.log/20150223.12.24.0 \ kernel.all.load | tail -n +11 | \ awk '{print $2}' | sort -rn | \ head -n 1 > /tmp/high-1min-load.data다음과 일치하는 내용이 있는지 확인합니다.
[root@serverb ~]#cat /tmp/high-1min-load.data 19.121분 부하 평균이
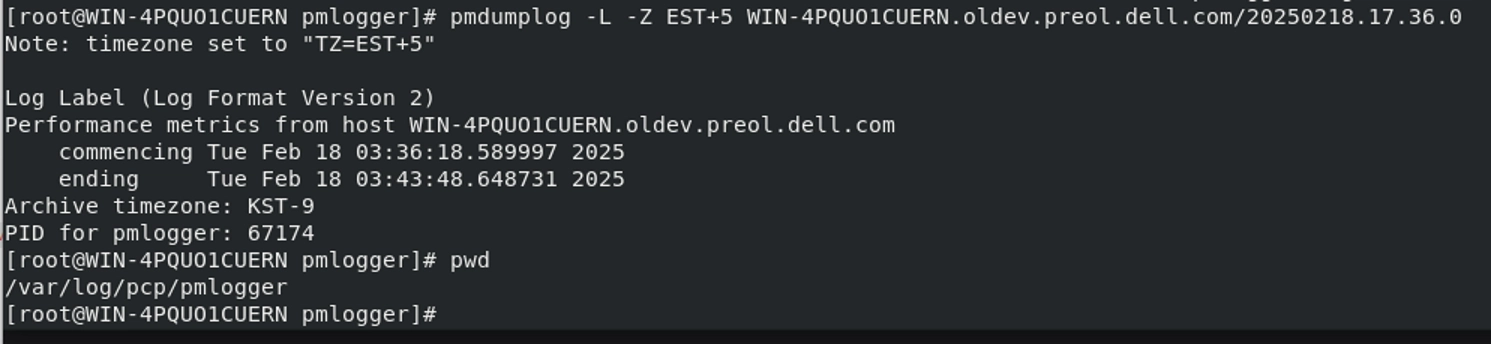
19.12에 처음으로 도달한 시간을 확인합니다. 이 값을/tmp/time-1min-load.data로 리디렉션합니다. 다양한 표준 시간대의 시스템에 시간값을 표시할 때 일관성을 유지하려면 아카이브의 표준 시간대를 알아야 합니다.[root@serverb ~]#pmdumplog -L sampleserver.log/20150223.12.24.0 Log Label (Log Format Version 2) Performance metrics from host server0.example.com commencing Mon Feb 23 11:24:41.562205 2015 ending Mon Feb 23 11:54:41.500123 2015 Archive timezone: EST+5 PID for pmlogger: 9217 [root@serverb ~]#pmval -a sampleserver.log/20150223.12.24.0 \ -Z EST+5 kernel.all.load | grep 19\.12 | \ head -n 1 > /tmp/time-1min-load.data다음과 일치하는 내용이 있는지 확인합니다.
