[RH436/EX436] 13. 클러스터 로그 분석
* 클러스터 로깅 구성하기
클러스터 트러블슈팅시, 가장 유용한 자원은 시스템 로그이다. 클러스터 로그는 크게 corosync, pacemaker 두가지 로그가 있다.
* Corosync Logging
Corosync daemon log는 /var/log/cluster/corosync.log 에 저장된다. 그리고 syslog에도 저장된다. 그러므로 사용자는 또한journalctl 명령이나 /var/log/messages 에서도 로그를 볼 수 있다. 시스템 관리자는 Corosync 구성파일(/etc/corosync/corosync.conf) 에 있는 logging {} 블록 을 수정하여 로깅을 컨트롤할 수 있다.
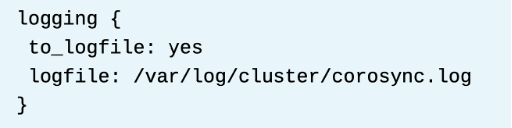
특정 파일에 corosync 로그를 기록하려면 to_logfile 이랑 logfile 경로를 logging {} 블록에 명시한다.
corosync는 또한 메시지를 stderr에 보낼 수 있다. 여기에서 systemd는 이러한 메시지를 수집하여 journald로 전달할 수 있다.

사용자는 corosync가 기록하는 메시지 로깅의 상세한 정도와 우선순위를 컨트롤할 수 있다. logging {} 블록에 syslog_priotiry, logfile_prority 세팅을 넣어서 이를 수행할 수 있다. 사용자는 두 파라미터에 다음 어떤 값도 사용할 수 있다. - emerg, alert, crit, err, wraning, notice, info, debug (높은 우선순위부터 낮은 우선순위로 정렬되어있음) 하나의 우선순위를 선택했을 때, corosync는 해당 우선순위보다 더 높은 우선순위의 메시지들을 로그파일에 포함한다. (즉 선택한 우선순위보다 낮은 우선순위 빼고 모두 로깅한다는것) 디폴트 로깅 우선순위는 info 이다. 또한 /etc/corosync/corosync.conf 파일에 있는 logging {} 블록안에 debug: 라인을 추가함으로써, 사용자는 모든 것에 대한 디버그 레벨 로깅을 강제할 수 있다.
한 노드에서 corosync 로깅 구성에 대한 변경을 진행한 후에는, 이러한 변경을 모든 노드에 배포하고 클러스터를 재시작해야한다. 변경사항을 배포하기 위해서, 구성파일 업데이트를 수행한 노드에서 pcs cluster sync 명령을 수행한다. 그러면, 각 노드에서 logging 변경사항을 활성화하기 위해 pcs cluster reload corosync 를 실행하게 된다. 그리고 전체 클러스터를 재시작하려면, pcs cluster stop --all 후pcs cluster start --all 을 하면 된다.
* corosync log file 리뷰하기
사용자는 corosync 가 생성한 여러 다른 메시지들을 보기 위해 로그 파일을 리뷰할 수 있다. 이 파일은 사용자가 제대로 클러스터를 셋업했는지를 verify하는데 도움을 준다. 가장 중요한 것으로, 이것은 또한 에러를 찾는데도 도움을 준다. 예를들어, corosync 로그 파일은 3노드 클러스터 구성에서 한 노드가 다운되면 아래와 같은 정보를 보여준다.

1. kronosnet 은 노드 1번이 다운되고, 또한 노드 1번은 활성화된 링크가 없는것을 리포트한다. [knet]
2. totem 프로토콜은 해당 노드로부터 정보를 받지 못했다. [totem]
3. CPG 서비스는 한 노드가 다운되었다고 메시지를 보낸다. [cpg]
4. 클러스터는 노드2,3의 쿼럼으로 유지되고 있다.
5. 클러스터는 활성화되어있는 노드2,3 에 서비스를 제공하도록 ready 상태이다.
* Pacemaker Logging
디폴트로, pacemaker 로그는 /var/log/pacemaker/pacemaker.log 에 저장된다. 그리고 "notice"와 그 이상의 레벨의 메시지만syslog에 저장된다. /etc/sysconfig/pacemaker 구성파일을 수정하여 로깅 옵션을 변경할 수 있다. Pacemaker 로깅할 대상 파일을 변경하려면 /etc/sysconfig/pacemaker 파일안에 PCMK_logfile 부분을 사용하여 pacemaker가 로깅에 사용할 파일을 변경할 수 있다.
디폴트로 pacemaker는 syslog에 로그를 로깅한다. 그러나 사용자는 PCMK_logfacility 옵션을 사용하여 특정 syslog 기능을 변경하거나, syslog 로깅하는것을 비활성화할 수 있다.
사용자는 구성파일 내에 PCMK_logpriority 세팅을 사용하여 pacemaker가 syslog에 기록하는 로그 우선순위를 컨트롤할 수 있다. 기본레벨은 info 이다. 시스템 관리자는 /etc/sysconfig/pacemaker에 있는 PCMK_debug=no 파라미터를 yes로 바꿈으로써 모든것에 대한 디버그 레벨 로깅으로 강제할 수 있다. PCMK_debug=yes 를 설정하면, 아래와 같이 debug 엔트리가 추가로 나오는것을 확인할 수 있다.

구성파일을 변경한 후에는, pacemaker.service를 재시작하여 변경사항을 적용한다. 클러스터 운영에 영향 없이 pacemaker를 재시작하려면, pacemaker.service를 재시작하기 전에 관리자는 한 노드를 standby모드로 변경하면 된다. 변경을 클러스터에 적용하려면전체 클러스터를 재시작해야 하며, 다음 명령어를 쓰면 된다. pcs cluster stop --all / pcs cluster start --all 을 수행하면 된다.
* 페이스메이커 로그 파일 리뷰하기
관리자는 클러스터에 의해 생성된 모든 메시지를 검토하기 위해 pacemaker 로그 파일을 리뷰할 수 있다. /var/log/pacemaker/pacemaker.log 파일은 수많은 클러스터 관련된 정보, 즉 product developers, redhat support team, advanced cluster administrators 에게 유용한 정보들이다. 반면에, pacemaker은 syslog에 중요한 메시지만 보낸다. 이것은journalctl -u pacemaker 또는 /var/log/messages 에 기록된다. 즉 pacemaker log 를 리뷰하기 위해 가장 좋은 절차는 grep을 사용하여 서로 다른 결과들을 필터해서 보는것이다. 아래 내용들은 전체 리스트를 의미하지는 않지만 관리자가 로그파일을 필터하는데 가장 중요한 기능들을 포함한다.
crm_update_peer_state_iter
클러스터 노드들의 상태에 대한 정보를 보여준다. 이 패턴을 grep으로 잡아 사용해서 노드가 언제 클러스터에서 연결을 잃었는지 검증할 수 있다.
crm_get_peer
각 노드의 노드 id를 보여준다. 이 패턴을 사용하여 이름에서 노드 id를 찾을 수 있다.
pcmk_cpg_membership
클러스터 멤버십에 댛나 정보를 보여준다. 이 패턴을 쓰면 노드의 서브시스템들이 클러스터에 조인하는것과 떠나는것을 모니터링할 수 있다.
pcmk_quorum_notification
쿼럼 상태를 보여준다. 이 패턴을 사용하여 언제 클러스터가 쿼럼을 업ㄷ었는지, 잃었는지, 유지하는지 볼 수 있다.
te_fence_node
펜스 요청에 대한 정보를 보여준다. 이 패턴을 사용하여 노드가 언제 펜스되었는지 알 수 있다.
tengine_stonith_notify
fencing operation의 상태에 대한 정보를 보여준다. 이 패턴을 사용하여 fencing agent가 성공적인지 확인할 수 있다.
determine_online_status_fencing
fence device의 상태를 보여준다. pcs stonith status 명령과 비슷한 정보를 제공한다.
#노트
journalctl을 사용하여, pacemaker와 corosync의 로그를 보려면 다음과 같이 한다.

* References
corosync.conf(5) man page
/etc/corosync/corosync.conf.example configuration file
/etc/sysconfig/pacemaker configuration file
Knowledgebase: "How do I configure logging for corosync in Red Hat Enterprise Linux (RHEL) 8 High Availability clusters?" https://access.redhat.com/solutions/5017511
* 로그 분석하기 예시
현재 아래와 같이 정상적으로 사용중이다.

현재 리소스는 nodea에 있으며, 내가 할때는 nodeb등에 있을 수 있음. 정상임.
네트워크 커뮤니케이션에 문제를 일으켜 노드a를 펜스시키자. 아래 스크립트를 사용한다.

다른노드에서 watch 로 펜싱 진행과 리소스가 리로케이션되는것을 확인한다. 그리고 현재 dc 노드가 누군지도 확인한다.

현재 nodeb가 dc노드로 보인다. 결과가 위와 다를 수 있음. (클러스터 정상 동작임) 현재 dc에서 nodea가 클러스터와의 통신을 언제 잃었는지 로그를 확인한다. 또한 클러스터가 해당 노드를 펜스한것도 확인한다. 현재 dc에서, /var/log/pacemaker/pacemaker.log 를 열고 거기서 crm_update_peer_state_iter 로 검색한다. 이 구문은 클러스터 멤버가 상태가 바뀌는 것을 보여준다. 해당 항목을 사용하여 을 사용하여 firstweb 리소스 그룹을 실행하던 노드와의 연결이 끊어진 시점을 확인한다.

현재 dc에서, /var/log/pacemaker/pacemaker.log 에서 te_fence_node 를 grep으로 검색해보자. 이 구문은 클러스터가 노드를 펜스하기 위해 수행한 시도들을 보여준다

현재 dc에서, 동일하게 tengine_stonith_notify 를 검색해보자. 이 구문은 irstweb 리소스 그룹을 가지고 실행중인 노드가 성공적으로 펜스되었는지를 확인할 수 있다.