[root@serverb ~]#cat /tmp/time-1min-load.data 12:32:41.562 19.12 5.060 1.860
serverb에서http://materials.example.com/labs/perftools-review/sar-server.data의 기존 sar 아카이브 파일을 다운로드합니다.~/sar-server.data에 기록된 대로enp1s0인터페이스에 대해 초당 받은 최대 네트워크 패킷 수를 확인합니다.HH:MM:SS Packets형식을 사용하여 패킷 수와 시간을/tmp/net-grade.data파일에 기록합니다.http://materials.example.com/labs/perftools-review/sar-server.data를/home/student로 다운로드합니다.[root@serverb ~]#wget \ http://materials.example.com/labs/perftools-review/sar-server.data ...output omitted...sar 명령을 사용하여 아카이브 파일의 처음 10줄을 읽고 형식을 식별합니다. (sar-server.data 는 바이너리 파일임)
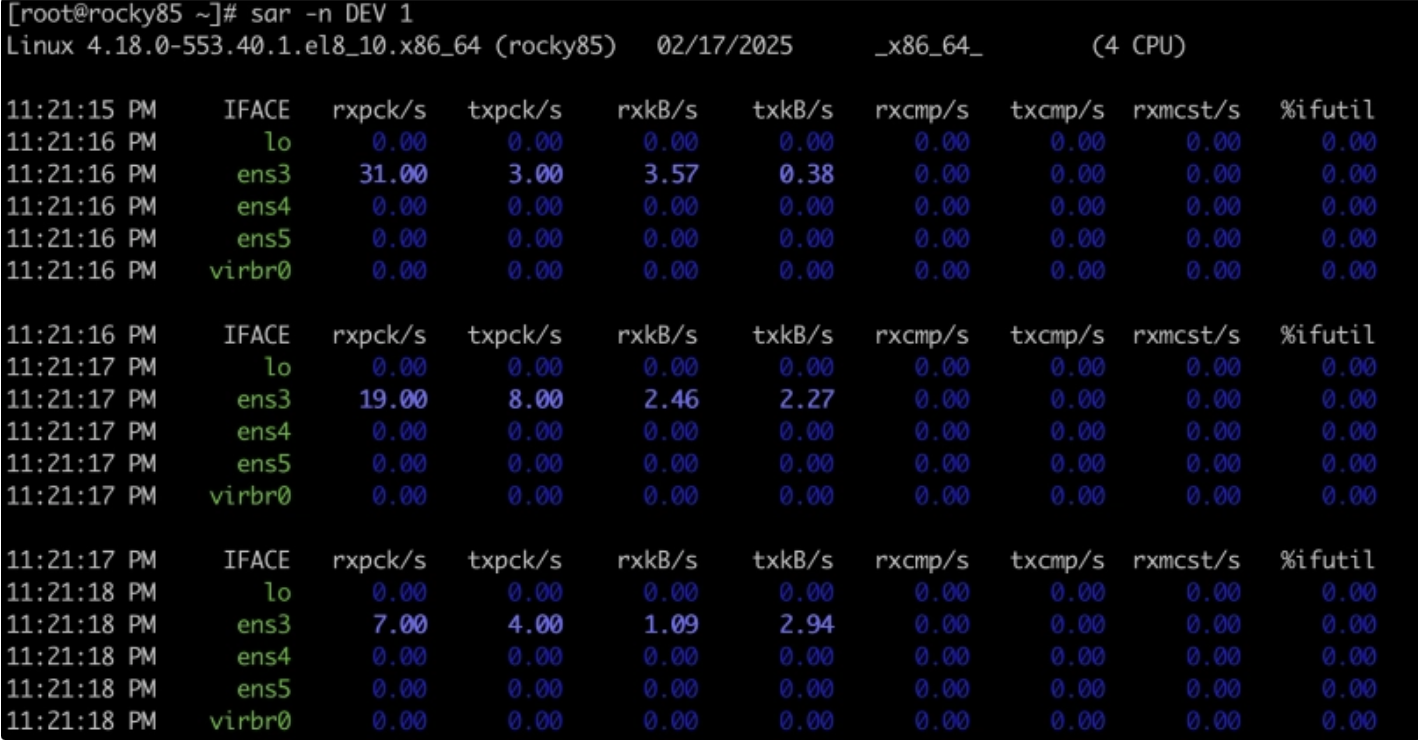
[root@serverb ~]#sar -n DEV -f sar-server.data | head Linux 4.18.0-80.el8.x86_64 (serverb.lab.example.com) 07/04/2019 _x86_64_ (2 CPU) 00:04:26 LINUX RESTART (2 CPU) 12:06:01 AM IFACE rxpck/s txpck/s ... %ifutil 12:07:01 AM lo 0.00 0.00 0.00 12:07:01 AM enp1s0 1.13 0.50 0.00 12:08:01 AM lo 0.00 0.00 0.00 12:08:01 AM enp1s0 0.62 0.12 0.00 12:09:01 AM lo 0.00 0.00 0.00다음 필터를 사용하여 시간 및 받은 패킷 값을 구문 분석합니다.
sar -n DEV -f sar-server.data는 기존 tar 파일의 네트워크 통계를 보고합니다.
grep '^[^A].*enp1s0'은
Average단어로 시작하는 줄과 같이 타임스탬프로 시작하지 않는 줄을 제거한 후에enp1s0과 관련된 줄만 격리합니다.awk '{print $1, $4}' | sort -rnk 2는 grep 명령을 통해 생성된 출력의 첫 번째 열과 세 번째 열을 출력하고, 3열에서 내림차순으로 숫자 정렬을 수행합니다.
head -n+1 > /tmp/net-grade.data는 정렬된 데이터의 첫째 줄을
/tmp/net-grade.data파일로 리디렉션합니다.[root@serverb ~]#sar -n DEV -f sar-server.data | \ grep '^[^A].*enp1s0' | \ awk '{print $1, $4}' | sort -rnk 2 | \ head -n+1 > /tmp/net-grade.data
결과가 다음과 일치하는지 확인합니다.
[root@serverb ~]#cat /tmp/net-grade.data 01:08:01 202.23serverb에서 로그아웃합니다.[root@serverb ~]#exit [student@serverb ~]$exit [student@workstation ~]$
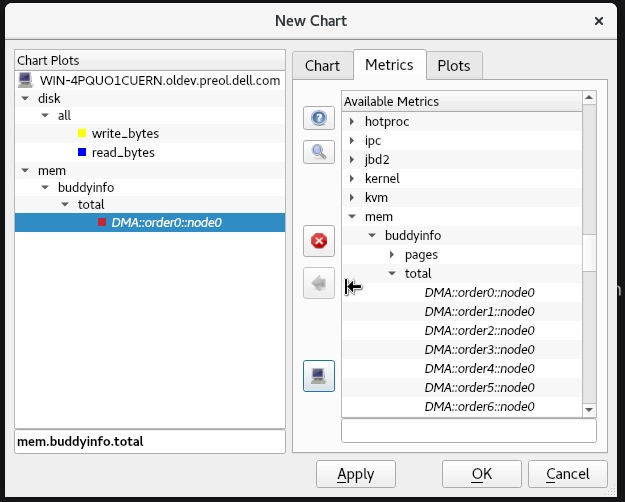
workstationVM에서 Performance Co-Pilot 차트를 사용하여mem.util.used,disk.all.aveq,proc.nprocs성능 지표가 포함된 원격 호스트serverb의 뷰를 생성합니다. 해당 뷰의 이름을442labview로 지정합니다.pmchart 인터페이스를 시작하여
serverb원격 호스트에 연결합니다.[student@workstation ~]$pmchart -h serverb &세 가지 성능 지표를 추가합니다.
New Chart(새 차트) 버튼을 클릭합니다. Metrics(지표) 탭에서 mem → util → used를 선택합니다. OK(확인) 버튼을 클릭합니다.
New Chart(새 차트) 버튼을 클릭합니다. Metrics(지표) 탭에서 disk → all → aveq를 선택합니다. OK(확인) 버튼을 클릭합니다.
New Chart(새 차트) 버튼을 클릭합니다. Metrics(지표) 탭에서 proc → nprocs를 선택합니다. OK(확인) 버튼을 클릭합니다.
뷰를
442labview로 저장합니다.File(파일) 메뉴를 열고 Save View(뷰 저장)...를 선택합니다.
Path(경로): 필드를
/home/student로 변경합니다.Filename(파일 이름): 필드에
442labview를 입력합니다.Save(저장) 버튼을 클릭합니다.
PCP 차트의 그래픽 인터페이스를 종료합니다.
File(파일) 메뉴를 열고 Quit(종료)를 선택합니다.
평가
workstation에서 lab perftools-review grade 명령을 실행하여 이 연습의 성공 상태를 확인합니다.
[student@workstation ~]$lab perftools-review grade완료
workstation에서 lab perftools-review finish 명령을 실행하여 이 연습을 완료합니다.
[student@workstation ~]$lab perftools-review finish'Performance Tuning > RH4424 연습문제' 카테고리의 다른 글
| 2장 - 연습 가이드: Performance Co-Pilot을 통한 성능 데이터 수집 (0) | 2026.03.02 |
|---|---|
| 2장 - 연습 가이드: sysstat 패키지 유틸리티 보기 (0) | 2026.03.02 |
| 2장 - 연습 가이드: 시스템 모니터링 툴 식별 (0) | 2026.03.02 |
| 1장 - 연습 가이드 : 컴퓨터 측정 단위 변환 (0) | 2026.03.02 |